
























Procedural Humans for Computer Vision

This is part one of our review of the Procedural Humans for Computer Vision paper.
Synthetic data has shown tremendous potential in various applications, including autonomous driving, face detection, and reconstruction. Its benefits of privacy preservation, bias elimination, and quality of annotation make it an excellent complement–if not a superior alternative–to real-world data.
Recent work shows that effective machine learning models can be trained using synthetic face data alone. This begs the question: can the successes of synthetic face data be replicated with synthetic body data alone? There are strong reasons to believe so, and one of them is the recent report “Procedural Humans for Computer Vision” authored by Hewitt et al. in 2023.
The seminal paper describes a method to generate realistic images of synthetic humans with a parametric model of the face and body, and a rendering pipeline. It also uses the synthetic dataset to train a landmark detection model. In this post, we will explore the inner workings of this method.
In This Article
Synthetic Humans from “Procedural Humans from Computer Vision”
The synthetic humans generated with the Procedural Humans pipeline (Figure 1) are impressive. In addition to their realistic faces, diverse expressions, and diverse identities, they have a variety of body shapes, sizes, and poses.
Figure 1. Images generated by the Procedural Humans pipeline
An Overview of the Pipeline
“Procedural Humans” builds on a previous study entitled “Fake It Till You Make It” by Wood et al. (2021)., which describes a process of generating realistic and expressive faces procedurally. Starting with a template face, the authors randomize the identity, choose a random expression, apply a random texture, attach random hair and clothing, and render the face in a random environment (Figure 2).

Figure 2. The procedure for generating a face in “Fake It Till You Make It”
The pipeline of “Procedural Humans for Computer Vision” for generating humans closely mimicked what we see in Figure 2. The process starts with a face and body template, and proceeds by randomly selecting face and body identities, attaching clothing and hair, applying texture to the face and body, giving the human a random pose, and ends with rendering the final image in a random environment (Figure 3).
Next, let us walk through the pipeline proposed by Procedural Humans–one step at a time.

Figure 3: The stages of generating a synthetic human in Procedural Humans for Computer
Step 1. Creating the template
First, the authors require a model of the human face and body to apply clothing, hair, textures, and poses to.
To achieve this, they combined the high fidelity face model of Wood et al. (Figure 4A) with the body and hand model SMPL-H (Figure 4B). (The SMPL-H model is a skinned vertex-based model that accurately represents a wide variety of body shapes in natural human poses.) The resulting parametric model (Figure 4C) gives the author control over the synthetic human’s facial identity and body characteristics.
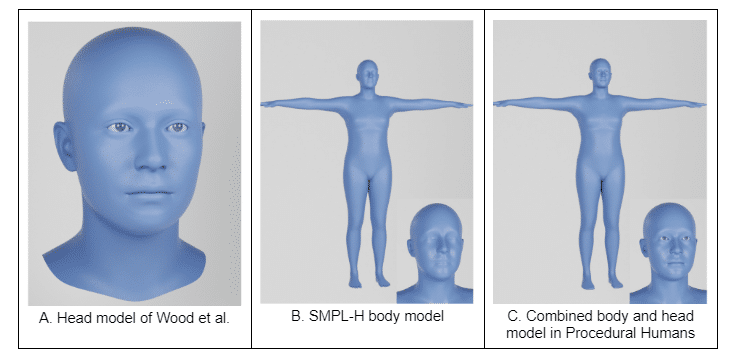
Figure 4
Step 2. Sampling the identity
Next, the features of the face and body to create identities can now change (Figure 5). To put it plainly, this step gives a synthetic human their defining characteristics, like face shape, eye size, body size, and body shape.
To randomly sample the face identity, a multivariate Gaussian distribution is fit to male, female, and all identities present in the facial dataset of Wood et al. This distribution allows for the random sampling of male, female, and neutral facial identities.
The authors used the popular SMPL-H model to sample the body identity.
 |
 |
 |
Figure 5: Examples of identities. Top row: male, middle row: female, bottom row: neutral
Step 3. Adding clothing and accessories
Next, dressing and accessorizing the synthetic human.
In “Fake It Till You Make It”, the authors successfully added face clothing and accessories with the use of mesh-based assets. These include headwear, facewear (such as masks and eye-patches), and glasses. Such assets are attached directly to the head bone of the full body. The authors of “Procedural Humans for Computer Vision” replicated this process in their pipeline.
The process of adding body clothing and accessories (Figure 6) is more challenging. That is because these items need to adapt to the dynamic pose of the body. Thus, the authors used displacement maps to model such clothing items. In addition, each asset was given a normal, roughness, metallic, and albedo map to create realistic shading.

Figure 6. Examples of clothing and accessories (including tops, bottoms, bracelets, gloves, ring and watches) in the Procedural Humans for Computer Vision paper
Step 4. Adding hair
The authors used the hair assets from “Fake It Till You Make It” (Figure 7) in this report with little modification.

Figure 7. Hair assets used
Step 5. Adding texture
The next step in the pipeline gives skin textures to synthetic humans.
The face texture of a synthetic human is sampled independently of its body texture. Interestingly, the skin textures for the face and body are obtained from different sources. The authors used the high quality skin texture library of Wood et al. for the face, and a set of 25 high quality textures from 3D body scans for the body. Figure 8A shows an example of the high quality skin texture used for the face, while Figure 8B shows an example of the high quality texture used for the body.
 A. Face Textures |  B. Body Textures |
Figure 8. Face and body textures used in Procedural Humans for Computer Vision
Conceivably, there can be significant mismatches in the skin tone that result from sampling face and body textures independently (Figure 9A). To address this, the authors first sample a face texture from the library, and then select a random body texture with an average skin tone that is perceptually similar to that of the face (Figure 9B).
While this provides quite close matches in skin tone between the face and body, there are still minor mismatches. To address this, they adjust the mean and variance of pixel values in the body texture to match that of the face texture, ensuring a precise match in the skin tone between the body and face (Figure 9C).

Figure 9
Step 6. Adding Poses
Afterward, the procedural human model is assigned specific poses, including a facial expression and a body pose.
Before the pose can be assigned, the authors need to source for libraries from which specific poses can be selected. The authors leveraged the facial expression libraries from the paper “Fake It Till You Make It” and curated their own body pose library (Figure 10), a combination of the existing AMASS dataset and motion-capture data.

Figure 10. Example poses sampled from the body pose library
Interestingly, the authors did not sample poses uniformly. Instead, they favored poses that are useful for downstream tasks.
The non-random sampling process is possible with the use of a Gaussian mixture model (GMM) that classifies poses into a set of coarse classes, one of which is T-pose. They down-weighted T-poses (not useful for certain downstream tasks) and up-weighted frames with higher mean absolute joint angles (which are considered to have more interesting poses). The authors also applied a similar approach when sampling facial expressions from the expression library of Wood et al.
The facial expression is sampled independently and spliced with the body pose. This approach produces realistic results.
Step 7. Rendering the Human with the Environment
The final step is to place the synthetic humans in a physical environment. The assets used for the environment were from Wood et al.
That concludes the pipeline for procedurally generating synthetic humans, which results in synthetic images as seen in Figure 1. The dataset generated can then be used for downstream computer vision tasks.
In part 2 of this blog, we’ll explore how the authors use synthetic data to train a landmark detection model.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
