
























3D Common Corruptions and Data Augmentation

Introduction
Data distribution shift happens when actual data distribution differs from those the machine learning model was trained on. The most common cause of data distribution shifts in the computer vision domain is data corruption/perturbation. Corrupted visual data distributions can result from illumination changes, camera movements, or weather conditions. Additionally, there are “more semantic” data distribution shifts including texture changes and object occlusions (see Fig.1)

{kind=link}
Figure 1: Natural data distribution (the leftmost image in each row is an original image). The first row contains fog data distribution, the middle one motion blur and the lower row depicts defocus blur data distribution
Human vision is resilient to a wide range of changes and corruptions in visual data distribution. In contrast, machine learning (ML) models perform inferiorly when the distribution of data changes even slightly. It means that data distribution changes in the real world can significantly deteriorate the accuracy of ML-based systems. Therefore ML models’ resilience to distribution shifts is fundamental to their real-world deployment.
In spite of their widespread presence in real-world deployments, distribution shifts are under-represented in the datasets which are usually used for model training by the ML community. This is due to the infeasibility of collecting a training set covering all possible distribution shifts that may occur in real-world applications.
In every situation where data distribution shifts occur, a model may fail, potentially resulting in unpredictable and unreliable performance. The vulnerability of ML models to these shifts must therefore be thoroughly tested before they are deployed in the real world environment.
Leverage Synthetic Data to Cope with Distribution Shifts
So the problem is that most of the common datasets do not include these distribution shifts. How can this be dealt with? These limitations could be overcome by using synthetically generated data. The authors propose a set of image transformations that can be applied for:
- ML model training in a variety of data corruption scenarios (e.g.augmentation) to enhance model robustness to data corruptions
- Evaluation of a trained ML model resilience to a variety of data distribution shifts
Previous works haven’t used image 3D information for corrupted data generation, which in many cases led to non-realistically corrupted images. The use of 3D image information, which is available with synthetic data, may allow a more realistic simulation of real-life data corruption scenarios.
The paper, 3D Common Corruptions and Data Augmentation, proposes an innovative set of data transformations, dubbed 3DCC, that takes into account 3D image information, enabling the generation of data corruptions that are more consistent with real visual data corruptions. For example, for data corruption occurring due to the motion blur, 3DCC takes into account a phenomenon called motion parallax. The principle of motion parallax states that objects moving at a constant speed will appear to move more when closer to an observer (or camera) than when farther from the observer. Another example of data distribution shift source is an illumination condition change (e.g., lighting conditions depend on the time of day/year when the image was taken). When simulating data corruptions due to illumination changes, 3DCC takes the scene geometry into account and generates shadows on objects as needed. Prior schemes (e.g. Common Corruptions or 2DCC) for visual data corruption simulation did not take these effects into account, resulting in less realistic images. Fig. 2 contains comparison of corrupted images corrupted with 2DCC and 3DCC.

