
























Foundation Models – A New Paradigm of AI

This is part 1 of a series of blogs on Foundation Models and their impact on AI.
Have you seen an astronaut riding a horse in space? Probably not, but DALL·E 2–OpenAI’s AI that creates images from natural language–has an idea (Figure 1).

Figure 1. DALL·E 2’s response to the prompt of “an astronaut riding a horse in a photorealistic style” (Source)
DALL·E 2 is an example of a foundation model that has taken the AI community by storm in recent years. Foundation models are trained on a huge amount of unlabeled data and can perform different tasks without being explicitly trained on them. Other examples include GPT-3, BERT, and DALL·E. Given a short natural language prompt, these foundation models can perform tasks like answering questions, writing an essay, or generating an image like DALL·E 2 could.
The size of foundation models is ballooning as time passes. One of the earliest foundation models, BERT-Large (2018) has 340 million parameters. The largest foundation model today, the Megatron-Turing NLG 530B, has 530 billion parameters. (Figure 2)
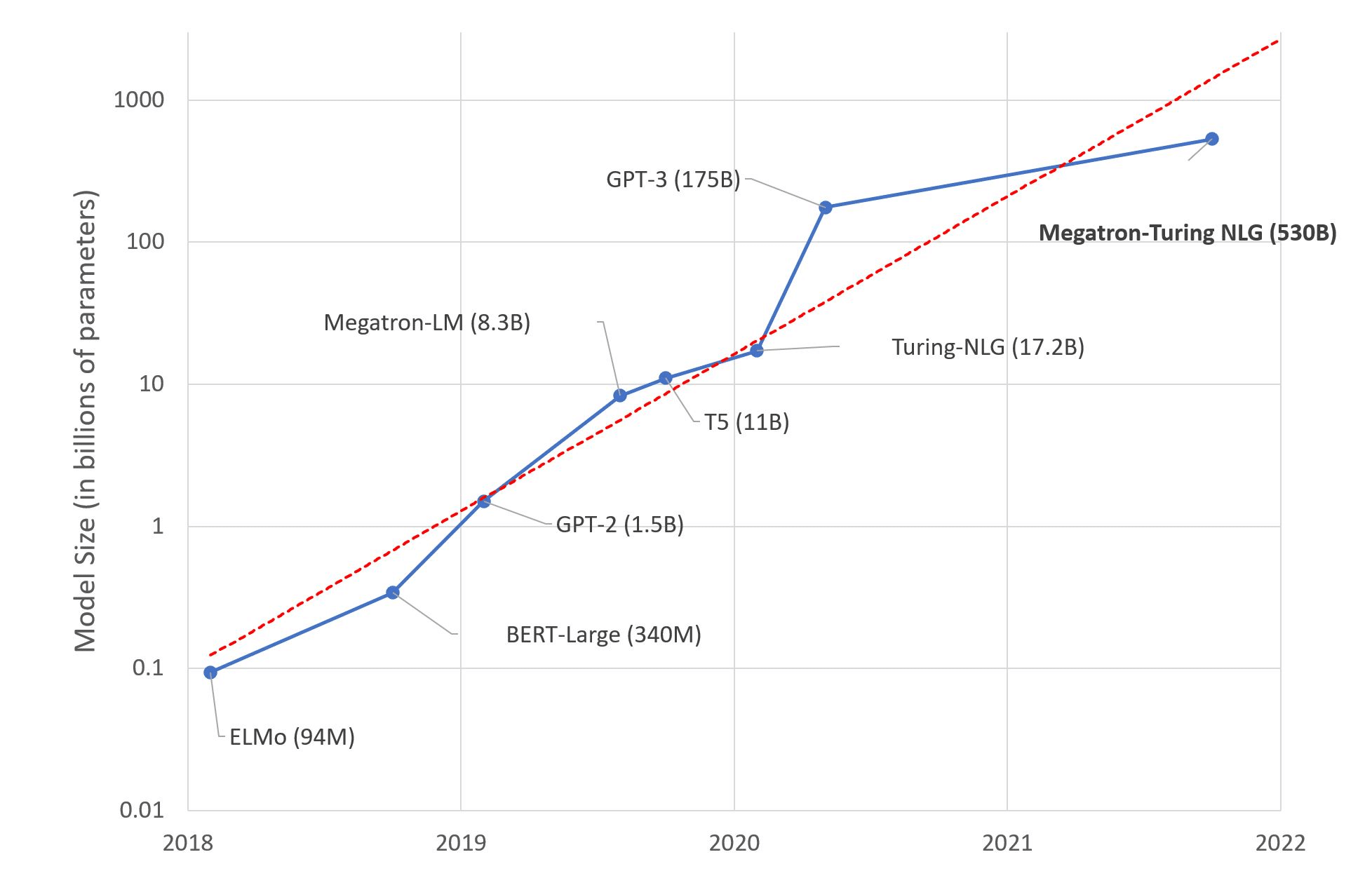
