
























Image Annotation for Computer Vision: A Practical Guide

In This Article
What Is Image Annotation?
Image annotation is the practice of assigning labels to an image or set of images. A human operator reviews a set of images, identifies relevant objects in each image, and annotates the image by indicating, for example, the shape and label of each object. These annotations can be used to create a training dataset for computer vision models. The model uses human annotations as its ground truth, and uses them to learn to detect objects or label images on its own. This process can be used to train models for tasks like image classification, object recognition, and image segmentation.
The number of labels assigned to an image can vary depending on the type and scope of the project. In some cases, a single label is sufficient to represent an entire image. In other cases, annotators identify specific objects, segment an image into relevant regions, or identify landmarks, which are specific points of interest in an image. To ensure labeling accuracy, it is common to allow multiple annotators to label the same image, with majority voting to select the label that is most likely to be correct.
This is part of an extensive series of guides about machine learning.
How Does Image Annotation Work?
Image annotation projects involve large scale annotation of images by teams of human annotators. The annotators must be well trained in the requirements of the project and adept at accurately performing the necessary annotations.
Image annotation work typically includes the following tasks:
- Preparing the image dataset
- Specifying object classes that annotators will use to label images
- Assigning labels to images
- Marking objects within each image by drawing bounding boxes
- Selecting object class labels for each box
- Exporting the annotations in a format that can be used as a training dataset
- Post processing of the data to check if labeling is accurate
- In case of inconsistent labeling, the system should enable a second or third labeling round with voting between annotators
What Are Image Annotation Tools?
There are several open source and freeware tools available for annotating images. A common open source tool used in many large-scale projects is Computer Vision Annotation Tool (CVAT). Image annotation tools support the annotation process itself (for example, they enable drawing complex shapes on an image), and provide a structured labeling system so annotators can apply the correct labels to image artifacts.
Key features and capabilities of image annotation platforms include:
- Efficient user interface—should support fast labeling, reduce human error, and be intuitive for the workforce without extensive training.
- Ontology and taxonomy support—should be configurable to the label structure required for the machine learning model, including classifications, hierarchical relationships and custom variables.
- Annotation quality—accuracy in image annotation is paramount. An annotation platform should support multiple techniques for measuring quality including benchmarking (comparing annotation work to a gold standard) and consensus (comparing labels from two or more annotators who work on the same task).
- User management—should support remote user management, the ability to define supervisors who can review work by annotators, and collaboration features to enable supervisors to provide feedback on the work.
- Automation—advanced annotation platforms can reduce human error and make annotation work more efficient by automating complex annotation tasks. Automated pixel maps and label suggestions can be a starting point for human annotators.
- Supports common formats—the tool should export annotation data in a simple format that users can easily understand and use in machine learning models.
Types of Image Annotation
Image annotation involves assigning labels to help artificial intelligence (AI) models detect certain aspects within a visual representation. Different types of image annotation help represent different aspects of an image.
These concepts are used in many types of image annotation:
- Lines – lines can help annotate objects in an image to enable machines to identify boundaries.
- Polygons – polygons help annotate objects that are neither symmetric nor regular. It involves placing dots across the dimensions of an object and manually drawing lines along the object’s perimeter or circumference.
- Markers – some annotations involve placing markers on coordinates in the image that have special significance.
Image Classification
Image classification enables machines to objects in images and across an entire dataset. The classifier is trained on a labeled dataset, learning to classify new unseen images into the same set of labels.
The process of preparing images for image classification is commonly known as annotation or tagging. This involves adding tags that describe objects or scenes in the image – for example, you can tag exterior images of a building with labels like “fence” or “garden” and interior images of the building as “elevator” or “stairs”.
Object Recognition and Detection
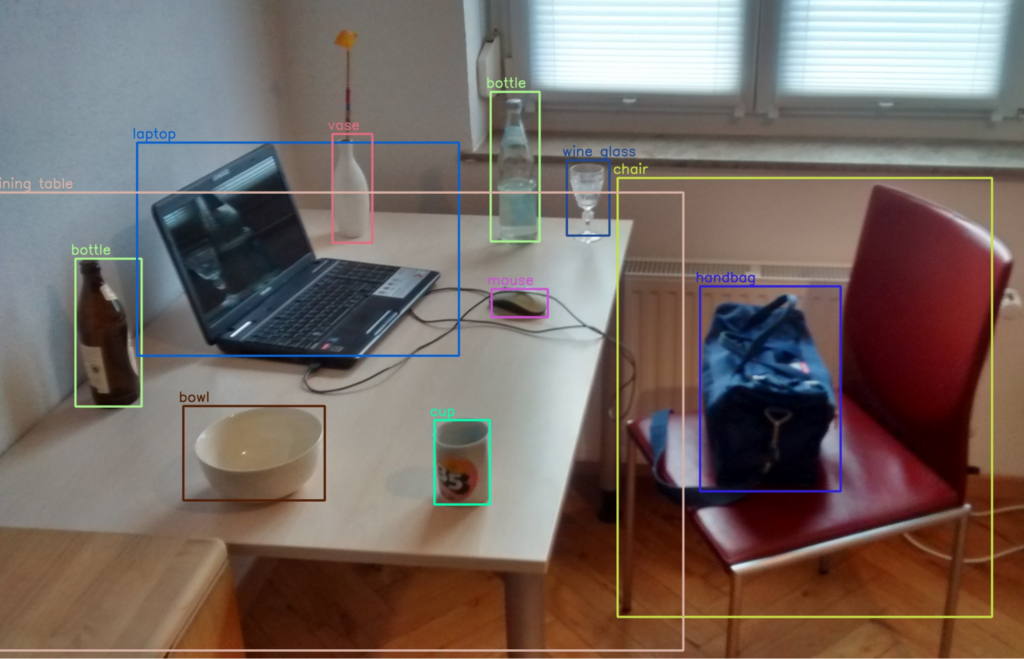
Object recognition, or object detection, enables machines to:
- Identify a particular object in an image and apply the accurate label.
- Identify the presence of multiple objects, including the number of instances and locations, and apply the accurate labels.
You can repeat this process using different image sets to train a machine learning model to autonomously identify and label these objects in new images. Object recognition-compatible techniques like polygons or bounding boxes can help you label different objects in a single image. For example, you can annotate cars, bikes, and pedestrians separately in one image.
Landmarking
Landmarking enables machine learning models to identify facial features, expressions, emotions, and gestures. This technique can also serve to mark the position and orientation of a human body.
For example, you can use data labels to mark specific locations on the face, like lips, eyebrows, eyes, and forehead, with specific numbers. Your machine learning model uses these marks to learn the different parts of a human face.
Image Segmentation

