
























Custom Structure Preservation in Face Aging
Introduction
Face age transformation (editing) involves reflecting age factors on a given face to create its future or past face images. A transformed face image must retain the identity of the original photo subject and all other details related to the face image.
Over the last few years this problem has attracted increasing attention both in industry and academia due to its wide range of applications. In movie post-production, for instance, many actors undergo some type of retouching, either for beautification or texture adjustments. A makeup or special visual effect is usually used to create synthetic aging or de-aging effects. As these methods are very time consuming, it is imperative to develop high-performance algorithms for automatic face age transformation. Despite extensive research on face aging, the lack of training samples for a given person over a long period of time still makes face aging a very difficult task.
An encoder-decoder architecture is typically used in recent deep learning approaches for face age transformation. An encoder embeds a face image in a low-dimensional latent space and this representation is transformed based on a given age. Afterwards a face image with the target age is then produced by feeding this modified representation to a decoder. Training of the encoder-decoder model is aimed at simultaneously maximizing image quality, preserving identity, and matching the target age.
In spite of all these successes, face editing is still challenging, and the existing approaches often struggle especially when the target image’s age differs substantially from the input image’s age. Face editing models tend to exhibit poor performance because they focus primarily on modifying a face’s skin texture, without incorporating possible changes to the face shape (e.g. head shape or hair structure) occurring with age, particularly for large age gaps.
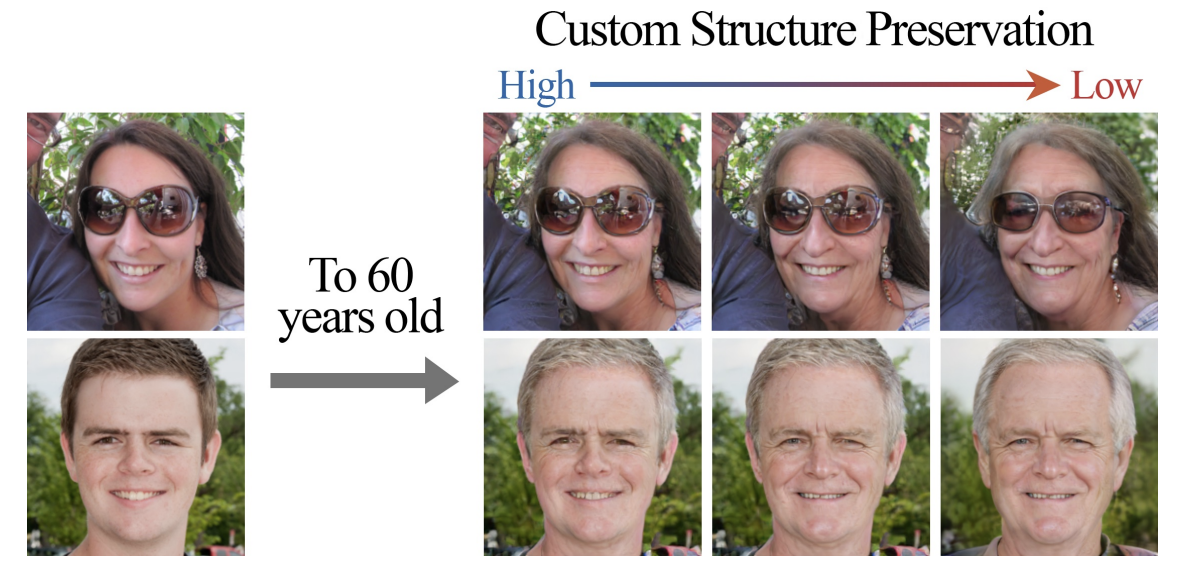
The authors developed a model capable of performing a realistic face image transformation successfully reflecting face shape changes happening when a person ages. The researchers observed that different individuals age differently and in a non-deterministic fashion. Some people’s appearances change significantly over time, however, others can easily be recognized from old photographs. To reflect this phenomenon, the authors developed a masking mechanism which allows for degree of structure preservation to be adjusted during inference. The masking mechanism, implemented with the Custom Structure Preservation (CUSP) module, determines input face regions that need to be preserved and those that should be modified during age editing. As a result, different levels of structure preservation (e.g. a hair growth pattern or face shape) can be applied to transform a given face image (see Fig.1). It is noteworthy that this mechanism does not require additional supervision during training.
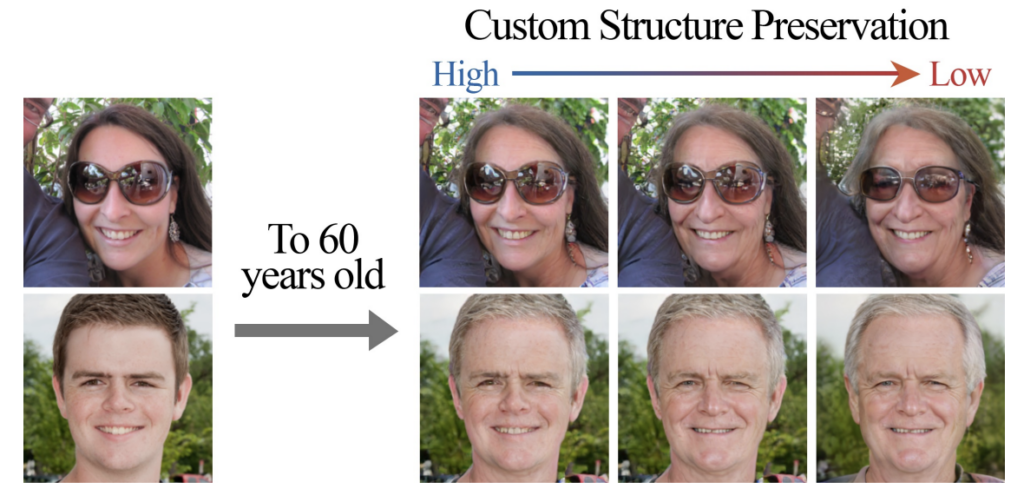
Fig. 1: The user can choose the degree of structure preservation during inference. A greater degree of transformation in facial morphology is observed as one moves to the right (lower structure preservation).
