
























Generative Adversarial Networks: the Basics and 4 Popular GAN Extensions

What Is a Generative Adversarial Network (GAN)?
Generative Adversarial Networks (GANs) is a class of machine learning frameworks originally proposed by Ian J. Goodfellow et. al, in 2014. A GAN consists of two neural networks competing against each other, with the objective of creating fake artifacts that are indistinguishable from real artifacts.
Given a training set, a GAN architecture learns to generate new data with the same underlying characteristics as the training set. GANs were originally proposed as generative models for unsupervised learning and have also proven useful in semi-supervised learning, fully supervised learning, and reinforcement learning.
The core idea of a GAN is the use of a “generator” and a “discriminator” to facilitate indirect training. The generator learns to create more realistic data samples, while the discriminator learns to distinguish real samples from fake ones created by the generator. Over thousands of rounds of training, the system becomes very effective at generating highly realistic new samples resembling the original dataset.
This is part of an extensive series of guides about machine learning.
In This Article
What Can GAN Be Used For?
Generative Adversarial Networks have fewer business-critical applications than other deep learning models, but they can be used to create or extend visual artifacts in a variety of use cases. Notable applications of GANs include:
- Data augmentation—GAN can be trained to generate new sample images from existing data to expand a data set. When the GAN has matured, its output images can be used to train other computer vision models.
- Text to image—GAN is used to create comics and video footage by automatically generating image sequences from text input.
- Face generation—in an NVIDIA research paper (Karras et. al, 2018), researchers trained a GAN using a large-scale celebrity face database, creating realistic images of people who don’t really exist.
- Image-to-image translation—GANs can learn to map patterns from an input image to an output image. For example, it can be used to transform an image into a specific artistic style ( known as style transfer), to age the image of a person, or for many other image transformations.
- Industrial design and architecture—GANs can be used to create new 3D product designs based on existing products. For example, a GAN can be trained to create new furniture designs or propose new architectural styles.
Overview of GAN Architecture
A Generative Adversarial Network (GANs) has two key components—the generator and the discriminator, both of which are deep neural networks.
Discriminator
A GAN discriminator is a classifier. It distinguishes between real data and data generated by a GAN generator. It can use any network architecture suitable for the type of data that needs to be generated by the GAN.
The discriminator trains on two types of data. The first is real-world data, such as real pictures of animals. These are treated by the discriminator as ground truth labels of what a “real” artifact looks like. The second is artifacts created by the generator. These are used as ground truth labels of what a “fake” artifact looks like.
The discriminator training process works as follows:
- The discriminator classifies real and fake data received from the generator.
- The discriminator computes a loss function that penalizes it for misclassifying a real artifact as fake or a fake artifact as real.
- The discriminator updates its weights by backpropagating to minimize the discriminator loss—without being aware of the generator loss function.
Generator
The generator part of the GAN learns to incorporate the discriminator’s feedback to generate fake data. Its goal is to cause the discriminator to classify its fake output as real.
An important question is the initial data used by the generator. All neural networks need to start from some input.
In its basic form, a GAN takes random noise as input (a common choice is a normal distribution). The generator then transforms this noise into artifacts in the format required by the user.
By introducing noise, the GAN can generate many variations on the data, by sampling at different locations in the target distribution. More advanced GAN architectures use specific inputs to help the network train faster and more effectively.
Generator training works as follows:
- The generator accepts its initial input, typically random noise, and transforms it into meaningful output.
- The discriminator provides a classification for the output, classifying it either as real or fake.
- The discriminator calculates its loss function.
- Backpropagation is performed through both discriminator and generator networks to obtain gradients.
- These gradients are used to adjust only the weights of the generator, so that the generated content will be more likely to fool the discriminator next time.
Training a GAN
Since GANs consist of two networks trained separately, the training algorithm must solve a complex problem. A GAN needs to coordinate two training components: a generator and a discriminator. GAN convergence can be difficult to identify.
Generators and discriminators have different training procedures, so it is not obvious how GAN training works as a unit.
Training a GAN involves the following phases:
- A discriminator trains for a set period.
- A generator trains for a set period.
- The model repeats the first two steps to continue training the generator and discriminator networks against each other.
