
























ML System Development Takes More Than ML Modeling

As artificial intelligence (AI) becomes increasingly ubiquitous, companies are flocking to implement AI in their products and services. From providing recommendations to discovering drugs, the potential of AI is vast. Yet, many organizations fail to deploy AI at scale and realize such potential.
In fact, 69.5% of companies named artificial intelligence AI the most impactful and disruptive technology in 2020, but only 14.6% of them managed to deploy AI capabilities into widespread production, according to a survey by New Vantage Partners. In a separate report by Wall Street Journal, only 53% of AI proof-of-concept projects make it to production. Evidently, the desire of companies to extract value from AI projects does not translate to their ability to do so.
Why is that? One reason is that companies put machine learning (ML) modeling as a top priority while relegating other equally crucial tasks in developing a complete ML system. Unbeknownst to them, ML system development involves much more than just ML modeling. While building a good ML model is commendable, it is only the first step to developing an integrated ML system that continuously operates in production.
In fact, only a small fraction of real-world ML systems are composed of ML code and model, according to a Google paper ‘Hidden Technical Debt in Machine Learning Systems’.
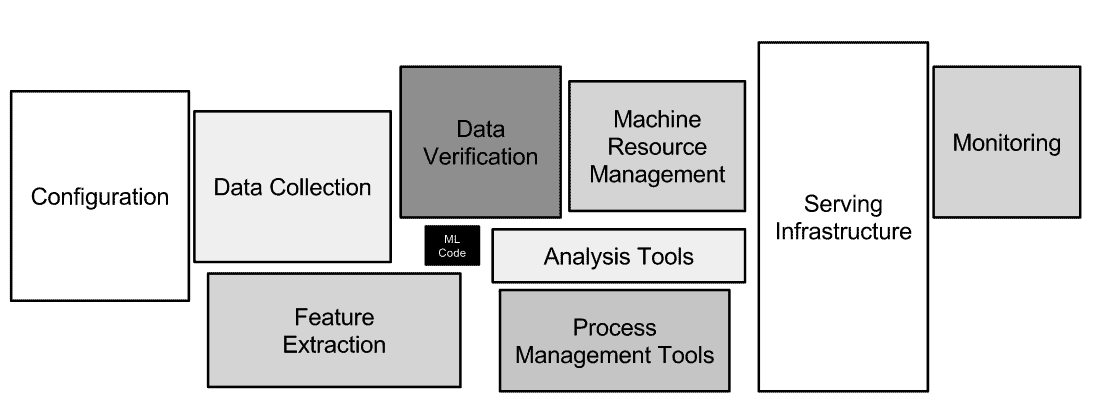
Figure 1: ML Code is but a small part of an ML system [Source]
Such complex infrastructure is necessary for a real-world machine learning system to scale robustly. Without such an infrastructure, it might not be able to react to changes in the data, model, and requirements easily, causing it to crash and burn in the real world.
Of course, operating a ML system is by no means trivial. Thus, the recent emergence of Machine Learning Operations (MLOps) aims to provide a framework for developing scalable and robust production-level machine learning systems. MLOps, as the name implies, is the machine learning engineering culture and practice that aims at unifying ML system development (Dev) and ML system operation (Ops). It aims to automate and monitor every step of an ML system, including integration, testing and deployment.
Here, we discuss how MLOps principles can help develop an ML System and put it to production.
Read our Survey on Sythetic Data: Key to Production-Ready AI in 2022
Steps of Delivering an ML Model to Production
An ML project starts with project scoping, where the business use case is determined, the success metric defined, and the technical feasibility of the ML solution determined.
After scoping, the following steps are taken to deliver an ML model from experiment to production, according to Google Cloud.

Figure 2: The 8 Steps of Delivering an ML Model to Production
- Data extraction: Machine learning models have a voracious appetite for data. Such data often needs to be extracted from multiple sources and might even involve generated synthetic data. Ideally, the data is validated after extraction to ensure that the data is up to expectation.
- Data analysis: Exploratory data analysis can help practitioners understand the content and structure of the extracted data. This step helps practitioners identify the steps needed to prepare the data for the machine learning task.
