
























Semantic Segmentation: A Quick Guide

What is Semantic Segmentation?
Semantic segmentation takes the basic task of image classification one step further. Image classification involves assigning a label to an entire image (for example, identifying that it is an image of a dog, cat, or horse). However, naive image classification is limited in real-world computer vision applications, because most images contain more than one object.
This creates the need to divide an image into regions, and classify each region separately. The process of dividing the image into regions is called segmentation. Segmentation is the basis of one of the most critical tasks in computer vision – object detection. It plays an essential role in AI systems used in self-driving cars, medical image diagnosis, and many other use cases that impact our daily lives.
Semantic segmentation is a type of segmentation that treats multiple objects of the same type or class as a single entity. For example, semantic segmentation might indicate the pixel boundaries of all the people in the image, or all the cars in the image. This is in contrast to instance segmentation, which aims to identify each individual object in a given class.
Modern image segmentation techniques are based on deep learning. We’ll discuss three segmentation techniques – region-based semantic segmentation, segmentation based on fully convolutional networks (FCN), and weakly supervised semantic segmentation.
This is part of our series of articles about image annotation.
In This Article
Semantic Segmentation vs. Instance Segmentation
There are two main types of image segmentation, both of which form the basis for object recognition in computer vision projects:
- Semantic segmentation—objects displayed in the image are grouped according to predefined classes or categories. For example, a city scene can be divided into pedestrians, vehicles, roads, buildings, etc.
- Instance segmentation—identifies specific entities within a class. For example, if semantic segmentation identifies all the pedestrians in the image, instance segmentation can identify individual pedestrians.
- Panoptic segmentation—combines predictions from instance and semantic segmentation into a single, unified output.

Real-world Applications of Semantic Segmentation
1. Self-driving Cars
Autonomous vehicles need to visualize their environment, make decisions, and navigate accordingly. Semantic segmentation makes it possible for an autonomous vehicle to efficiently differentiate between objects.
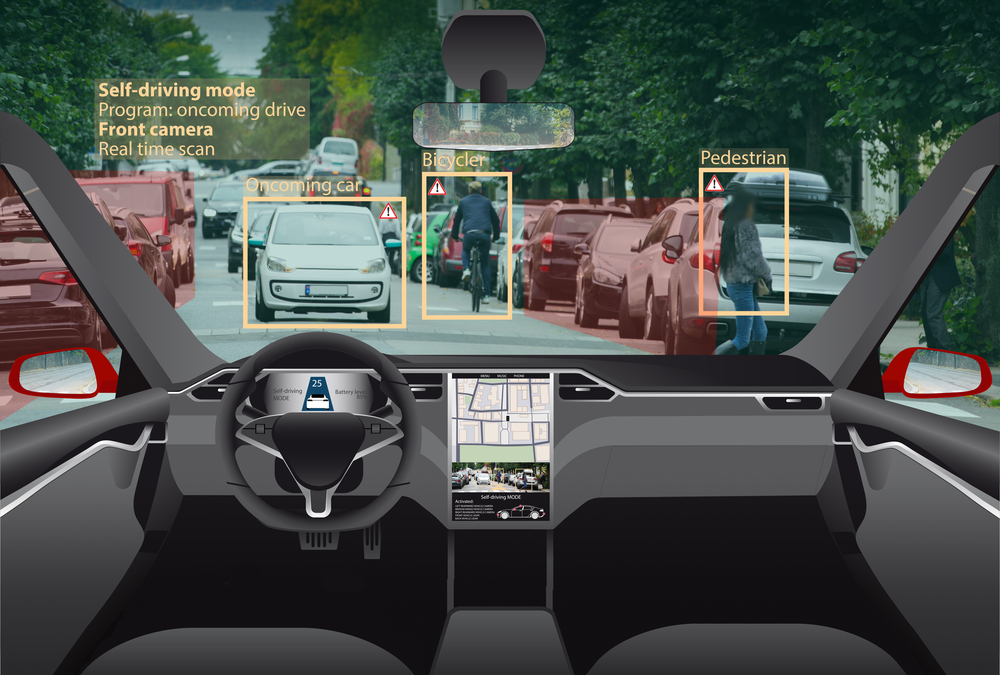
For example, a segmentation mask that classifies pedestrians crossing a road can be used to identify when the car should stop and allow passage. A segmentation mask that classifies road and lane markings can help the car move along a specific track.
2. Retail Image Analysis
Retail image analysis helps businesses understand how goods are displayed on shelves. Algorithms analyze images of store shelves and attempt to identify if products are missing or not. If a product is missing, the software issues an alert and the organization can determine the cause, inform sellers and suggest corrective action for affected parts of the supply chain.