The generator must remain constant throughout the discriminator’s training phase. The discriminator training process involves distinguishing between real and fake data, so it must also learn to identify the generator’s defects. Fully trained generators present a different challenge from untrained generators, which produce random outputs.
Likewise, the discriminator must remain constant throughout the generator’s training phase to allow the generator to tackle a consistent target. With this iterative feedback loop, the GAN can solve complex problems. This process should start with simple classification problems and gradually introduce harder generation problems.
Suppose the initial training phase, using a randomly generated output, fails to train the classifier to distinguish between generated and real data. In that case, it is not possible to progress with the GAN training. The generator improves during training and impacts the discriminator’s performance because it becomes harder to distinguish between genuine and fake inputs. If the generator is completely successful, the discriminator is 50% accurate. The discriminator makes a coin-toss prediction.
This process can lead to convergence problems for the overall GAN. In other words, the discriminator’s feedback loses meaning over time. If the GAN continues to train beyond the point where the discriminator can only provide random feedback, the generator starts training on meaningless feedback, degrading the generator’s quality in turn.
Convergence is usually a transient, short-lived state for GANs rather than a stable state.
Simple Example of a GAN Architecture: StyleGAN
The StyleGAN algorithm was designed to blend the style of one image with the content of another image. The style represents properties of generated images, including background, foreground, textures, and fine-grained details of objects in the image. It generates layers of images going progressively from low-resolution to high-resolution outputs. A coarse image layer identifies the subject’s silhouette and position, a middle layer can determine facial expressions and hairstyles, and a fine image layer can identify detailed features.
The StyleGAN extends the progressive GAN approach used to train generator models to synthesize large, high-quality images. It uses the incremental expansion of generator and discriminator models in the training process from small to large images. It also alters the generator architecture.
The StyleGAN uses two sources—a noise layer and a mapping network—to generate images from a latent space point. The mapping network’s output defines the styles the generator integrates through an adaptive instance normalization layer. The style vector controls the synthetic image’s style.
The model introduces stochastic variation by adding noise at each generator point. This noise applies to whole feature maps to enable highly granular style interpretation. Incorporating the style vector at each block helps control the level of detail.
The StyleGAN differs from other progressive expansion models by introducing five new features to the baseline progressive GAN:
- Bilinear upsampling and tuning.
- Styles (AdaIN) and mapping network.
- Elimination of latent vector input.
- Noise added per block.
- Mixing regularization.
The following diagram outlines the StyleGAN architecture:
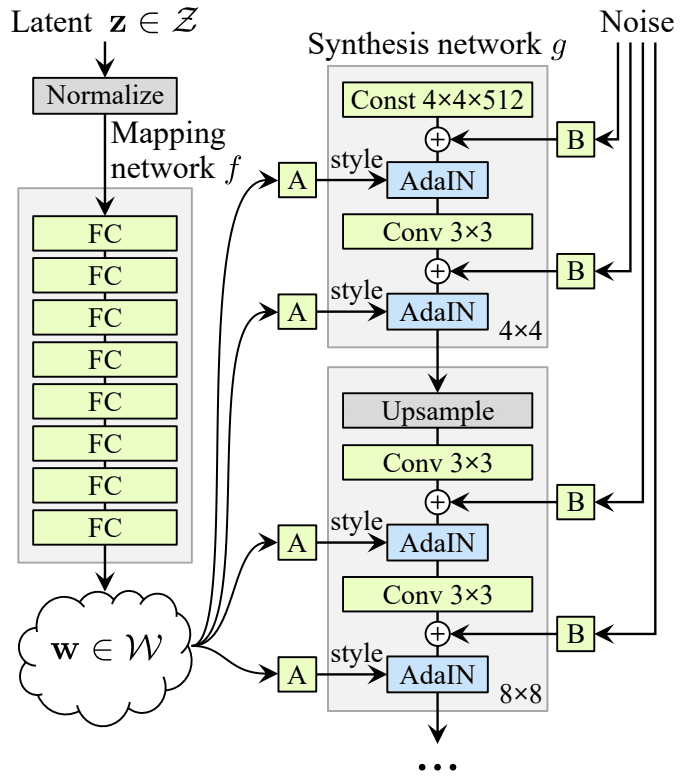
Source: Arxiv.org
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
