
























ResNet: The Basics and 3 ResNet Extensions
What Is Residual Neural Network (ResNet)?
Residual Network (ResNet) is a deep learning model used for computer vision applications. It is a Convolutional Neural Network (CNN) architecture designed to support hundreds or thousands of convolutional layers. Previous CNN architectures were not able to scale to a large number of layers, which resulted in limited performance. However, when adding more layers, researchers faced the “vanishing gradient” problem.
Neural networks are trained through a backpropagation process that relies on gradient descent, shifting down the loss function and finding the weights that minimize it. If there are too many layers, repeated multiplications will eventually reduce the gradient until it “disappears”, and performance saturates or deteriorates with each layer added.
ResNet provides an innovative solution to the vanishing gradient problem, known as “skip connections”. ResNet stacks multiple identity mappings (convolutional layers that do nothing at first), skips those layers, and reuses the activations of the previous layer. Skipping speeds up initial training by compressing the network into fewer layers.
Then, when the network is retrained, all layers are expanded and the remaining parts of the network—known as the residual parts—are allowed to explore more of the feature space of the input image.
Most ResNet models skip two or three layers at a time with nonlinearity and batch normalization in between. More advanced ResNet architectures, known as HighwayNets, can learn “skip weights”, which dynamically determine the number of layers to skip.
In This Article
What Is a Residual Block?
Residual blocks are an important part of the ResNet architecture. In older architectures such as VGG16, convolutional layers are stacked with batch normalization and nonlinear activation layers such as ReLu between them. This method works with a small number of convolutional layers—the maximum for VGG models is around 19 layers. However, subsequent research discovered that increasing the number of layers could significantly improve CNN performance.
The ResNet architecture introduces the simple concept of adding an intermediate input to the output of a series of convolution blocks. This is illustrated below.
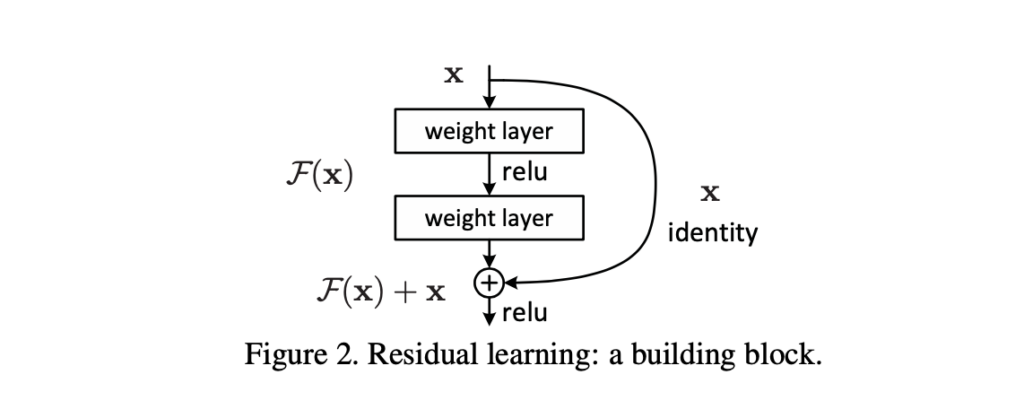
Source: Arxiv.org
The image above shows a typical residual block. This can be expressed in Python code using the expression output = F(x) + x where x is an input to the residual block and output from the previous layer, and F(x) is part of a CNN consisting of several convolutional blocks.
This technique smooths out the gradient flow during backpropagation, enabling the network to scale to 50, 100, or even 150 layers. Skipping a connection does not add additional computational load to the network.
This technique of adding the input of the previous layer to the output of a subsequent layer is now very popular, and has been applied to many other neural network architectures including UNet and Recurrent Neural Networks (RNN).

Variants of ResNet
ResNeXt
ResNeXt is an alternative model based on the original ResNet design. It uses the building block illustrated below:
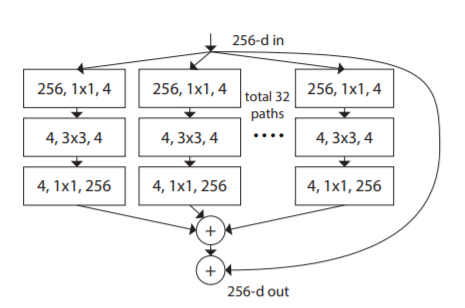
Image Source: Arxiv.org
The ResNeXt model incorporates the ResNet strategy of repeating layers but introduces an extensible, simple way to implement the split, transform, and merge strategy. The building block resembles the Inception network that supports various transformations such as different 1×1 Conv, 3×3 Conv, 5×5 Conv, and MaxPooling. However, while these transformations are stacked together in the Inception model, the ResNeXt model adds and merges them.
This model adds another dimension of cardinality in the form of the independent path number. It also includes existing depth and height dimensions. The authors experimentally demonstrated the importance of the added dimension for increasing accuracy. Increased cardinality helps the network go wider or deeper, especially if the width and depth dimensions produce diminished returns for standard models.