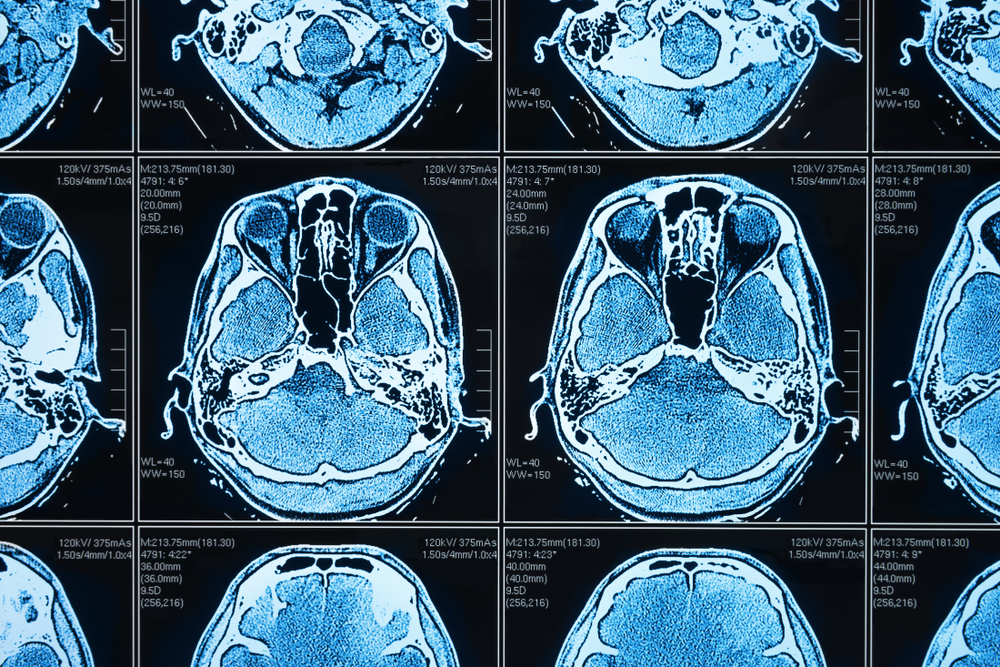
3. Medical Image Diagnosis
Semantic segmentation has many applications in medical imaging. For example, radiologists have found semantic segmentation algorithms effective at classifying CT scan abnormalities, which can be difficult for human radiologists to identify. Semantic segmentation can serve as a diagnostic tool that helps medical practitioners identify important elements in images and use them to make better patient care decisions.
4. Robotics
Robots need to map and interpret the scene they are viewing in order to do their job more efficiently. The pixel-level understanding provided by semantic segmentation helps robots better navigate the workspace. Many fields of robotics can benefit from image segmentation, from service robots and industrial robots to agricultural robots.
Deep Learning Semantic Segmentation Methods
A typical semantic segmentation architecture consists of an encoder network followed by a decoder network:
- Encoders are typically pre-trained classification networks such as VGG/ResNet.
- Decoders have the task of semantically projecting the low-resolution features learned by the encoder onto a pixel space, at higher resolution, to achieve classification.
This architecture is different from traditional image classification, in which the only thing that matters is the final classification produced by a deep neural network. For semantic segmentation to work, the algorithm needs to be able not only to classify pixels, but to project high-level classifications into the pixel space at different stages of the encoder.
Here are several models commonly used for semantic segmentation:
Region-based Semantic Segmentation
Region-based semantic segmentation methods generally follow a pipeline that uses recognition. Here is how this process typically works:
- Extracting free-form regions from an image and describing them.
- Region-based classification.
- Transforming region-based predictions to pixel predictions during testing. It typically involves labeling a pixel according to the highest-scoring region.
For example, a region-based convolutional neural network (R-CNN) is a machine learning model that employs a region-based method, performing semantic segmentation according to object detection results. Here is how this process works:
- Using selective search to extract many object proposals
- Computing CNN features for each object proposal.
- Classifying each region using class-specific linear SVMs.
R-CNN performs image segmentation by extracting two features for each region – a full region feature and a foreground feature. This process can improve performance when concatenating the features together as one region feature.
However, R-CNN suffers from several drawbacks. Some features are not compatible with the segmentation task and do not contain enough spatial information for precise boundary generation. Also, it takes time to generate segment-based proposals, greatly affecting overall performance. Recent research has proposed addressing these limitations using SDS, Mask R-CNN, or hypercolumns.

Fully Convolutional Network (FCN)-Based Semantic Segmentation
The original FCN model is able to learn pixel-to-pixel mapping without extracting region proposals. An extension of this model is the FCN network pipeline, which allows existing CNNs to use arbitrary-sized images as input. This made possible because, unlike in a traditional CNN that ends with a fully-connected network with fixed layers, an FCN only has convolutional and pooling layers. The ability to flexibly process images of any size makes FCNs applicable to semantic segmentation tasks.

The problem with FCN is that the resolution of the output feature map is downsampled by propagating through multiple alternating convolutional and pooling layers. Therefore, FCN predictions are usually performed at low resolution, and object boundaries tend to be blurry. To solve this problem, advanced FCN-based methods have been proposed, including SegNet and DeepLab-CRF.
Weakly Supervised Semantic Segmentation
Most methods involving semantic segmentation rely on large numbers of images with pixel-by-pixel segmentation masks. However, manually annotating these masks can be time-consuming and expensive to produce. Therefore, several weakly supervised methods have been proposed, which aim to take rectangular bounding boxes as inputs and use them to train on image segmentation tasks.

Generate Synthetic Data with Our New Free Trial. Start now!
Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
