
























Data Annotation: Key Concepts, Challenges, and Alternatives

In this piece, let’s explore the world of data annotation. We’ll start with the basics: defining data annotation, speaking about different types of annotation and data labeling techniques, including a survey of industry options, and touching on some of the limits and challenges associated with this process. We’ll then explore the promise and possibilities that Simulated Data offers by removing the need to annotate images and video.
In This Article
First, let’s zoom out.
The concept of Computer Vision has existed since the 1970s. The ideas were exciting, but the necessary tech stack (algorithms, compute power, training data, etc.) could not bring the concept into reality. This changed in 2012 when a team from the University of Toronto entered the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). They presented a deep neural network called AlexNet that changed the landscape for artificial intelligence and computer vision projects. Since then, Computer Vision has exploded with the rapid development of new networks, more accessible compute resources and a better understanding of the data needed for network training. The pace of development in this space is only accelerating. But, there are still challenges in the field, particularly when it comes to data annotation and data labeling (terms that we will use interchangeably in this piece).
In modern computer vision, the most crucial bottleneck for teams is a lack of effective, scalable training data. Most computer vision production models are based around supervised machine learning models. Supervised models require labeled data in huge quantities. Traditionally, obtaining these datasets involve two main stages: data gathering and data annotation. Even though data is collected all the time by our phones, social media, cameras, and a myriad of other methods, there are many reasons why this data may not be sufficient or usable for computer vision training. So, teams spend a lot of time thinking about how they are gathering this data for it to meet the needs of their networks.
Since we’re focusing on data labeling here, let’s assume that a team has gathered the data they need to train their network. The next step is annotating the dataset. Essentially, data annotation is the process of adding information to data so that our model understands what the image contains and can make inferences accordingly. An example: if you are training a network to recognize hands in a variety of contexts, it is not enough to just show your network images that contain hands. These images also contain other things: backgrounds, other objects like phones or pets, and any number of other distractions. Your network isn’t “born” with the ability to tell these things apart – that’s why you’re training it. It doesn’t know what’s a hand and what’s a dog unless you show it. So, your training data needs to identify which part of each image contains a hand. Only with this information – added via data annotation – can the network begin to learn. With enough annotations, the model begins to build its own rules for what a hand looks like. And it starts to make guesses. The model then compares its prediction to the annotations and makes adjustments to produce better future predictions. This is followed by more “learning” and then testing to make sure your model is hitting the metrics you have set. Soon, your model can recognize hands in other, unlabeled images.
There are different data labeling methods of varying sophistication that are used to add the necessary information to gathered data. At the end of the day, the goal of the data annotation is to achieve perfect Ground Truth – where the annotation you’ve added perfectly matches the reality (for instance, your hand annotation doesn’t accidentally miss thumbs or accidentally identify dogs as hands as well). While data annotation can be performed on text, audio, images, or video, we’ll focus on Computer Vision Applications, which rely on the annotation of visual data. After discussing the various approaches, we’ll help you understand which one might be right for your model and then how to actually get the annotation done.
Types of Classification and Segmentation
Image annotation is accomplished by several different methods, that lead to different results and labels for the images. The type of annotation is the result we want to achieve for our data, while the technique is how we accomplish that label. For example, the technique might be to draw a box around a cat, which leads to that part of the image to be labeled as “Cat”. The technique is drawing what we call a bounding box, and the result is classifying the selected part of the image as “Cat”. Some techniques are better suited for different types of annotation.

1. Image classification – This is the most basic type of data annotation. Its purpose is to train a model to recognize the existence of an object across images with simple tagging. This is a simple binary – for instance, does the image contain a cat or not? This is a high-level form of annotation as it applies to the entire image. The classification can be broad as well – for instance, does the image contain an animal, whether a cat, a dog, or a duck. Obviously, this is a very limited method – it oversimplifies an image into one label, thereby missing nuance and detail that is crucial in understanding the true nature of an image. Real-life scenes rarely contain only one object. It can teach a model how to answer a question – does the image contain a cat or not? – but not how to identify where the cat is located within the image itself.
2. Object Detection – Object detection aims to identify the presence, location, and the number of one or more objects in an image and correctly label them. This process can train a model to recognize objects in unlabeled images, and also locate them and count them. Different annotations techniques can be used in conjunction to help object detection within a single image. Object detection helps us define what is in the image, and where it is. But, it doesn’t clearly define either the shape or size of the objects. One challenge of this approach is that it may be able to locate a cat in a frame as long as the cat is posed a certain way that was captured in the training data. But, for instance, if the cat is stretching, jumping, or facing away from the camera, the model may struggle.
