
























Image Segmentation: The Basics and 5 Key Techniques

What Is Image Segmentation?
Image segmentation is a method of dividing a digital image into subgroups called image segments, reducing the complexity of the image and enabling further processing or analysis of each image segment. Technically, segmentation is the assignment of labels to pixels to identify objects, people, or other important elements in the image.
A common use of image segmentation is in object detection. Instead of processing the entire image, a common practice is to first use an image segmentation algorithm to find objects of interest in the image. Then, the object detector can operate on a bounding box already defined by the segmentation algorithm. This prevents the detector from processing the entire image, improving accuracy and reducing inference time.
Image segmentation is a key building block of computer vision technologies and algorithms. It is used for many practical applications including medical image analysis, computer vision for autonomous vehicles, face recognition and detection, video surveillance, and satellite image analysis.
This is part of our series of articles about image annotation.
In This Article
How Does Image Segmentation Work?
Image segmentation is a function that takes image inputs and produces an output. The output is a mask or a matrix with various elements specifying the object class or instance to which each pixel belongs.
Several relevant heuristics, or high-level image features, can be useful for image segmentation. These features are the basis for standard image segmentation algorithms that use clustering techniques like edges and histograms.
An example of a popular heuristic is color. Graphics creators may use a green screen to ensure the image background has a uniform color, enabling programmatic background detection and replacement in post-processing.
Another example of a useful heuristic is contrast—image segmentation programs can easily distinguish between a dark figure and a light background (i.e., the sky). The program identifies pixel boundaries based on highly contrasting values.
Traditional image segmentation techniques based on such heuristics can be fast and simple, but they often require significant fine-tuning to support specific use cases with manually designed heuristics. They are not always sufficiently accurate to use for complex images. Newer segmentation techniques use machine learning and deep learning to increase accuracy and flexibility.
Machine learning-based image segmentation approaches use model training to improve the program’s ability to identify important features. Deep neural network technology is especially effective for image segmentation tasks.
There are various neural network designs and implementations suitable for image segmentation. They usually contain the same basic components:
- An encoder—a series of layers that extract image features using progressively deeper, narrower filters. The encoder might be pre-trained on a similar task (e.g., image recognition), allowing it to leverage its existing knowledge to perform segmentation tasks.
- A decoder—a series of layers that gradually convert the encoder’s output into a segmentation mask corresponding with the input image’s pixel resolution.
- Skip connections—multiple long-range neural network connections allowing the model to identify features at different scales to enhance model accuracy.
Types of Image Segmentation
There are various ways to segment an image. Here are some of the main techniques:
Semantic Segmentation

Source: Wikimedia Commons
{kind=link}
Semantic segmentation involves arranging the pixels in an image based on semantic classes. In this model, every pixel belongs to a specific class, and the segmentation model does not refer to any other context or information.
For example, semantic segmentation performed on an image with multiple trees and vehicles, will provide a mask that categorizes all types of trees into one class (tree) and all types of vehicles, whether they are buses, cars, or bicycles, into one class (vehicles).
This approach results in the problem statement being often poorly defined, especially if there are several instances grouped in the same class. For example, an image of a crowded street might segment the entire area of the crowd as the “people” class. The semantic segmentation does not provide in-depth detail into complex images like this.
Instance Segmentation

Source: ResearchGate
Instance segmentation involves classifying pixels based on the instances of an object (as opposed to object classes). Instance segmentation algorithms do not know which class each region belongs to—rather, they separate similar or overlapping regions based on the boundaries of objects.
For example, suppose an instance segmentation model processes an image of a crowded street. It should ideally locate individual objects within the crowd, identifying the number of instances in the image. However, it cannot predict the region or object (i.e., a “person”) for each instance.
Panoptic Segmentation

Source: Kharshit Kumar
{kind=link}
Panoptic segmentation is a newer type of segmentation, often expressed as a combination of semantic and instance segmentation. It predicts the identity of each object, segregating every instance of each object in the image.
Panoptic segmentation is useful for many products that require vast amounts of information to perform their tasks. For example, self-driving cars must be able to capture and understand their surroundings quickly and accurately. They can achieve this by feeding a live stream of images to a panoptic segmentation algorithm.
5 Image Segmentation Techniques
Here are some common image segmentation techniques.
1. Edge-Based Segmentation