Image segmentation enables machines to locate boundaries and objects in an image. This technique achieves higher accuracy for classification tasks. Image segmentation involves dividing an image into several segments, assigning every pixel to specific classes or class instances.
Here are the three classes of image segmentation:
- Semantic segmentation—helps identify the boundaries between similar objects.
- Instance segmentation—helps identify and label each object in an image.
- Panoptic segmentation—uses semantic segmentation to produce data labeled for background and instance segmentation to label the objects in the image.
Boundary Recognition
Boundary recognition enables machines to identify the boundaries or lines of objects in an image. These boundaries can include:
- Regions of topography present in an image
- The edges of a specific object
An annotated image can help train your models to identify similar patterns in unlabeled images. Boundary recognition is particularly helpful in enabling self-driving cars to operate safely.
Challenges in the Image Annotation Process for Computer Vision
Here are notable challenges in the image annotation process:
Balancing costs with accuracy levels
There are two primary data annotation methods—human annotation and automated annotation. Human annotation typically takes longer and costs more than automated annotation, and also requires training for annotators, but achieves more accurate results. In comparison, automated annotation is more cost-effective but it can be difficult to determine the accuracy level of the results.
Guaranteeing consistent data
Machine learning models need a good quality of consistent data to make accurate predictions. However, data labelers may interpret subjective data differently due to their beliefs, culture, and personal biases. If data is labeled inconsistently, the results of a machine learning model will also be skewed.
Choosing a suitable annotation tool
There are many image annotation platforms and tools, each providing different capabilities for different types of annotations. The variety of offerings can make it difficult to choose the most suitable tools for each project. It can also be challenging to choose the right tool to match the skillsets of your workforce.
Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