Figure 2. Foundation models and their sizes (Source)
The Rise of Foundation Models
The rise of foundation models is attributable to the oft-repeated mantra of “bigger is better” in machine learning. This intuition is backed by studies that show that model performance scales with the amount of compute, making it a consistent method in advancing the state-of-the-art. OpenAI reported that the amount of compute used in training the largest AI doubles every 3.4 months, outpacing Moore’s Law. AlphaGo Zero (2018) spent some 300,000x more compute than Alexnet (2012), a strong testament to the race toward ever-larger models. (Figure 3)
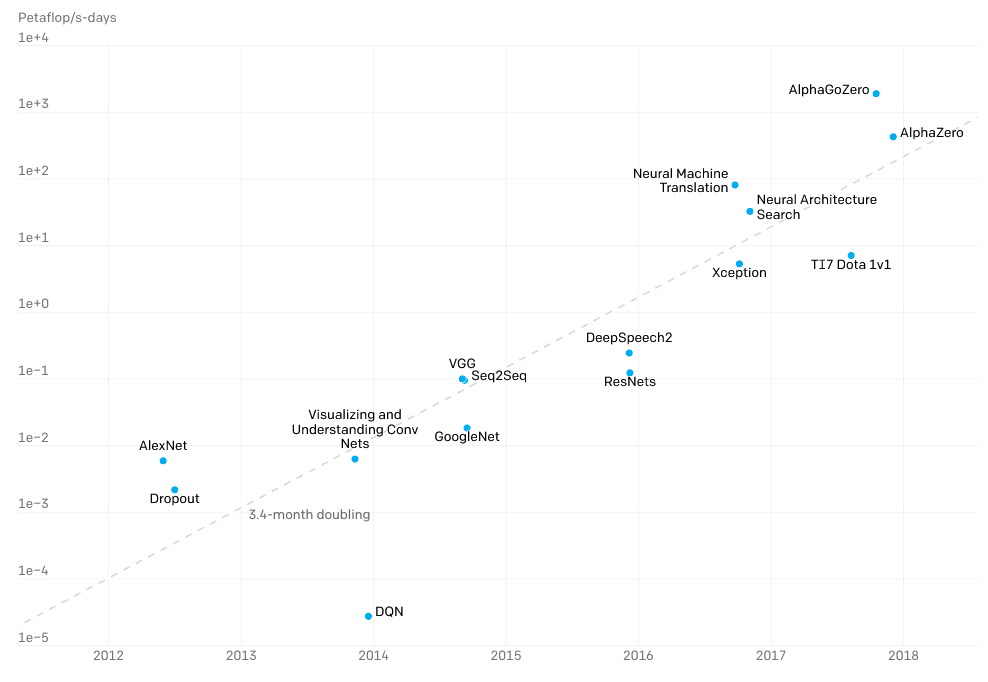
Figure 3. The amount of compute consumed by the largest models over the years (Source)
The mantra that ‘bigger is better’ goes hand-in-hand with the rapid innovation of model architecture and hardware, an explosion of data, and the high availability of compute in catalyzing the growth of neural networks. As the development of more powerful hardware pushes the boundary of parallelism, model training becomes quicker and more efficient. AI’s increasingly voracious appetite for data is met with the tremendous growth of data volume.