There are three variations of the proposed ResNeXt building block:
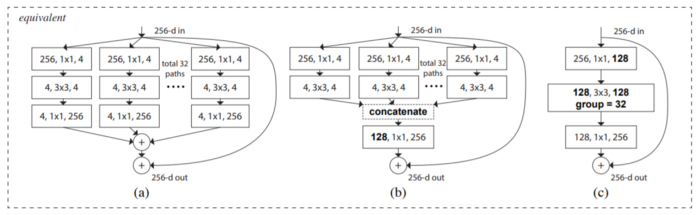
Image Source: Arxiv.org
The authors of ResNeXt claim it is an easy-to-train model compared to the Inception network because it is trainable over multiple datasets. It contains a single adjustable hyperparameter, unlike Inception’s multiple hyperparameters.
DenseNet
DenseNet is another popular ResNet variation, which attempts to resolve the issue of vanishing gradients by creating more connections. The authors of DenseNet ensured the maximum flow of information between the network layers by connecting each layer directly to all the others. This model preserves the feed-forward capabilities by allowing every layer to obtain additional inputs from its preceding layers and pass on the feature map to subsequent layers.
Here is an illustration of the model:
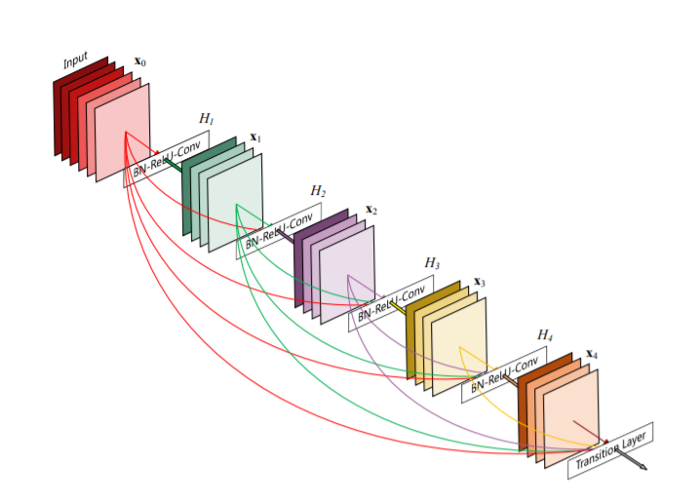
Image Source: Arxiv.org
In addition to addressing the vanishing gradient problem, the DenseNet authors also claim that the implementation lets the network reuse features. This approach is thus more parameter efficient than traditional networks, where every layer behaves as a separate state, reading from one preceding state and writing to one subsequent layer. The standard convolution network model modifies the state and forwards important data.
On the other hand, the DenseNet model clearly distinguishes between preserved and newly added information. A final classifier uses all the network’s feature maps to make decisions, enabling more efficient parameter usage and providing a more effective flow of information. The network is thus easier to train.
The compactness of the DenseNet’s internal representations, combined with its ability to reduce feature redundancy, makes it useful for extracting features for a computer vision task that relies on convolutional features.
Wide ResNet
Wide ResNet is a newer, improved version of the original Deep ResNet model. It allows users to make the network wider or shallower without impacting performance. It does not rely on depth increases to enhance network accuracy. First introduced in a 2016 paper called “Wide Residual Networks,” this model has since been updated (for example, in 2017).
Deep residual networks are highly accurate and can help machines perform various tasks easily, such as image recognition. However, deep networks continue to face the issues resulting from vanishing or exploding gradients and general degradation. A deep ResNet does not guarantee the inclusion of all residual blocks in operations—in some cases, the model might skip several blocks, or a limited number of residual blocks reach the larger contributing block.
The Wide ResNet authors sought to disable random blocks to tackle this issue. They have demonstrated that a wider network can offer higher performance than a deeper network.
The Wide ResNet architecture consists of a stack of ResNet blocks, with each ResNet block following the BatchNormalization-ReLU-Conv structure. Here is an illustration of this structure:
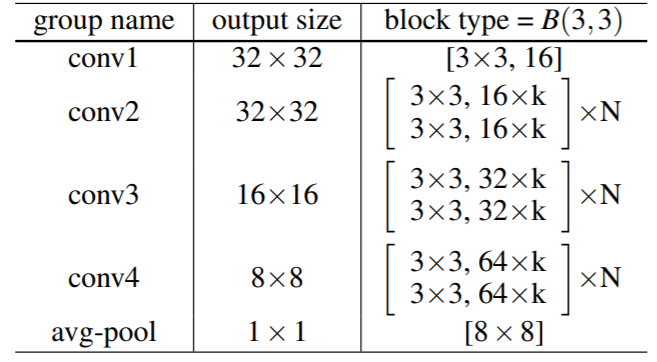
Image Source: Arxiv.org
A wide ResNet consists of five stacks or groups. The residual block in question is type B(3, 3). The conv1 group remains intact in all networks, while the other convolutional groups vary based on the k value defining the network’s width. An average-pool layer follows the convolutional group, along with a classification layer.
It is possible to adjust these variable measures to produce different representations of the residual blocks:
- Convolution type—the above example uses B(3, 3), consisting of 3X3 convolutional layers. Alternative options include, for example, integrating 3X3 convolutions with a 1X1 convolutional layer.
- Convolutions per block—this metric determines the block’s depth by evaluating its dependency on the model’s performance.
- Residual block width—regularly checking the depth and width of each residual block is important to track performance and computational complexity.
- Dropout layer—there should be an added dropout layer between each convolution in each residual block to prevent overfitting.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