{kind=link}
Figure 2. Using 3D information to generate real-world corruptions. The top row shows sample 2D corruptions applied uniformly over the image, e.g. as in 2DCC, disregarding 3D information. This leads to corruptions that are unlikely to happen in the real world, e.g. having the same motion blur over the entire image irrespective of the distance to camera (top left). Middle row shows their 3D counterparts from 3D Common Corruptions (3DCC). The circled regions highlight the effect of incorporating 3D information.
3D Data Corruptions Generation
The authors define 8 basic categories of data corruption (by the factor responsible for it). These data corruption mechanisms are combined to create 20 different data corruption regimes. It is necessary to have a RGB image and a scene depth to generate most corruptions, while a 3D mesh (a structural build of a 3D model consisting of polygons) is required to create several of them. A general flow of 3DCC is depicted in Figure 3.
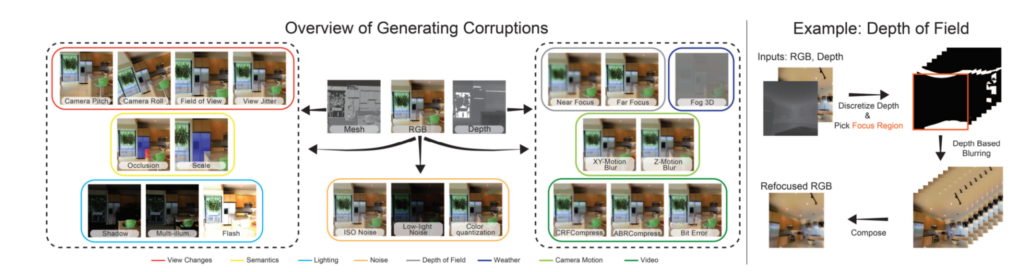
{kind=link}
Figure 3. 3DCC Overview: shows the inputs needed to create each of our corruptions (e.g. the 3D information such as depth, and RGB image. These corruptions have also been grouped (in solid colored lines) according to their corruption types. For example, to create the distortions in the dashed box on the right, one only needs the RGB image and its corresponding depth. For the ones in the left dashed box, 3D mesh is required. One can create view change corruptions also from panoramic images if available, without a mesh.
Next we briefly describe how the logic behind the aforementioned categories of data corruptions:
- Depth of field corruptions: generates out-of-focus images. Here some parts of the image remain in focus while others are blurred. By selecting the focus region randomly, corruptions in the near-focus or far-focus areas of the scene are created.
- Camera motion corruption: creates blurry images when the camera moves during exposure. To generate this corruption, an image depth map is leveraged to build the point cloud. Then, novel views are rendered along chosen camera trajectories.
- Lighting corruptions: adds new source illumination and modifies the original scene’s illumination. The authors generate 3 types of lightning corruptions: flash corruption (a light source located at the camera position), shadow corruption (randomly positioned light sources) and multi-illumination corruption (3 different sources of illumination with varying locations and brightnesses). The authors utilized the Blender framework to place new light sources and then calculate illumination for a given viewpoint in the 3D mesh.
- Video corruptions: occur while streaming or processing video. First a video is generated from a single image using scene 3D info. A corrupted video is created by simulating a poor video transmission channel, and then a single frame is selected as a final corrupted image.
- Weather corruption causes parts of the scene to become blurry due to medium disturbances. The paper generates “foggy” (disturbed) images taking into account the amount of atmospheric light and the amount of light reaching the camera (transmission function). Using scene depth information, the distance from the camera is estimated to determine the transmission to different image parts.
- View changes corruptions: produced by varying camera extrinsics and focal lengths. 3DCC renders RGB images as a function of field of view, camera roll and camera pitch, using Blender. The authors also simulate so-called view jitter to examine model predictions resilience to small viewpoint changes.
- Semantic changes: Occlusion levels and scales for different objects in the image are modified in order to simulate this data corruption. Scale corruption renders object views with varying distances from the camera, whereas images rendered with varying levels of occlusion are used to determine whether a model is robust to occlusion changes. To generate this data corruption annotated mesh (e.g., objects, scene categories, material types, texture, etc.) is required. The authors used an approach, proposed in 3D Scene Graph.
- Noise: The paper generates corrupted images for 3 types of noise.
- Low-light noise: mimicks low-light regime. To generate low light noise pixel intensity is reduced and Poisson-Gaussian distributed noise is added (see paper for more details).
- ISO noise: is modeled by Poisson-Gaussian distribution comprising a photon noise (Poisson), and varying electronic noise (Gaussian)
- A quantization noise.
Performance Analysis
First the paper states that data corruptions generated with 3DCC are capable of discovering weaknesses of robustness mechanisms used during model training. When data is corrupted with 3DCC, all previously developed robustness mechanisms perform poorly for surface normal estimation and depth estimation tasks.