Simultaneously, deep-pocketed governments and corporations generously funded AI research that yielded sophisticated machine learning algorithms. In particular, the popularization of self-supervised learning significantly reduced the amount of labeled data, which is often expensive and unscalable. In the realm of NLP, self-supervised learning produced autoregressive language models, like GPT, ELMo, and ULMFiT. Shortly after, the industry embraced the Transformer architecture that incorporated bidirectional encoders of sentences, ushering in the era of foundation models, such as BERT, GPT-2, RoBERTa, and T5.
Here, we illustrate the capability of foundation models with a few notable examples.
BERT: An early foundation model
The advent of BERT was a significant milestone for the NLP community. A transformer-based model, BERT is a marked departure from the former forerunners of NLP architectures like recurrent neural networks (RNN).
Unlike directional models like ELMo and ULMFit which read texts sequentially, BERT is bidirectional. Instead of contextualizing each word using the words to adjacent words, BERT understands the context using the entire sequence before making predictions. Further, BERT is also unsupervised as it is trained only on an unlabelled plain text corpus.
Its ability to perform multiple NLP tasks without being explicitly trained to do so was surprising to many practitioners. In the seminal paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, Google researchers achieved state-of-the-art results on 11 natural language processing tasks without significant changes to the architecture.
Among other things, BERT was able to achieve at these NLP tasks:
- Answering questions
- Producing summaries
- Predicting sentences
- Translating texts
- Classifying sentiments
CLIP: Linking Natural Language with Visual Concepts
CLIP is a neural network that efficiently learns visual concepts from natural language supervision. CLIP can perform visual classification tasks when given the visual categories to be recognized. Since no domain-specific data is required, CLIP demonstrates zero-shot capabilities.
CLIP addresses a key problem in the realm of computer vision: models that perform well on benchmarks might give poor results on stress tests. In particular, researchers found that Neural Networks Are Easily Fooled by Strange Poses of Familiar Objects and that imageNet-trained CNNs Are Biased Towards Texture.