3. Segmentation – Image segmentation is a more sophisticated type of data labeling. It means dividing our image into various parts, called segments. By dividing the image into segments, we can gain a far deeper understanding of what is happening in the image and how various objects are related.
Read our survey on Synthetic Data: The Key to Production AI in 2022
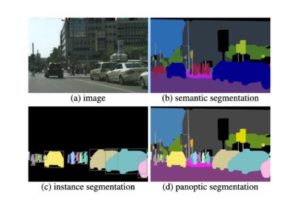
There are three types of image segmentation:
- Semantic Segmentation, also known as Class Segmentation, differentiates between different object classes and assigns the same label to each member of the object class. For instance, in a picture of a street, this data annotation may label all the humans in red and all the cars in blue, but it doesn’t help you distinguish each specific human or car. This type of segmentation is great at grouping objects and is good at helping us understand the presence and location of objects. But, if you need to count or track objects, this method won’t be very helpful.
- Instance Segmentation tracks and computes the shape, size, location, and count of objects in an image. Not only does this classify the objects but it differentiates between instances of the object and enables us to count the objects of a particular class. Each human and car in the image is assigned a different color, but the parts of the picture that aren’t classified don’t get any focus and the background just disappears.
Panoptic Segmentation unifies the different tasks of semantic segmentation (assigning a class label to each pixel) and instance segmentation (detecting and segmenting each object instance). This is the most detailed form of segmentation, as it combines the other two forms of segmentation to create a highly granular and detailed representation of the real image.
Which Type of Data Annotation Is Right For Me?
Teams must decide what type of data annotation is right for their application. This is an important question because data labeling can be expensive and time-consuming, but it is critical to the model’s success. So, teams are stuck with an often complicated cost-benefit analysis when it comes time to annotate their data. While it might be tempting to settle for image classification – it’s probably the cheapest and easiest to achieve – its applications are very limited. If we think about an autonomous vehicle computer vision model looking out onto a complex urban environment, we begin to see that just recognizing whether there is a human in its sight or not will not be enough. To avoid running the person over, the car also needs to know where the human is. If we take a medical computer vision application – identifying the shape of cancerous cells, we need instance segmentation, to differentiate between different instances of cells. Defining the whole image as “cells” won’t help us localize the problematic cells or to understand the extent of any problems.
But there are many cases where it’s not obvious what type of data annotation you need. This is a high-risk decision for teams. If they use the wrong annotation method or add the wrong information to their images, their model may not work and they’ll need to start the data labeling process anew. Simulated Data can relieve a lot of the stress associated with this type of decision by automatically and flexibly adding a wider range of annotations with perfect ground truth, but more on this later.
Annotation Techniques: Even More Choices
Once you’ve chosen your annotation method, there are even more choices to make; now you have to select an annotation technique. This is the actual method that annotators will use to attach annotations to your data. For instance, they may draw squares around objects, do multi-sided polygons, or attach landmarks. It is important to understand these techniques because, again, there is often a tradeoff between cost, time, and effectiveness.
- Bounding Boxes – The most basic type of data annotation. It consists of drawing a rectangle or square around the target object and is very commonly used, due to its simplicity and versatility. This is useful when objects are relatively symmetrical – such as boxes of foods or road signs – or when the exact shape of the object is of less interest. On the other hand, complex objects don’t have right angles, and achieving ground truth annotation using bounding boxes is impossible. Additionally, we have no annotations for what’s happening “inside” the box. For instance, if we care about a person’s movement, posture, gait, or other dynamic indicators, bounding boxes are unlikely to be helpful.
- Polygonal Segmentation – a variation of the bounding box technique. By using complex shapes (polygons) and not only the right angles of bounding boxes, the target object’s location, and boundaries are defined more accurately. Increased accuracy cuts out irrelevant pixels that can confuse the classifier. This is good for more irregular shaped objects – cars, people, and logos, animals. While polygons are more accurate than bounding boxes, overlapping objects may be captured within a single polygon and therefore not distinguishable from each other.
- Polylines – this plots continuous lines made of one or more segments. It is best used when important features have a linear appearance. This is common in an autonomous vehicle context, as it is easily applied to define lanes and sidewalks. But, for most use cases this simply isn’t relevant because the object is not linear and more than a single pixel wide.
- Landmarking – This is also known as dot annotation. It involves creating dots across the image. These small dots help detect and quantify characteristics in the data. It is used often in facial recognition to detect facial features, emotions, and expressions. It can be used to help annotate human bodies, align posture, and explore the relationship between different body parts. Another interesting use case is to find objects of interest in aerial footage such as cars, buildings, and more. Clearly, this approach is both time consuming and prone to inaccuracy. For instance, manually landmarking facial features like irises across thousands of images is very difficult to do consistently and accurately.