- Data preparation: Data preparation involves cleaning the data, performing feature engineering, and splitting the data into train, validation and test sets for the machine learning model.
- Model Training: Data scientists use the training set to train multiple machine learning models, perform hyper-parameter tuning, and select the best model using the train set.
- Model evaluation: The validation set is used to evaluate the model’s performance using a set of agreed metrics.
- Model validation: A ‘model acceptance test’ is run on the machine learning model to ensure that its predictive performance meets a certain baseline and is adequate for deployment.
- Model serving: Once the model passes the model validation stage, it is ready to be deployed to the production environment. This can come in the form of microservices with a REST API, an embedded model to an edge device, or part of a batch prediction system.
- Model monitoring: The performance of the production model is logged.
Data scientists often learn to train ML models on offline datasets in Jupyter notebooks. Thus, those unfamiliar with model serving and monitoring might opt for a manual process for putting the machine learning model in production. While feasible, such a strategy comes with some inherent challenges.
Challenges of Manually Delivering an ML Model
The most basic machine learning system implements every step of the machine learning process manually. Often, the code for data extraction, cleaning and modeling is run iteratively in a notebook. Once the ML experiment yields a satisfactory model, the model is uploaded to a model registry for an engineer to deploy and serve the model.
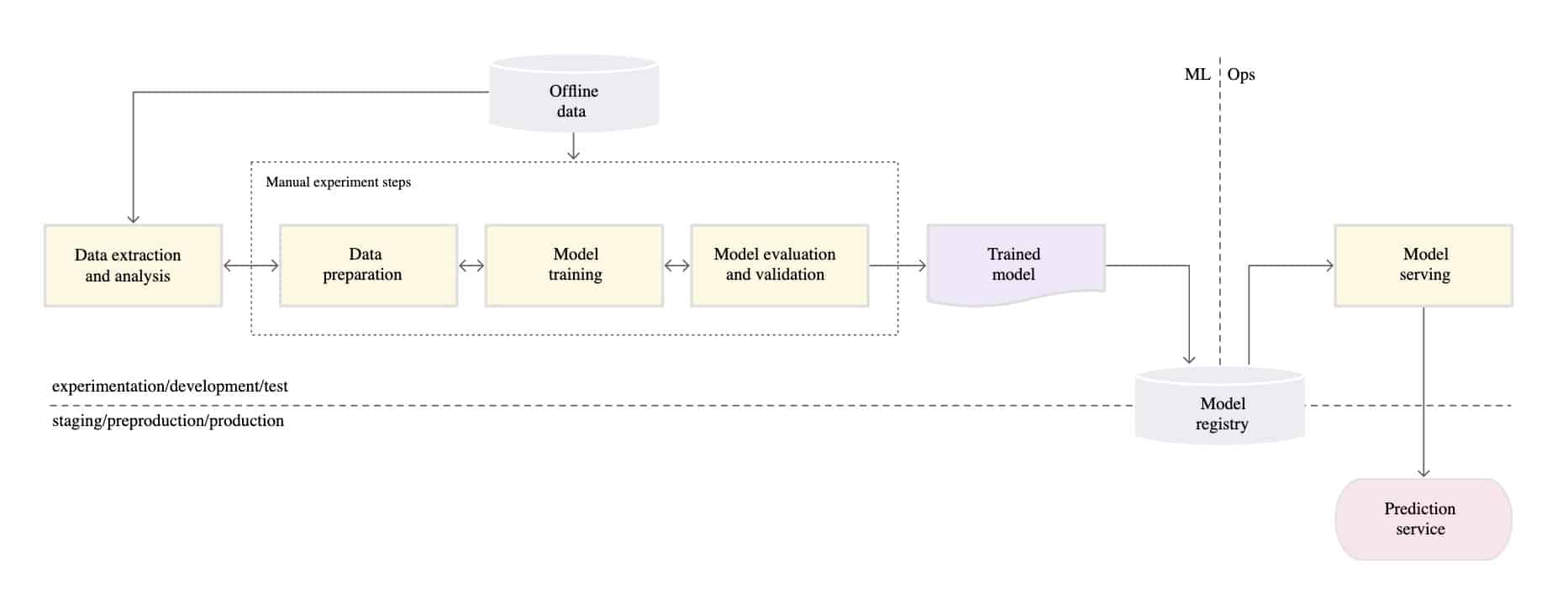
Figure 3: A manual ML pipeline [Source]
Such a manual process can be implemented very quickly but breaks easily when deployed in the real world. Some possible modes of failure include:
- Decay in performance due to training-serving skew. The manual pipeline separates the data scientist training the model and the engineer deploying the model. Conceivably, such a disconnect might introduce differences in the data handling steps in (and thus the performance of) the training and production pipelines.