Optimized for the benchmark’s performance, neural networks before CLIP memorize patterns in the dataset but could not perform well outside of the benchmark. This is akin to passing an exam by studying only the questions on past years’ exams.
Conversely, CLIP is trained on 400 million image-text pairs collected from the internet, not just on the benchmark dataset. Yet, it is still able to perform well on multiple benchmarks like ImageNet (Figure 4).
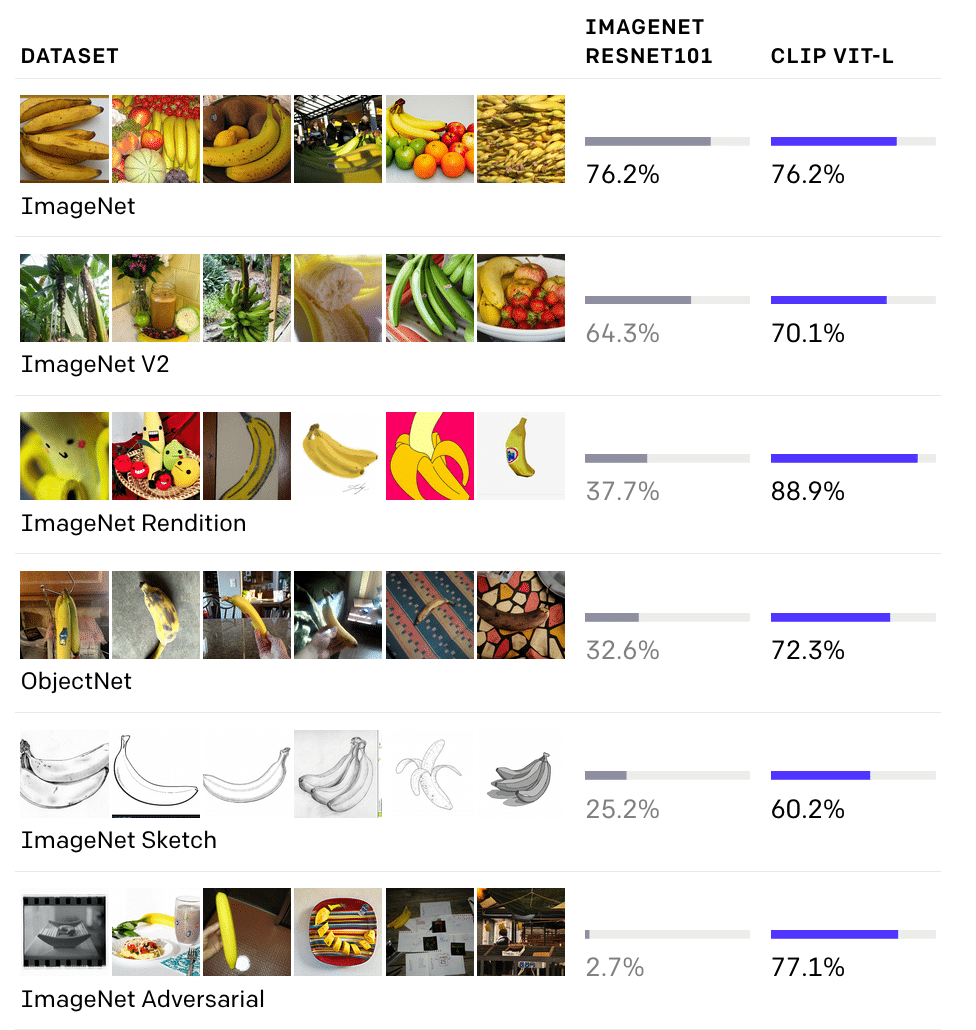
Figure 4. CLIP outperforms ImageNet on several benchmarks (Source)
This makes CLIP much more flexible than existing ImageNet models. It performed well on fine-grained object classification, geo-localization, action recognition in videos, and OCR.
That said, CLIP still struggled with images not covered in its pre-training dataset. It could also be sensitive to phrasing.
Read our Benchmark on Leveraging Synthetic Data for Hands-on-Wheel Detection
GPT-3
OpenAI released GPT-3 shortly after BERT made headlines. Boasting 175 billion parameters, GPT-3 is enormous compared to its predecessors. Like its cousins, GPT-3 can perform tasks that it is not explicitly trained on. Specifically, it was able to write long prose that resembles the work of a human. The release of GPT-3 (and models derived from GPT-3) significantly pushed the boundaries of NLP.
Codex – a descendant of GPT-3
Several versions of GPT-3 were released to different ends. One such example is Codex.
Trained on both natural language and billions of lines of source codes, Codex can produce working code based on a natural language prompt. Programmers marvel with envy at GPT-3’s versatility, as demonstrated in its ability to code in a dozen languages, including Python, JavaScript, Go, Perl, PHP, Ruby, and even Shell.
Codex was evaluated on HumanEval, which measures the correctness of a program synthesized based on a docstring. Impressively, Codex was able to solve 70.2% of the problems if it was given 100 samples per problem.
Today, Codex powers Github Copilot, a tool that gives suggestions for whole lines or entire functions inside a programmer’s editor (Figure 5). Codex is still available in private beta.
