
























What Is the Transformer Architecture and How Does It Work?

What Is a Transformer Model?
Transformer is a deep learning (DL) model, based on a self-attention mechanism that weights the importance of each part of the input data differently. It is mainly used in computer vision (CV) and natural language processing (NLP).
Similar to recurrent neural networks (RNNs), transformers are designed to process sequential input data like natural language, and perform tasks like text summarization and translation. However, unlike RNNs, transformers process the entire input at once. The attention mechanism allows the model to focus on the most relevant parts of the input for each output.
For instance, if the input data is natural language sentences, the translator will not need to process one word at a time. This makes it possible to parallelize processing, more so than in RNNs, thus reducing training time. This has spurred the development of large pre-trained systems such as Bidirectional Encoder Representations from Transformers (BERT) and Generalized Pre-trained Transformers (GPT).
Introduced by the Google Brain team in 2017, the Transformer architecture is increasingly becoming a model of choice for NLP problems, replacing RNN models such as long short-term memory (LSTM).
This is part of a series of articles about computer vision.
In This Article
The Transformer Architecture
The Transformer architecture uses an encoder-decoder structure that does not rely on recurrence and convolutions to generate an output. The encoder maps an input sequence to a series of continuous representations. The decoder receives the encoder’s output and the decoder’s output at a previous time step, and generates an output sequence.
Here is an image that visualizes the architecture:
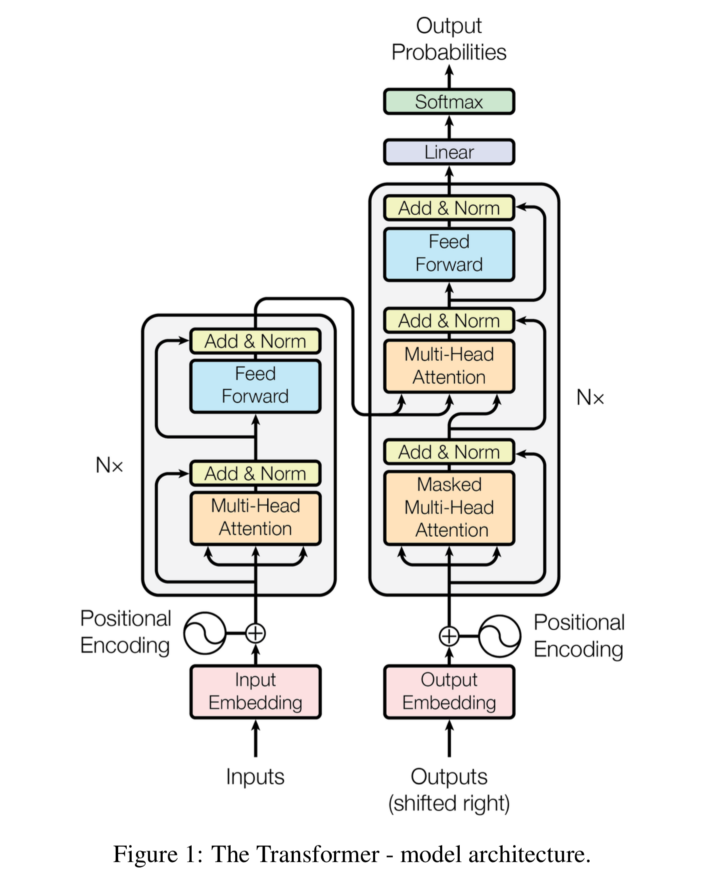
Image Source: arXiv – Attention Is All You Need
Since it is impossible to use strings directly, the architecture first converts the input data into an n-dimensional embedding, which is then fed to an encoder. The encoder and decoder consist of modules stacked on each other several times (represented as Nx in the image). The modules include mainly feed-forward and multi-head attention layers.
Here is an image that shows the multi-head attention bricks in the model:
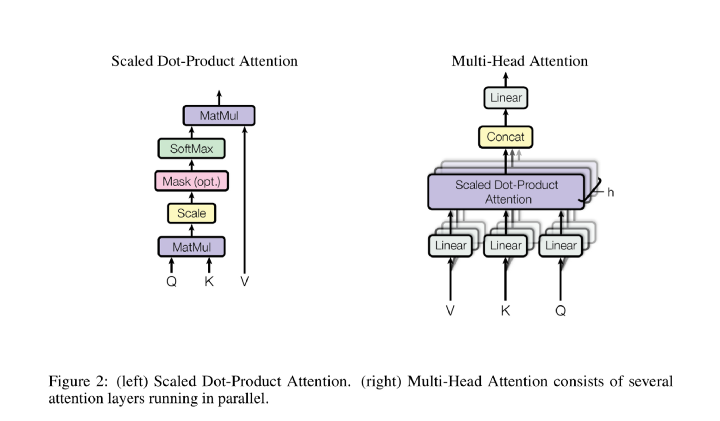
Image Source: arXiv – Attention Is All You Need
Scaled dot-product attention
The following equation describes the left part of the attention mechanism in the above image:
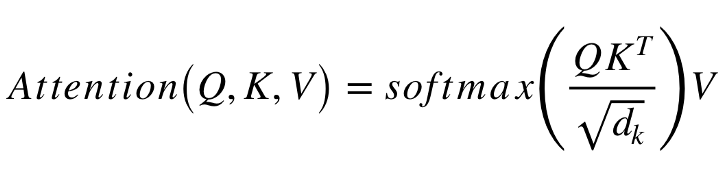
Here is an explanation of the equation:
- Q represents a matrix containing the Query
- K consists of all Keys, the vector representations of all the words in the sequence.
