
























Convolutional Neural Network: Benefits, Types, and Applications

In This Article
What Are Convolutional Neural Networks (CNNs)?
A Convolutional Neural Network (CNN) is a type of deep learning algorithm specifically designed for image processing and recognition tasks. Compared to alternative classification models, CNNs require less preprocessing as they can automatically learn hierarchical feature representations from raw input images. They excel at assigning importance to various objects and features within the images through convolutional layers, which apply filters to detect local patterns.
The connectivity pattern in CNNs is inspired by the visual cortex in the human brain, where neurons respond to specific regions or receptive fields in the visual space. This architecture enables CNNs to effectively capture spatial relationships and patterns in images. By stacking multiple convolutional and pooling layers, CNNs can learn increasingly complex features, leading to high accuracy in tasks like image classification, object detection, and segmentation.
Convolutional Neural Network Architecture Model
Convolutional neural networks are known for their superiority over other artificial neural networks, given their ability to process visual, textual, and audio data. The CNN architecture comprises three main layers: convolutional layers, pooling layers, and a fully connected (FC) layer.
There can be multiple convolutional and pooling layers. The more layers in the network, the greater the complexity and (theoretically) the accuracy of the machine learning model. Each additional layer that processes the input data increases the model’s ability to recognize objects and patterns in the data.
The Convolutional Layer
Convolutional layers are the key building block of the network, where most of the computations are carried out. It works by applying a filter to the input data to identify features. This filter, known as a feature detector, checks the image input’s receptive fields for a given feature. This operation is referred to as convolution.
The filter is a two-dimensional array of weights that represents part of a 2-dimensional image. A filter is typically a 3×3 matrix, although there are other possible sizes. The filter is applied to a region within the input image and calculates a dot product between the pixels, which is fed to an output array. The filter then shifts and repeats the process until it has covered the whole image. The final output of all the filter processes is called the feature map.
The CNN typically applies the ReLU (Rectified Linear Unit) transformation to each feature map after every convolution to introduce nonlinearity to the ML model. A convolutional layer is typically followed by a pooling layer. Together, the convolutional and pooling layers make up a convolutional block.
Additional convolution blocks will follow the first block, creating a hierarchical structure with later layers learning from the earlier layers. For example, a CNN model might train to detect cars in images. Cars can be viewed as the sum of their parts, including the wheels, boot, and windscreen. Each feature of a car equates to a low-level pattern identified by the neural network, which then combines these parts to create a high-level pattern.
The Pooling Layers
A pooling or downsampling layer reduces the dimensionality of the input. Like a convolutional operation, pooling operations use a filter to sweep the whole input image, but it doesn’t use weights. The filter instead uses an aggregation function to populate the output array based on the receptive field’s values.
There are two key types of pooling:
- Average pooling: The filter calculates the receptive field’s average value when it scans the input.
- Max pooling: The filter sends the pixel with the maximum value to populate the output array. This approach is more common than average pooling.
Pooling layers are important despite causing some information to be lost, because they help reduce the complexity and increase the efficiency of the CNN. It also reduces the risk of overfitting.
The Fully Connected Layer
The final layer of a CNN is a fully connected layer.
The FC layer performs classification tasks using the features that the previous layers and filters extracted. Instead of ReLu functions, the FC layer typically uses a softmax function that classifies inputs more appropriately and produces a probability score between 0 and 1.
Benefits of Using CNNs for Machine and Deep Learning
Deep learning is a form of machine learning that requires a neural network with a minimum of three layers. Networks with multiple layers are more accurate than single-layer networks. Deep learning applications often use CNNs or RNNs (recurrent neural networks).
The CNN architecture is especially useful for image recognition and image classification, as well as other computer vision tasks because they can process large amounts of data and produce highly accurate predictions. CNNs can learn the features of an object through multiple iterations, eliminating the need for manual feature engineering tasks like feature extraction.
It is possible to retrain a CNN for a new recognition task or build a new model based on an existing network with trained weights. This is known as transfer learning. This enables ML model developers to apply CNNs to different use cases without starting from scratch.
Types of Convolutional Neural Network Algorithms
LeNet
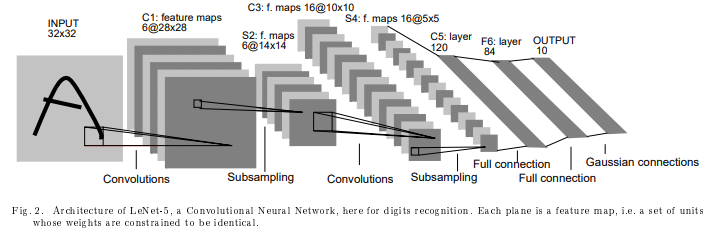
LeNet is a pioneering CNN designed for recognizing handwritten characters. It was proposed by Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner in the late 1990s. LeNet consists of a series of convolutional and pooling layers, as well as a fully connected layer and softmax classifier. It was among the first successful applications of deep learning for computer vision. It has been used by banks to identify numbers written on cheques in grayscale input images.
VGG
VGG (Visual Geometry Group) is a research group within the Department of Engineering Science at the University of Oxford. The VGG group is well-known for its work in computer vision, particularly in the area of convolutional neural networks (CNNs).
One of the most famous contributions from the VGG group is the VGG model, also known as VGGNet. The VGG model is a deep neural network that achieved state-of-the-art performance on the ImageNet Large Scale Visual Recognition Challenge in 2014, and has been widely used as a benchmark for image classification and object detection tasks.
The VGG model is characterized by its use of small convolutional filters (3×3) and deep architecture (up to 19 layers), which enables it to learn increasingly complex features from input images. The VGG model also uses max pooling layers to reduce the spatial resolution of the feature maps and increase the receptive field, which can improve its ability to recognize objects of varying scales and orientations.
The VGG model has inspired many subsequent research efforts in deep learning, including the development of even deeper neural networks and the use of residual connections to improve gradient flow and training stability.
Learn more in our detailed guide to VGG16
AlexNet
AlexNet won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012, with a significant margin of error reduction compared to the previous state-of-the-art model – down to 15% from 26%. It was designed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton at the University of Toronto.
AlexNet consists of five convolutional layers with max pooling, and three FC layers, with ReLU activation functions used throughout. In addition to 3×3 filters, it also has 5×5 and 11×11 convolutional filters.
The network uses a dropout technique to reduce overfitting, and employs data augmentation methods to increase the effective size of the training set. AlexNet’s success demonstrated the power of deep learning methods in computer vision and led to a surge of interest in the field. It also popularized the use of GPUs for accelerating the training of deep neural networks.