Source: ResearchGate
{kind=link}
Edge-based segmentation is a popular image processing technique that identifies the edges of various objects in a given image. It helps locate features of associated objects in the image using the information from the edges. Edge detection helps strip images of redundant information, reducing their size and facilitating analysis.
Edge-based segmentation algorithms identify edges based on contrast, texture, color, and saturation variations. They can accurately represent the borders of objects in an image using edge chains comprising the individual edges.
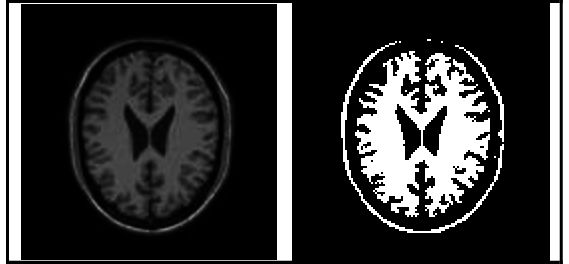
2. Threshold-Based Segmentation
Source: ResearchGate
{kind=link}
Thresholding is the simplest image segmentation method, dividing pixels based on their intensity relative to a given value or threshold. It is suitable for segmenting objects with higher intensity than other objects or backgrounds.
The threshold value T can work as a constant in low-noise images. In some cases, it is possible to use dynamic thresholds. Thresholding divides a grayscale image into two segments based on their relationship to T, producing a binary image.
3. Region-Based Segmentation
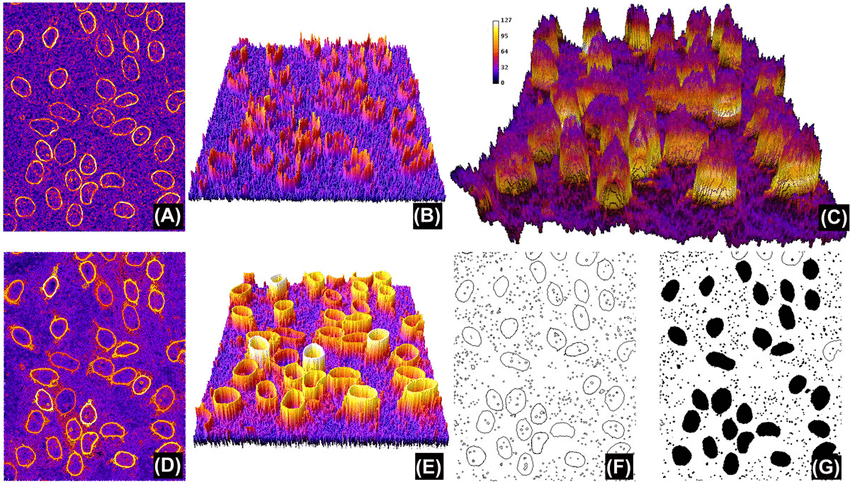
Source: ResearchGate
{kind=link}
Region-based segmentation involves dividing an image into regions with similar characteristics. Each region is a group of pixels, which the algorithm locates via a seed point. Once the algorithm finds the seed points, it can grow regions by adding more pixels or shrinking and merging them with other points.
4. Cluster-Based Segmentation
Clustering algorithms are unsupervised classification algorithms that help identify hidden information in images. They augment human vision by isolating clusters, shadings, and structures. The algorithm divides images into clusters of pixels with similar characteristics, separating data elements and grouping similar elements into clusters.
5. Watershed Segmentation
Watersheds are transformations in a grayscale image. Watershed segmentation algorithms treat images like topographic maps, with pixel brightness determining elevation (height). This technique detects lines forming ridges and basins, marking the areas between the watershed lines. It divides images into multiple regions based on pixel height, grouping pixels with the same gray value.
The watershed technique has several important use cases, including medical image processing. For example, it can help identify differences between lighter and darker regions in an MRI scan, potentially assisting with diagnosis.
Start your free trial now!
Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