- Decay in performance over time due to drifts. Typically, machine learning systems implemented manually are not updated for an extended period. When that happens, any changes to the underlying input data (data drift) or even the definition of the predicted variable (concept drift) might result in performance decay.
- Difficulty in model debugging. The manual process might not be reproducible if version control is not implemented for the data, code and ML model. Also, the absence of performance monitoring translates into low visibility into the model’s historical performance. Both add to the difficulty of debugging the system.
The challenges of a manual machine learning development process have catalyzed the emergence of MLOps practices. Such practices call for a high degree of automation and testing in every step of the machine learning process.
Advantages of Using MLOps in Delivering an ML Model
ML Systems with a high level of MLOps maturity implements continuous integration/continuous delivery (CI/CD) practices. This is made possible by triggers, automated pipelines, and metadata management and performance monitoring tools.
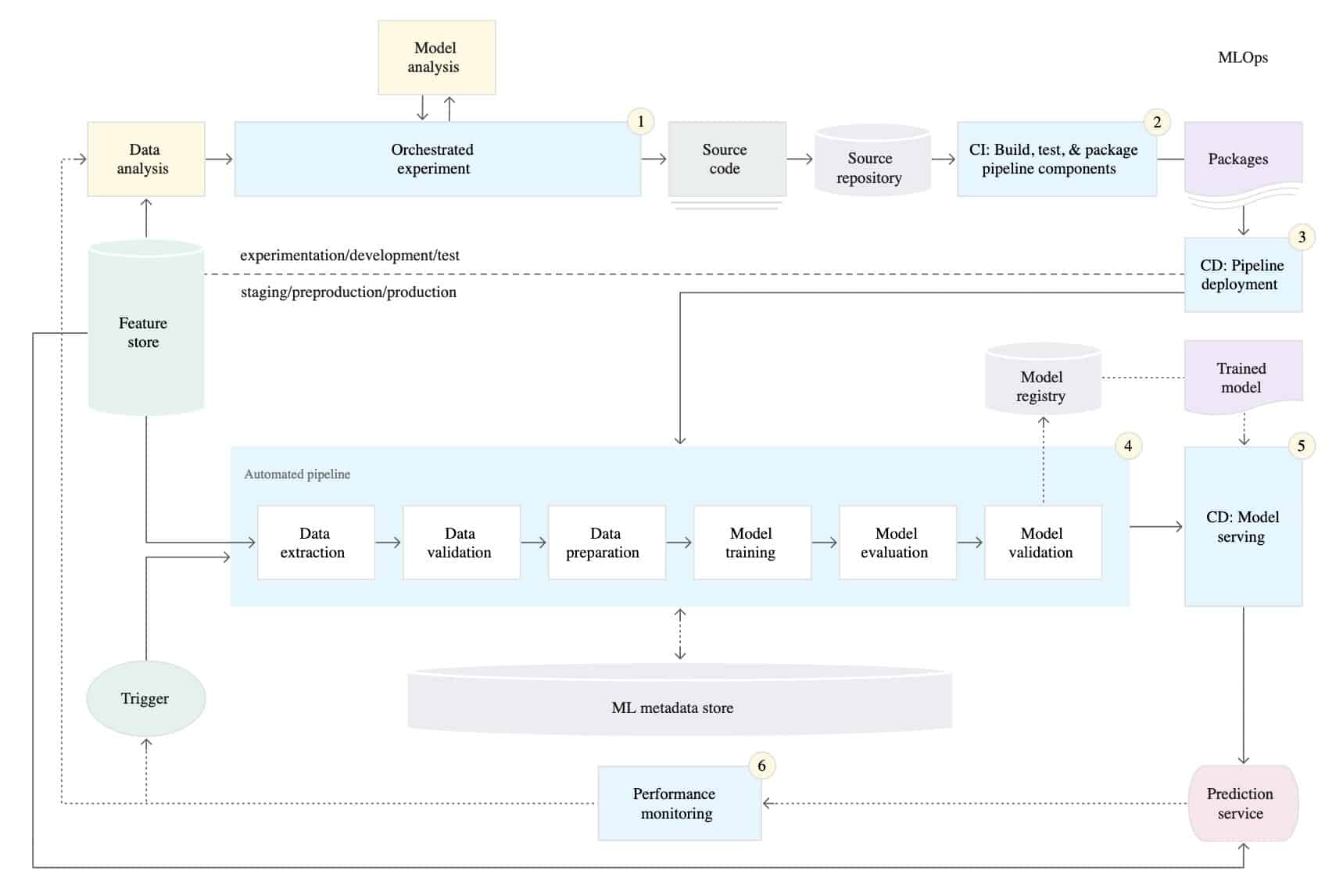
Figure 4: A fully automated ML pipeline [Source]
In the fully automated ML process, every component of the ML experiment from data validation to model validation is continuously built, tested and deployed as an automated pipeline. This means that the experimental and production pipelines are identical.
The automated process extracts new data automatically and runs the predefined machine learning steps to produce an ML model once it is triggered. In the process, the ML metadata is stored to allow for effective version control.
The resulting trained and validated model is automatically served as a prediction service to achieve the continuous delivery of the model. The model then provides predictions on live data, and its performance is closely monitored.
Though the automated process is much more complex than the manual process, it addresses the challenges of the manual process in the following ways.
- Automation eliminates training-serving skew. Since the experimental and production pipelines are identical, training-serving skew is no longer a problem. This is a stark improvement to the manual process where only the machine learning model is deployed.
- Automation helps address drifts. The CI/CD of the machine learning system results in a more frequently updated ML model. This leaves less leeway for performance decay from data and domain drifts to creep into the system unnoticed.