ResNet
ResNet (short for “Residual Neural Network”) is a family of deep convolutional neural networks designed to overcome the problem of vanishing gradients that are common in very deep networks. The idea behind ResNet is to use “residual blocks” that allow for the direct propagation of gradients through the network, enabling the training of very deep networks.
A residual block consists of two or more convolutional layers followed by an activation function, combined with a shortcut connection that bypasses the convolutional layers and adds the original input directly to the output of the convolutional layers after the activation function.
This allows the network to learn residual functions that represent the difference between the convolutional layers’ input and output, rather than trying to learn the entire mapping directly. The use of residual blocks enables the training of very deep networks, with hundreds or thousands of layers, significantly alleviating the issue of vanishing gradients.
Learn more in our detailed guides to:
GoogLeNet
GoogLeNet is a deep convolutional neural network developed by researchers at Google. It was introduced in 2014 and won the ILSVRC (ImageNet Large-Scale Visual Recognition Challenge) that year, with a top-five error rate of 6.67%.
GoogLeNet is notable for its use of the Inception module, which consists of multiple parallel convolutional layers with different filter sizes, followed by a pooling layer, and concatenation of the outputs. This design allows the network to learn features at multiple scales and resolutions, while keeping the computational cost manageable. The network also includes auxiliary classifiers at intermediate layers, which encourage the network to learn more discriminative features and prevent overfitting.
GoogLeNet builds upon the ideas of previous convolutional neural networks, including LeNet, which was one of the first successful applications of deep learning in computer vision. However, GoogLeNet is much deeper and more complex than LeNet.