- V represents the Values, which is often the same as K.
The V values are multiplied and summed with attention-weights a. The weights are defined using the following formula:
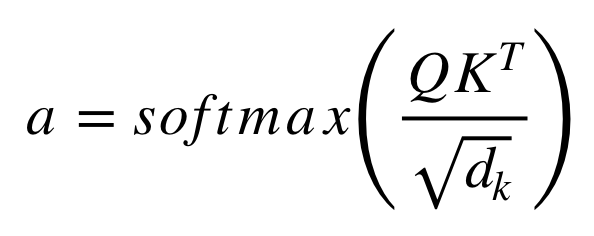
The Softmax function normalizes the value of a to a scale of 0 to 1. Next, the model applies these weights to all the words in value V.
Multi-head attention
The image above describes how this attention mechanism is parallelized. The multi-head attention mechanism enables the model to pay attention to multiple parts of the key simultaneously.
Positionally encoding different words
The Transformer does not have an RNN that can remember how input sequences were fed into the model. However, it needs to give every word or part in the sequence a relative position because a sequence depends on its elements’ order. The architecture adds these positions to each word’s embedded representation (n-dimensional vector).
Transformer challenges
The vanilla Transformer model helps overcome the RNN model’s shortcomings but has two key issues:
- Limited context dependency—the Transformer outperforms the LSTM for character-level language modeling purposes. However, the Transformer cannot keep long-term dependency information beyond the configured context length. Additionally, the Transformer cannot correlate with words that appeared several segments ago.
- Context fragmentation—the Transformer is trained from scratch for each segment. No context information is stored in the first few symbols of each segment, leading to performance issues.
Explore Synthetic Data with Our Free Trial!
Real-Life Transformer Models
Here are several models developed in the technology industry, based on the transformer architecture, which are intended for large-scale commercial use.
BERT
Bidirectional Encoder Representations from Transformers (BERT) is a deep learning model developed by Google researchers that has been widely used for natural language processing tasks. Since 2020, BERT has been a basic component of the Google search engine and is used to process all English language search queries. BERT is a variation of the Transformer model that was introduced in the paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” by Devlin et al.
One key aspect of BERT is that it is a “bidirectional” model, which means that it takes the context on both the left and the right of a word into account when processing the text. This is in contrast to traditional “unidirectional” models that only consider the context to the left of a word. This bidirectional approach allows BERT to perform much better on tasks that require an understanding of the context in which a word appears, such as natural language understanding and machine translation.
LaMDA
Language Model for Dialogue Applications (LaMDA) is a large-scale language model for dialogue applications developed by Google. As of the time of this writing, it has not been released to the public. It was designed to generate human-like responses to a given input and has the ability to hold a coherent conversation on a wide range of topics. LaMDA was trained on a dataset of conversations between humans, allowing it to learn the structure and patterns of human dialogue.
In addition to generating responses, LaMDA can also perform a variety of other natural language processing tasks, such as translation and summarization. It has the potential to be used in a variety of applications, including chatbots, virtual assistants, and language translation systems.
GPT3
GPT-3 (short for Generative Pre-Trained Transformer 3) is a state-of-the-art natural language processing model developed by OpenAI. It was trained on a very large dataset and is able to generate human-like text that is coherent and appropriate for a given prompt. GPT-3 is primarily used for generating text, while BERT is primarily used for understanding the meaning of text.
GPT-3 has a wide range of potential applications, including language translation, question answering, summarization, and content generation. It has received a lot of attention in the media and is considered one of the most advanced language models currently available.
ChatGPT
ChatGPT is a chatbot built by OpenAI using a newer version of the GPT model, called GPT-3.5. It can interact in a dialogue format, providing responses that closely resemble human conversation. As a large language model, it can generate coherent and diverse text because it has learned the statistical patterns and structures of the language from the training data.
Reinforcement learning with human feedback (RLHF) is another type of machine learning used in ChatGPT, which combines reinforcement learning with human input. In reinforcement learning, an agent learns by interacting with its environment and receiving rewards or punishments for its actions.
In RLHF, the agent can also receive feedback from a human in the form of reward or punishment signals. This can be used to help the agent learn more quickly or to learn a task that is difficult to specify using a traditional reinforcement learning algorithm.
Other Transformer Model Architectures
The Transformer-XL
Transformers XL (extra long) is a new variation on the transformer model, which introduces relative positional encoding and a recurrence mechanism.
