
























Image Labeling in Computer Vision: A Practical Guide

What is Image Labeling?
Image labeling is a type of data labeling that focuses on identifying and tagging specific details in an image.
In computer vision, data labeling involves adding tags to raw data such as images and videos. Each tag represents an object class associated with the data. Supervised machine learning models employ labels when learning to identify a specific object class in unclassified data. It helps these models associate meaning to data, which can help train a model.
Image annotation is used to create datasets for computer vision models, which are split into training sets, used to initially train the model, and test/validation sets used to evaluate model performance. Data scientists use the dataset to train and evaluate their model, and then the model can automatically assign labels to unseen, unlabelled data.
In This Article
Why is Image Labeling Important for AI and Machine Learning?
Image labeling is a key component of developing supervised models with computer vision capabilities. It helps train machine learning models to label entire images, or identify classes of objects within an image. Here are several ways in which image labeling helps:
- Developing functional artificial intelligence (AI) models—image labeling tools and techniques help highlight or capture specific objects in an image. These labels make images readable by machines, and highlighted images often serve as training data sets for AI and machine learning models.
- Improving computer vision—image labeling and annotation helps improve computer vision accuracy by enabling object recognition. Training AI and machine learning with labels helps these models identify patterns until they can recognize objects on their own.
Types of Computer Vision Image Labeling
Image labeling is a core function in computer vision algorithms. Here are a few ways computer vision systems label images. The end goal of machine learning algorithms is to achieve labeling automatically, but in order to train a model, it will need a large dataset of pre-labelled images.
Image Classification
Image classification algorithms receive images as an input and are able to automatically classify them into one of several labels (also known as classes). For example, an algorithm might be able to classify images of vehicles into labels like “car”, “train”, or “ship”.
In some cases, the same image might have multiple labels. In the example above, this could occur if the same image contains several types of vehicles.
Creating training datasets
To create a training dataset for image classification, it is necessary to manually review images and annotate them with labels used by the algorithm. For example, a training dataset for transportation images will include a large number of images containing vehicles, and a person would be responsible for looking at each image and applying the appropriate label—“car”, “train”, “ship”, etc. Alternatively, it is possible to generate such a dataset using synthetic data techniques.
Semantic Segmentation
In semantic image segmentation, a computer vision algorithm is tasked with separating objects in an image from the background or other objects. This typically involves creating a pixel map of the image, with each pixel containing a value of 1 if it belongs to the relevant object, or 0 if it does not.
If there are multiple objects in the same image, typically the approach is to create multiple pixel objects, one for each object, and concatenate them channel-wise.
Creating training datasets
To create a training dataset for a semantic segmentation dataset, it is necessary to manually review images and draw the boundaries of relevant objects. This creates a human-validated pixel map, which can be used to train the model. Alternatively, it is possible to generate pixel maps by creating synthetic images in which object boundaries are already known.
Object Detection
An object detection algorithm is tasked with detecting an object in an image and its location in the image frame. The location of objects are typically defined using bounding boxes. A bounding box is the smallest rectangle that contains the entire object in the image.
Technically, a bounding box is a set of four coordinates, assigned to a label which specifies the class of the object. The coordinates of bounding boxes and their labels are typically stored in a JSON file, using a dictionary format. The image number or ID is the key in the dictionary file.
The following image shows a scene with multiple bounding boxes denoting different objects.
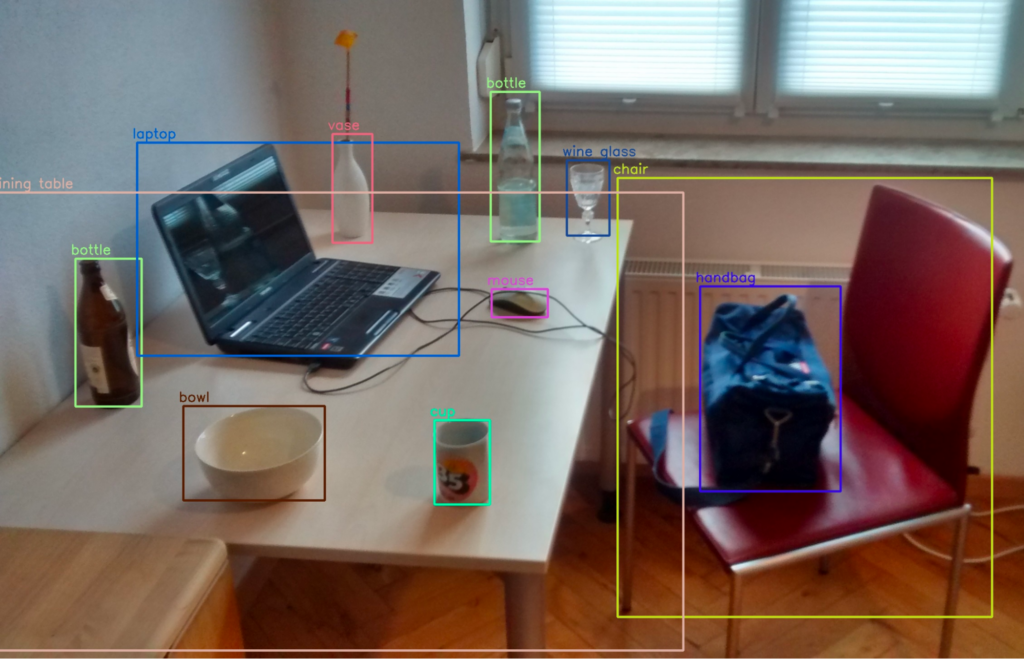
Image labeling is a type of data labeling that focuses on identifying and tagging specific details in an image.