MobileNet
MobileNet is a family of convolutional neural networks designed for mobile and embedded devices. They are optimized for efficiency and speed, while still achieving high accuracy in tasks such as image recognition. One of the key features of MobileNet is the use of pointwise and depthwise convolutions.
Depthwise convolutions use a single filter for each input channel independently, and are followed by pointwise convolutions that combine the output channels from depthwise convolutions using 1×1 convolutions. This approach greatly reduces the number of computations and parameters required, while still capturing meaningful features of the input data.
This makes MobileNet models much smaller and faster than traditional convolutional neural networks, making them ideal for use in resource-constrained environments such as smartphones, drones, and IoT devices.

R-CNN
R-CNN (Region-based Convolutional Neural Network) was introduced in 2013, and is a two-stage approach to object detection. First, the input image is segmented into regions of interest (ROIs) using selective search, a computationally expensive algorithm that generates region proposals based on image texture, color, and other features. Then, each ROI is passed through a CNN that produces a fixed-length feature vector. The CNN used in R-CNN is usually a pretrained network, such as AlexNet or VGG.
These feature vectors are used to classify the object contained in the ROI and predict its bounding box coordinates. While R-CNN achieved cutting-edge results at the time, it was very slow to train and test, due to the need to process thousands of region proposals for each image.
R-CNN is part of a series of object detection models, alongside Fast R-CNN and Faster R-CNN, which were developed by researchers at UC Berkeley and Microsoft Research, and represent a significant improvement over earlier methods for object detection.

Fast R-CNN
Fast R-CNN, introduced in 2015, improved on R-CNN by eliminating the need for a separate feature extraction step for each region proposal. Instead, the entire image is passed through the CNN, producing a feature map that is shared by all the region proposals. Each ROI is then pooled into a feature map with a fixed size through an operation called “Region of Interest (ROI) Pooling”, and passed through a sequence of FC layers to produce the final bounding box and classification predictions.
This approach is much faster and more accurate than R-CNN, and also allows for end-to-end training of the entire model.

Faster R-CNN
Faster R-CNN, introduced in 2015, further improved on Fast R-CNN by replacing selective search with an RPN (Region Proposal Network), which is a small convolutional network that generates region proposals directly from the feature map produced by the CNN. The RPN shares the same convolutional layers as the object detection network, making the entire model more efficient and easier to train.
The RPN predicts objectness scores and bounding box coordinates for each anchor point in the feature map, and these proposals are then refined and classified by the object detection network. This approach is even faster and more accurate than Fast R-CNN, and has become the de facto standard for object detection in many applications.

Business Applications of a Convolutional Neural Network
Image Classification
Image classification is a major business application of convolutional neural networks (CNNs) because it enables computers to automatically categorize and understand visual content, which has numerous applications in a wide range of industries.
One of the most common applications of image classification is image tagging, which involves assigning labels or tags to images based on their content. This is used in many online platforms such as social media, eCommerce, and photo-sharing websites to help users find relevant content and improve their search experience.
Recommender Systems
Another application of CNN is recommendation engines, which use image data to recommend products or services to customers. For example, an eCommerce platform can use image classification to recommend clothing items that match a customer’s style or preferences.
Image Retrieval
This is another application of image classification, which allows users to search for images based on their visual content rather than text-based search terms. This is particularly useful in industries such as fashion, where users may be looking for items that match a particular style or color scheme.
Other applications of image classification include object detection, where the goal is to identify and locate objects within an image, and semantic segmentation, where the goal is to assign a label to each pixel in an image. These applications have many use cases, such as in self-driving cars, security and surveillance, and medical imaging.
Face Recognition
Face recognition is a subset of image recognition that specifically focuses on detecting and identifying human faces within images or videos. In social media, face recognition is often used for features such as tagging friends in photos or videos, as well as for security and account verification purposes.
Optical Character Recognition
Optical character recognition (OCR) is a technology that enables the digital recognition and interpretation of printed or handwritten text from images, scanned documents, or other sources. OCR algorithms typically use machine learning techniques, such as convolutional neural networks, to analyze the shape and structure of individual characters, and then use these patterns to recognize and transcribe the text.
OCR has numerous applications in fields such as document management, digital archiving, and data entry, where it can be used to automate the process of converting paper documents into searchable, editable digital text. OCR is also commonly used in automated systems for processing forms and invoices, as well as in the creation of ebooks and digital libraries.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