In Transformer-XL, the model keeps the previously learned segment in a hidden state, and uses it for the current segment, instead of calculating each segment’s hidden state from scratch. This addresses the problems introduced by the vanilla transformer model, and overcomes the long-term dependency problem.
Another advantage is that it solves the problem of context fragmentation caused by using recently initialized or empty context information. Therefore, the new model can be used for character-level language modeling and word-level modeling.
The role of the recurrence mechanism
Transformer-XL introduces recurrence to maintain dependencies between segments. It processes the first segment like a regular transformer, and keeps the output of the hidden layer while processing the next segment.
Recurrence can speed up evaluation. Instead of starting from scratch in the evaluation phase, it enables reusing the previous segment representation. The inputs to each layer are concatenated from the output of the previous layer (like a regular transformer), and the previously processed hidden layer.
Challenges of recurrence
While the recurrence mechanism is beneficial, it creates a new problem. Positional information stored in the hidden state is reused in the previous segment.
As with traditional transformers, the positional encoding process can result in multiple tokens, obtained from segments with the same positional encoding, but which have a different level of importance.
To solve this, transformer-XL combines recursion with an attention mechanism. This addresses the context fragmentation and limited context-dependency of the original model, and allows it to handle word-level language modeling with faster evaluation speed.
Importantly, transformer-XL has been shown to achieve long-term dependency. According to the original transformer-XL paper, it learns dependencies that are 80% longer than RNN, 450% longer than the original transformer model, while being up to 1800x faster than the original transformer model during evaluation.
Link to paper: https://arxiv.org/pdf/1901.02860.pdf
Link to open source repo: https://github.com/kimiyoung/transformer-xl/
The Compressive Transformer
The Compressive Transformer is an extension of the transformer model that maps past hidden activations (known as short-term or granular memories) into a smaller set of compressed representations (known as long-term or coarse memories).
Compressive transformers learn to query both short-term memory and long-term memory, using the same attention mechanism both for granular and coarse memories. It is based on transformer-XL’s idea of keeping a memory of past activations in each layer to preserve longer contextual records.
While transformer-XL deletes previous activations when they are old enough (controlled by memory size), the compressive transformer does not discard old memories—instead, it compresses it and stores it as long term memory, in addition to recent short term memory.
At each time step, it discards the oldest compressed memory using first in first out (FIFO), compresses the oldest state in short-term memory, and transfers it to a new slot in compressed memory. During training, the compressed memory components are optimized separately from the underlying language model, using separate training loops.
Link to paper: https://arxiv.org/pdf/1911.05507v1.pdf
Benchmarks Showing Performance of the Transformer Architecture
There are now several robust industry benchmarks for evaluating the performance of NLPmodels.
Performance on Machine Translation Tasks
The Transformer has achieved state-of-the-art results on several machine translation benchmarks, including the WMT14 English-to-German translation task and the WMT16 English-to-Romanian translation task. WMT is a widely used benchmark, so it is a useful reference point for comparing the performance of different machine translation systems.
However, the translations in the WMT dataset were created by an automated process rather than being collected from real-world translations. It is also a static benchmark, meaning that the dataset does not change over time. Thus, the WMT dataset may not fully reflect the complexity and diversity of real-world translations.
Performance on QA Benchmarks
Question answering (QA) benchmarks are datasets that are used to evaluate the performance of natural language processing systems on question answering tasks. These benchmarks typically consist of a collection of questions and their corresponding answers, along with additional context such as a passage of text or a table of data. QA benchmarks are used to measure the ability of a system to understand and respond to questions in natural language.
Some examples of QA benchmarks include:
- SQuAD (Stanford Question Answering Dataset): consists of a collection of Wikipedia articles and a set of questions and answers related to the articles.
- TriviaQA: Consists of a collection of trivia questions and answers gathered from various sources on the web.
- HotpotQA: Focuses on multi-hop reasoning, meaning that the system must use multiple pieces of information to answer the question.
QA benchmarks provide a clear and objective way to measure the performance of a system on a specific task. They often include a large and diverse dataset of questions and answers, which can provide a good test of the generalization capabilities of a system. However, QA benchmarks may not capture all of the factors that are important for evaluating the performance of a natural language processing system.
Performance on NLI Benchmarks
Natural language inference (NLI) benchmarks help evaluate the performance of natural language processing systems on tasks that require an understanding of the relationship between two pieces of text. NLI is also known as recognizing textual entailment (RTE).
In an NLI task, a system is presented with a pair of text fragments, called a premise and a hypothesis, and must determine whether the hypothesis can be inferred from the premise. For example, given the premise “The cat is on the mat” and the hypothesis “The cat is sleeping,” the system would need to determine that the hypothesis is true based on the information in the premise.
Some examples of NLI benchmarks include:
- SNLI (Stanford Natural Language Inference): Consists of a collection of English sentence pairs annotated with labels indicating whether the hypothesis can be inferred from the premise.
- MultiNLI (Multi-Genre Natural Language Inference): Contains English sentence pairs drawn from multiple genres of text.
- XNLI (Cross-lingual Natural Language Inference): Contains sentence pairs in 15 different languages, along with annotations indicating whether the hypothesis can be inferred from the premise.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