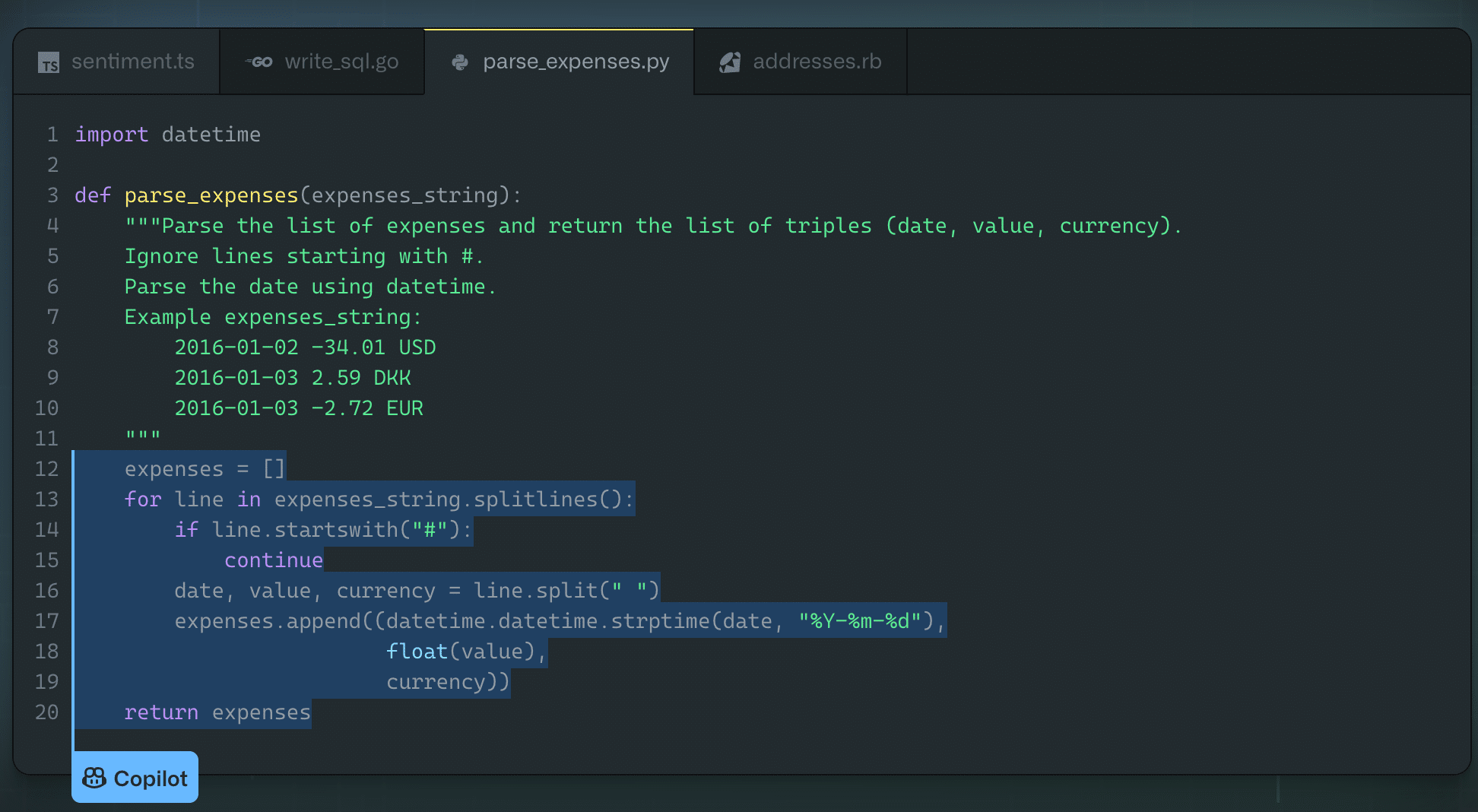
Figure 5. Codex in action (Source)
DALL·E
Another version of GPT-3 is DALL·E, a 12-billion parameter version of GPT-3 which generates images from text descriptions. DALL·E was groundbreaking at its inception. While predecessors were trained on a domain-specific labeled dataset, DALL·E generated high-fidelity images with zero-shot learning.
Trained using a dataset of text-image pairs, DALL·E demonstrated surprising capabilities. Dall·E could create delightfully fantastical images that combine unrelated concepts. Given the prompt “an armchair in the shape of an avocado”, DALL·E designed these practical yet sumptuous-looking chairs. (Figure 6)

Figure 6. A true AI armchair (Source)
Dall·E could also render text (Figure 7), transform images (Figure 8), and even create anthropomorphized images of animals and objects (Figure 9).

Figure 7 (Source)

Figure 8 (Source)

Figure 9 (Source)
DALL·E 2
DALL·E 2 comes a year after DALL·E was released. Like its predecessor, DALL·E 2 could produce original and realistic images from a text description (Figure 10). It could combine concepts, attributes, and styles with surprising fidelity.

