
























GAN Deep Learning: A Practical Guide
What Is a Generative Adversarial Network (GAN)?
A Generative Adversarial Network (GAN) is a generative modeling method that automatically learns and discovers patterns in data inputs, generating plausible outputs based on the original dataset.
GANs can train generative models by emulating a supervised approach to learning problems. A GAN contains two sub-models that compete and feed off each other to produce more realistic outputs:
- The generator model—trained to generate new outputs.
- The discriminator model—classifies inputs as realistic or fake. It attempts to identify whether an input originates from the original dataset of the generator model.
This adversarial approach helps to improve the generator model’s capabilities until the discriminator model cannot distinguish between real and generated inputs.
In This Article
GAN Architecture
The architecture of a GAN consists of two main components. The generator is a neural network that generates data instances, and the discriminator attempts to determine their authenticity. The discriminator model decides if a data instance appears real (i.e., plausibly belongs to the original training data) or fake. The generator model attempts to fool the discriminator and trains on more data to produce plausible results.
This architecture is adversarial because the generator and discriminator work against each other with opposite objectives—one model tries to mimic reality while the other tries to identify fakes. These two components train simultaneously, improving their capabilities over time. They can learn to identify and reproduce complex training data such as image, audio, and video.
The following diagram represents an entire GAN architecture:
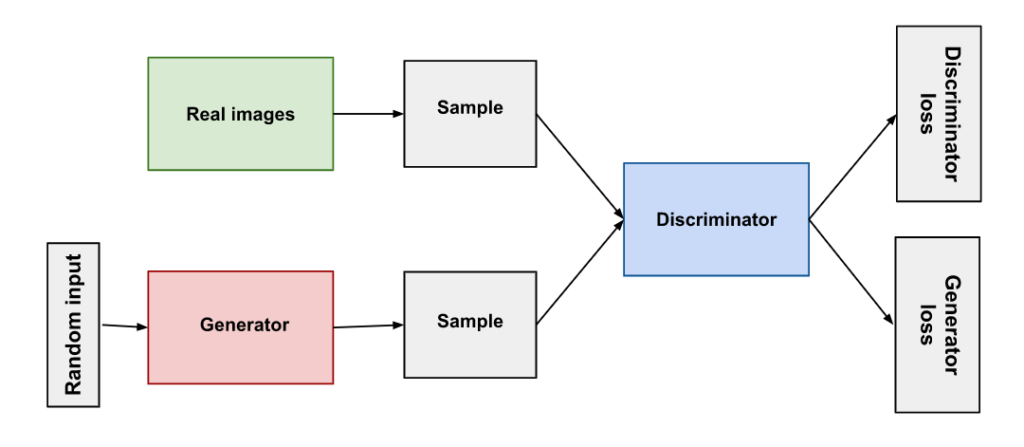
Image Source: developers.google.com
{kind=link}
A GAN uses this basic workflow:
- The generator ingests an input containing random numbers.
- The generator processes the input to produce an image.
- The discriminator ingests the image generated by the generator and additional, real images.
- The discriminator compares the entire image set and attempts to determine which images are real or fake.
- The discriminator returns a prediction for each image, using a number between 0 and 1 to express the probability of authenticity. A score of 0 indicates a fake image, while 1 indicates a real image.
This workflow creates a continuous feedback loop. The discriminator determines the ground truth (empirical truth) for image inputs, and the generator feeds the discriminator new and improved generated images.
GANs, Autoencoders and VAEs
Here is a comparison between GANs and other neural network models:
- GANs – starts from a random input and learns to create realistic synthetic data.
- Autoencoders – encode data inputs as vectors to create a compressed or hidden representation of the original data. Autoencoders are useful for reducing dimensionality. When used alongside decoders, they enable reconstruction of input data based on the associated vector.
- Variational Autoencoders (VAEs) – A VAE is a generative algorithm that adds additional constraints to encode data—it normalizes the hidden representations of the input data. VAEs are commonly used to synthesize data similar to a GAN.
GAN Applications and Use Cases
GANs can produce high-quality, realistic images that are indistinguishable from real photos. For some people, this ability to fake reality is a cause for concern, but generative technology has several important uses.
Various applications for the creation of realistic images include:
- Face recognition—the portrait generating capability can also help smartphones recognize their owners’ faces in different conditions.
- Pattern recognition—a GAN can produce new artwork matching a given artistic style.
- Content creation—a cGAN can generate various forms of content to fill in gaps in images or complete presentations. For example: adding facades to buildings, recreating natural landscapes, generating apparel, and rendering fully-furnished interiors.
- Virtual reality—the highly detailed HD virtual environments made possible by GANs are useful for simulations and gaming.
- Unstructured data search—when used with an unstructured data repository, a GAN can identify similar images based on compressed representations.
- Predictive imagery—GANs can be used to simulate aging in images of people.
- Text-based image generation—GANs can create new images based on the descriptions in a text. It is possible to train a GAN by labeling GAN-generated images using a supervised learning algorithm. The GAN can then use manually produced text to generate images that match the descriptions.

What is a Conditional GAN?
A Conditional Generative Adversarial Network (cGAN) is a type of GAN that generates images or other artifacts with conditional settings applied. Both the generator and the discriminator are conditioned on the same auxiliary information, such as class labels or input data.
A successful cGAN model can use this contextual information to learn multimodal mappings. For example, you can condition a cGAN model on a segmentation mask, to generate realistic images that match that mask.
The cGAN architecture has two advantages over traditional GAN. First, it converges faster, because it doesn’t start from a completely random distribution. Second, it makes it possible to control the output of the generator by providing a label for the images that the model is expected to generate.
A simple example of cGAN is a GAN model that generates handwritten letters. In a traditional GAN, there is no control over which specific letter the model will generate. However, in a cGAN, you can add an input layer with one-hot encoded image labels, or a feature vector derived from the specific letters the model needs to generate. This guides the model to generate those specific letters.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