- Tracking – This is a data labeling technique used to plot an object’s movement across multiple frames. Some tools include interpolation, which enables the annotator to label one frame, skip frames, and then annotate the new position. The annotating tools automatically fill in the movement and track the objects through the frames. While this is great theoretically, it takes a lot of work and high levels of accuracy to successfully annotate. In general, the cost of annotating video data quickly becomes cost prohibitive because of the need to annotate frame-by-frame.
Often, your use case will dictate the technique that’s right for you. But, even if you have little choice in which technique to adopt, it is critical to be aware of the constraints of each one. Expensive techniques may limit the amount of data you want to collect. While techniques with inherent variation may force you to pay extra attention to the effects of minor inconsistencies on your model’s performance.
Getting the Annotation Done
Now, you’ve gathered your data and decided on the method and techniques of data annotation that work best for your model. It’s time to get the annotations added to your images. This annotating process involves people sitting, and manually marking image after image. Ideally, you might be assisted by some automation tools, but in general, it is a manual and labor-intensive process. To give a sense of the scale of manual labor involved, MBH, a Chinese data-labeling company, employs 300,000 data labelers across China. Each labeler works a six-hour shift each day, annotating a conveyor belt of images.
In today’s annotation landscape, there are a couple of different solutions available to you:
- Crowdsourcing – Crowdsourcing involves paying workers – often distributed globally and working as freelancers – to perform a micro-task or assignment. They are generally paid a small sum based on the volume of work they complete. A prime example of this solution is Amazon Mturk. The Mturk platform enables you to create tasks and pay workers to complete the tasks and get paid per assignment. While this might be an easy way to source the labor, it forces you to accurately define the assignment, define worker requirements, and payment levels. Additionally, each employer has a rating, and employers with a low rating risk workers not wanting to work on the tasks you publish Crowdsourced labor tends to be of low quality and consistency for obvious reasons. The workers are lightly vetted or may have little idea of what they are doing or common pitfalls. The burden of managing them falls on you. There are also platforms that crowdsource work but manage the workflow and sourcing of workers. Appen, for example, has over 1,000,000 remote workers manually labeling data. Additionally, quality assurance post labeling requires resources and validation and without it is impossible to guarantee high-quality results. Because these tend to be one-off relationships, there is no feedback loop with the people working on your project and there is no way to train them over time. Data security is also a challenge as these people are often working independently on unsecured computers.
- In-House Solutions – Some companies choose to try and solve data annotation needs in-house. For small, easy-to-annotate datasets, this may be a great option. But, many companies often assign this low-level work to their data scientists and engineers, which is not a good use of their time. The alternative of hiring annotators in-house – which brings benefits of process control and QA – carries significant overhead costs. Generally, this method is not scalable, as you invest in hiring, managing, and training employees while your data needs may fluctuate wildly over time. Teams that try to automate these processes or build in-house tech solutions often find themselves distracting valuable development teams with projects that would be more efficient to outsource.
- Outsourcing – There are many data labeling companies – often based in low-cost markets like India – that employee teams focused on data annotation. Some suppliers leverage certain ML models to accelerate the process and do QA. By virtue of employing the annotators, these companies are better able to control quality, can improve quality over time as they learn about your specific needs, and can provide better time estimates than the other options. But, ultimately this is still a manual process and any cost-savings come from the cheap cost of labor. You still have to devote operational resources to managing this relationship and, at the end of the day, you are still dependent on a third-party vendor that is subject to all kinds of delays, inconsistencies, and challenges.
As you can see, all of these options have significant operational, quality control, and process challenges. They generally force you to devote time and energy to things outside your core technological mandate.
Additionally, regardless of which manual data annotation approach you take, there are some inherent challenges and limitations, which make this process even more painful.
-
- 3D Image Data – Depending on the type of annotation and technique you need to employ, annotating 3D data may be nearly impossible. For instance, creating a manually annotated 3D depth map is hypothetically possible but not all practical. It requires capturing images from numerous angles, annotating each one, and aligning them. This requires consistency that is impossible to achieve manually. Yet, many high-level tasks in the real world require this knowledge of objects present in the scene, their physical locations, and the underlying physics to understand the scene. For example, an indoor robot needs depth maps to be able to appropriately arrange items in their spot. Depth maps are required to train robots to fit or insert objects precisely into other objects. A robot must understand how the floor bends or curves to adjust its path while navigating. This can not be added manually by even a highly-trained annotator.
- Physics – Different physical interactions like pressures, forces, acceleration, and velocity can only be annotated through mathematical simulations. Manually pressure data to a video is simply impossible by hand.
- Video – The dynamic nature of video data makes frame by frame labeling necessary but inefficient. The need for consistent and accurate labeling through numerous frames is very time-consuming, difficult, and expensive.