- Testing and monitoring facilitate the debugging process. The unit tests implemented as part of CI/CD of the machine learning system prevent bugs from making it to production. Moreover, the constant performance monitoring of the system provides helpful logs to identify the possible causes of a bug.
An automated pipeline is incomplete without unit tests and performance monitoring. These features ensure that bugs are caught and fixed in time.
Unit Tests
Much like how prescription drugs go through rigorous rounds of tests in the lab before reaching the hands of a consumer, software undergoes unit tests before they are released. This process is called software testing, where tests are run to ensure that the software meets the expected requirements and is defect-free.
Rigorous unit tests set a solid foundation for the long-term development of software. They allow errors to be caught before they become intractable, increase code modularity, and boost the overall reliability in the system.
Unit tests form an integral part of the continuous integration of the ML pipeline. The seminal paper The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction suggests multiple categories of unit tests for a reliable, production-level machine learning system, including tests for features and data, model development, and ML infrastructure.
Performance Monitoring
Unit tests are crucial in preventing bugs before they make it into production. Yet, they cannot detect bugs that are already in production. To do so requires the constant monitoring of the performance of the ML system. Alerts are sent to the engineering team when a metric deviates beyond a threshold.
Apart from monitoring the predictive quality (like accuracy) of the ML system, it is also important to monitor the computational performance (like training speed, serving latency, throughput, or RAM usage) of the ML system to keep the resource usage of the system in check.
ML Development Takes More Than Just Modeling
Clearly, a complete ML System includes much more than the ML model. In the words of Google researchers, “the required infrastructure [surrounding ML systems] is vast and complex”. The development and maintenance of such a system require the consistent application of MLOps principles.
_______
Gil is the CTO and co-founder of Datagen.
Read our Survey on Synthetic Data: The Key to Production-Ready AI in 2022
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