Pose Estimation
A pose estimation algorithm is tasked with identifying the post of humans in an image. It attempts to detect several key points in the human body, and use them to understand the pose of the person in an image (for example, standing, sitting, or lying down).
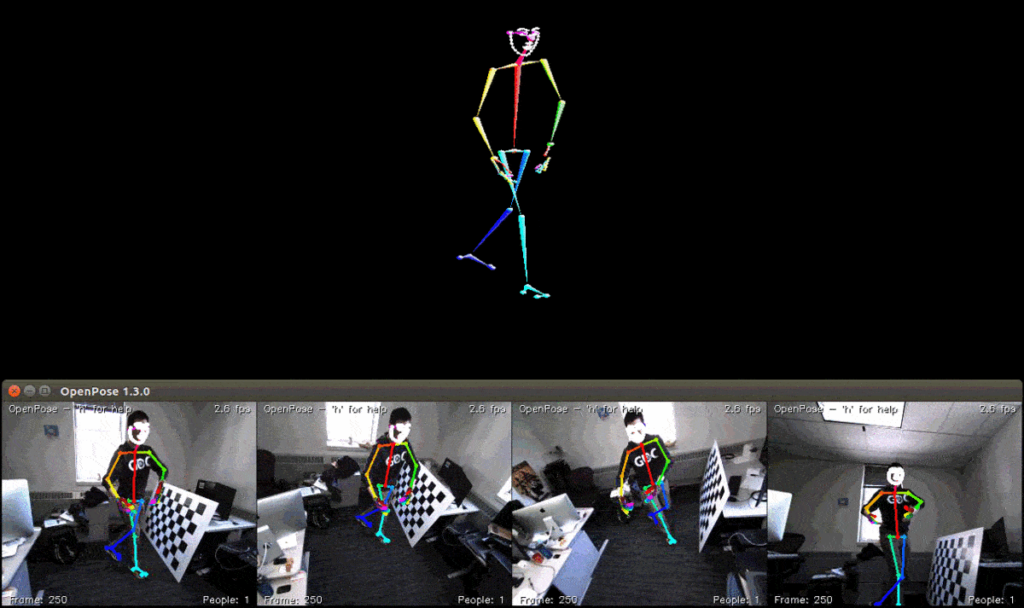
Creating training datasets
A training dataset for pose estimation contains images of people, with manual annotations indicating the key points of bodies appearing in the image. Technically, pose annotations are coordinates that are matched to labels, indicating which point in the human body is indicated (for example, the left hip). It is also possible to generate synthetic images of humans, in which the coordinates of key body points are already known.
Generate Synthetic Data with Our New Free Trial. Start now!
Methods of Image Labeling
Manual Image Annotations
A common way to label images is manual annotation. This is the process of manually defining labels for an entire image, or drawing regions in an image and adding textual descriptions of each region.
Image annotation sets a standard, which a computer vision algorithm tries to learn from. This means that any errors in labeling will be adopted by the algorithm, reducing its accuracy. This means that accurate image labeling is a critical task in training neural networks.
Manual annotation is typically assisted by tools that allow operators to rotate through a large number of images, draw regions on an image and assign labels, and save this data to a standardized format that can be used for data training.
Manual image annotation presents several challenges:
- Labels can be inconsistent if there are multiple annotators, and to resolve this, images need to be labeled several times with majority voting.
- Manual labeling is time consuming. Annotators must be meticulously trained and the process requires many iterations. This can delay time to market for computer vision projects.
- Manual labeling is costly and is difficult to scale to achieve large datasets.
Semi-Automated Image Annotations
Manual image annotation is a time-consuming task, and for some computer vision algorithms, can be difficult for humans to achieve. For example, some algorithms require creating pixel maps indicating the exact boundary of multiple objects in an image.
Automated annotation tools can assist manual annotators, by attempting to detect object boundaries in an image, and providing a starting point for the annotator. Automated annotation algorithms are not completely accurate, but they can save time for human annotators by providing at least a partial map of objects in the image.
Synthetic Image Labeling
Synthetic image labeling is an accurate and cost-effective technique which can replace manual annotations. It involves automatically generating images that are similar to real data, in accordance with criteria set by the operator. For example, it is possible to create a synthetic database of real-life objects or human faces, which are similar but not identical to real objects.
The main advantage of synthetic images is that labels are known in advance—for example, the operator automatically generates images containing tables and chairs. In this case, the algorithm generating the images can automatically provide the bounding boxes of the tables and chairs in each image.
There are three common approaches to generating synthetic images:
- Variational Autoencoders (VAE)—these are algorithms that start from existing data, create a new data distribution, and map it back to the original space using an encoder-decoder method.
- Generative Adversarial Networks (GAN)—these are models that pit two neural networks against each other. One neural network attempts to create fake images, while the other tries to distinguish real and fake images. Over time, the system becomes able to generate photorealistic images that are difficult to distinguish from real ones.
- Neural Radiance Fields (NeRF)—this model takes a series of images describing a 3D scene and automatically renders novel, additional viewpoints from the same scene. It works by computing a five-dimensional ray function to generate each voxel of the target image.
Generate Synthetic Data with Our New Free Trial. Start now!
Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