- Occlusions – In many real-world scenes, objects or people are occluded at least partly by other objects. Partially occluded objects are harder to detect and annotate accurately. Imagine a crowded street with numerous pedestrians or an image of the hand where fingers overlap and block each other. Manual annotators may have to assume the location of things they can’t see or may miss occluded items entirely if the photo was captured at the wrong time.
All of this is to say: high-quality data labeling requires many choices and takes time. Time is money. Researchers at Google calculated that annotating an image from the COCO dataset takes an average of 19 minutes, and fully annotating a single image from the Cityscapes dataset took 1.5 hours. That’s not even for the sophisticated segmentation methods. Annotating a full dataset can easily take 15,000 hours of labor. This is, of course, assuming you can even capture the data that you are looking for. The cost of human labor rapidly adds up, even when you’re paying for a solution that doesn’t fully meet your needs.

Read our survey on Synthetic Data: The Key to Production AI in 2022
A Welcome Alternative
What if things didn’t need to be this way? What if annotation was built into the data gathering process. No more outsourcing, crowdsourcing, or waste of internal resources. In fact, what if annotation could happen without manual annotators at all? Simulated Data provides a solution.
————-
Simulated data handles data annotation differently, in ways that address many of the limitations of manual annotation.
Simulated data is created using 3D simulations that provide full transparency and awareness. In other words, we start with full awareness of every object inside the simulation and its location. So, at the beginning of the simulation process, we already have a leg up on traditional annotation approaches because there is no guess about the exact orientation, location, and number of objects in a scene.
With that knowledge, providing annotation about simulated data requires configuring the automated systems that can generate additional layers of data (annotations) with no manual inputs required. These automations are integrated closely with our generation engines so that data generation and data annotation can occur simultaneously. This unique approach takes different forms depending on the type of simulation we’re creating and the types of annotations our customers need. So, let’s explore some examples of how this works in order to demonstrate the inherent advantages of providing annotations via data simulation.
- Consistency and Accuracy in Skeletal Tracking: Numerous computer vision applications require datasets of human hands and often benefit from skeletal tracking annotation (where joints are located). Traditionally, annotating skeletal trackers is challenging: some fingers obscure others, and annotating and placing these points correctly can be challenging and involve guesswork. In contrast, our simulated hands utilize a skeletal rig that offers perfect ground-truth and remains consistent across millions of simulations. Locating these skeletal landmarks simply requires querying and providing the location of this rig’s joints within the simulated space – no human guesswork required. Although the textures and skin might change, we always know exactly where each joint and knuckle is throughout every image and video.
- Depth Maps in Indoor Environments: There are also types of data annotations that manual data simply cannot supply. Depth Maps are a prime example. With simulated data, we can use Path Tracing to provide accurate readouts of the location of every object within a simulation. In this method, we simulate light rays emitted from the location of the camera and then track them as they bounce around the image and create realistic lighting and shading. Observing this lighting and shading allows us to automatically calculate the depth of different objects in the scene. If we want segmentation, we can define the parameters according to RGB values or other metrics. We can segment according to object, or according to the material that the object is made of.

- Eye Complexity: There are different reasons why a company would need datasets of eyes. In the field of advertising, eye tracking is seen as a key attention metric and companies are heavily investing in eye-tracking technology. For Health and medicine, research by students at UCSD shows that eye-tracking technology holds promise as an objective methodology for characterizing the early features of autism because it can be implemented with virtually any age or functioning level. VR headset companies are making huge investments in eye-tracking technology to improve the immersive experience they offer while saving processing power. Manually collecting this data is challenging enough, and the complex annotations needed for complex applications are nearly impossible to create manually. Simulated data enables you to track gaze direction with perfect ground truth. Specifically, because we have full control of the eye and understanding of its orientation, we use the visual and optical axis of the eye using complex physics-based annotations to calculate movements in the fovea. With synthetic eyes, you can get not only RGB data, but also infrared data, depth maps, segmentation maps, and details like the exact eye gaze direction or the various refraction parameters on and around the eye.

On the highest level, Simulated Data replaces both manual collecting and manual annotation with a single, integrated process. By simulating the world in 3D, it is possible to render the visual data and generate the annotations simultaneously – completely removing human based processes. We set the parameters that create the data and therefore can work together with our partners to make sure that the datasets we provide are tailor-made with all the information they need to achieve their goals.
As we have seen throughout this article, data annotation is a hugely time-consuming and therefore expensive process. But, Simulated Data offers an attractive and powerful alternative. Exactly how it looks and what it can achieve will differ by application. In the future, we’ll dig deeper into specific applications and how Simulated Data works. In the meantime, we invite you to reach out to learn more about how Simulated Data can eliminate the need for manual data labeling for your specific application.
Read our survey on Synthetic Data: The Key to Production AI in 2022
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