Figure 10. Images generated by DALL·E (left) and DALL·E 2 (right) on the prompt “a painting of a fox sitting in a field at sunrise in the style of Claude Monet” (Source)
DALL·E 2 is preferred over its predecessor because it could generate more realistic and accurate images at four times the resolution. Concretely, when asked to evaluate the synthetic images for photorealism, 88.8% of evaluators preferred DALL·E 2 over DALL·E.
Given a natural language prompt, it could also edit existing images. Like a professional photo editor, DALL·E 2 accounts for shadows, reflections, and textures in this process. (Figure 11)

Figure 11. DALL·E 2 could also transform the styles of an image while remaining faithful to the original content. (Source)
To understand how DALL·E 2 translates a prompt into an image, we need to delve a little deeper into its architecture. First, a text prompt is provided as an input into a text encoder, which maps a prompt into a text encoding in the latent representation space. Later, the text encoding is transformed into an image encoding that captures the semantic information of the prompt by a model called prior. An image decoding model then generates an image based on the image encoding (Figure 12).
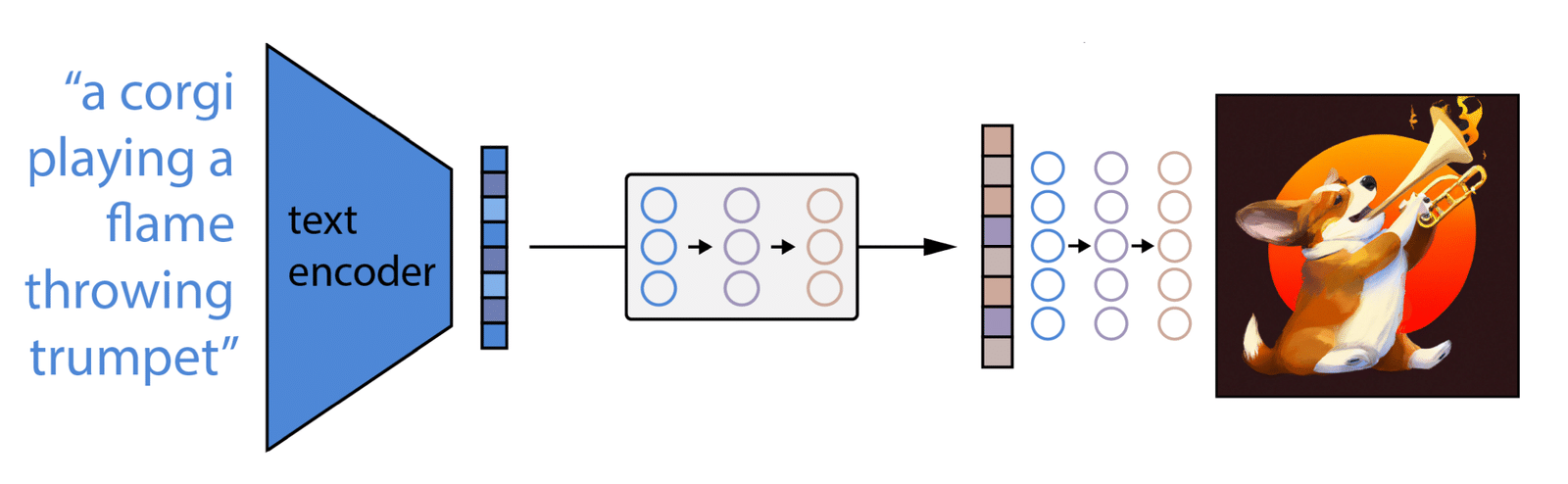
Figure 12. DALL·E 2’s general architecture (Source)
DALL·E 2’s photorealism has far-reaching implications. With the ability to create and edit images on the fly, DALL·E 2 can empower people to express their creativity. Yet, that could also mean adversaries could more easily spin fantastical tales and sway public opinion using fake images. That is why DALL·E 2’s API remains restricted today.
In the next blog, we’ll take on the opportunities and the risks of foundation models.
Read our Benchmark on Leveraging Synthetic Data for Hands-on-Wheel Detection
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