Figure 4: 3DCC vs. other robustness mechanisms: Adversarial training(Adv.Train), DeepAugment(Deepaug), Style Augmentation(style), Cross-Domain Ensembles (X-DE) and 2DCC Augmentation. Each bar shows the l1 error averaged over all 3DCC corruptions. Error bars in black show errors at low and high data shift(corruption) intensities. The red line denotes the performance of the baseline model on clean (uncorrupted) data.
It is noteworthy that the above graph shows that several robustness mechanisms used for model training are not resilient to the data corruptions generated by 3DCC. In other words, model performance trained with these mechanisms exhibit a substantial performance degradation for 3DCC corruption, compared to the clean data performance.
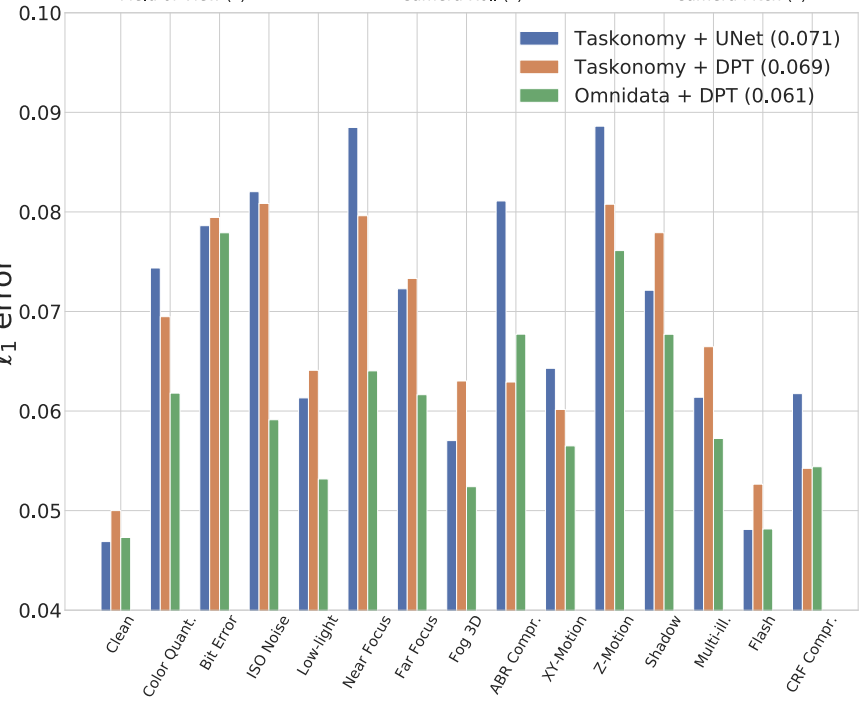
The paper also shows that the bigger the training set and the more diverse it is, the better the model performs under 3DCC corruptions (see Fig.5). Also “better network architecture” positively affects the trained model robustness against 3DCC corruptions. The authors examined 2 datasets: Omnidata Taskonomy, which is a mix of multiple diverse datasets, while Taskonomy is a smaller and less diverse dataset. Then they picked 2 network architectures:
- DPT: an advanced neural architecture being used in vision transformers to replace ConvNet-based backbone
- UNet: basic network architecture used for a plenty of dense computer vision tasks (object detection, super-resolution)
An improved network architecture and more diverse dataset (Omnidata) resulted in better performance (in terms of average l1 error).
{kind=link}
Figure 5: Models trained on diverse datasets combined with “better” network architecture are more resilient to 3DCC corruptions. Average l1 error on the test set is shown.
Conclusions:
The paper proposes an approach for generating synthetic data that simulates a variety of distribution shifts in visual data which can occur after model real-world deployment. In contrast to the previous works, the proposed schemes extensively leverages 3D information (depth, 3D meshes) to construct these data corruptions. The proposed corruptions demonstrate the ability to expose weaknesses for existing models as well as enhancing a model’s robustness against a wide spectrum of data corruption when used during model training.
The main disadvantage of the proposed scheme is the need for 3D image information, which is often unavailable. While image depth maps, required to generate corrupted data with 3DCC may be shared along with the photos themselves, image 3D information is hard to acquire. In spite of the fact that the corrupted images created by the method look highly realistic, its efficiency cannot be evaluated until the models trained with it are tested in real-world environments.
Moverover, when 3DCC is used for weaknesses discovery, no correlation is shown between 3DCC corrupted data and real environment data. The experiment shows that models, trained with several robustness mechanisms, exhibit weak performance on data corrupted with 3DCC. This does not guarantee the proposed method can in fact be used as a benchmark for model performance in the real world.
Finally, the authors made their code publicly available.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