Model Architecture
The proposed model consists of 5 neural nets (see Fig. 2):
- Style Encoder Network Es: Produces a style embedding s of an input image X. Its final layer discards all image spatial information through global-average-pooling.
- Content Encoder Ec: Creates an image content representation c without taking into account the image’s style details.
- Age Encoder Ea: Builds an age embedding vector
- CUSP module: predicts a blurring mask M, which is leveraged to distinguish between image areas that should remain intact and those that are modified while performing image age transformation.
- Generator Network G: synthesizes a target image from the image style encoding s, its style encoding c, age representation at invoking a blurring mask M. The generator architecture is based on StyleGAN2 with several modifications made to adapt it to the age transformation task.
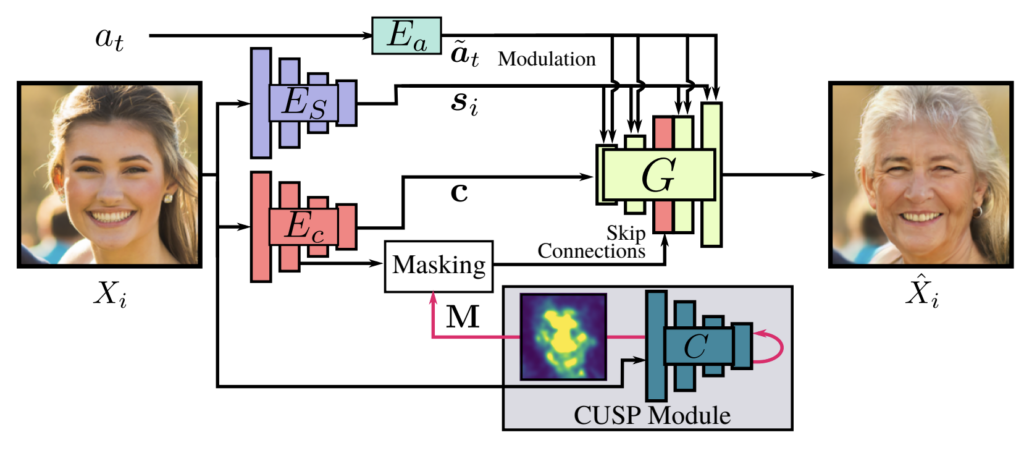
Fig. 2: Main Building Blocks of the Proposed Approach
CUSP Module: Customization of Structural Info Preservation Level
CUSP module, a key component of the proposed model, enables face image transformation with the required degree of structure preservation for the target age. It predicts a mask M which is leveraged to modify the content encoder output before it is fed to the generator (see Fig.2). Thus, only non-age-related structural information is propagated to the generator G allowing it to synthesize an image keeping the non-age related image regions intact.
In order to determine age-relevant image regions, the authors utilized the so-called Guided BackPropagation(GB) approach. Given a trained age classification network, GB allows detecting face image regions that contribute significantly to the age prediction. The paper uses a pretrained DEX classifier together with GB to detect age-relevant image regions.
In order to control the structure preservation extent of the target image, different blurring masks of content encoder output can be used. Then blurred input image content representation is fed into the skip connections (SC) of the generator.
Now we explain how feeding blurred encoder output to the generator SC allows us to control the degree to which structural information is preserved in the target image. SCs are known for their capability of propagating high-frequency information between input and output images (e.g. fine texture details, pixel-to-pixel alignment) and due to this are widely used in a variety of segmentation tasks. However when input and the target images might not meet this condition when the age gap between is significant (e.g. due to possible changes in facial morphology and hairstyle). Therefore the researchers proposed to adjust the degree of structural information propagating through the generator SCs.
Interestingly, different image regions can be blurred differently depending on the task. As an example, one can preserve the image background with a low blur level while significantly blurring the foreground to reduce similarity between the input and the target faces. The researchers use parameters σm and σg to control blurring levels of the age-relevant and age-irrelevant image regions.
Loss Function Structure
The loss function is composed of three components:
- Reconstruction Loss: measures the target image quality by employing L1 loss between the model output and ground-truth target image (used when a target image is available).
- Age Fidelity Losses: Penalizes the constructed image for not matching the target age. Here the authors used a combination of StyleGAN2 discriminator and already mentioned DEX age classifier.
- Cycle-Consistency Loss: Encourages a model to preserve not age-related details.
Results
To allow comparison with most existing methods, the authors conducted an impressive performance analysis over a large set of metrics, datasets, and tasks. They used FFHQ-RR, FFHQ-LS and CelebA-HQ dataset and evaluated model evaluation with “Young → Old” and “Group Age Detection”. In addition 80 persons were asked to compare the proposed approach with HRFAE and LATS methods (Fig. 3). Users were asked about identity preservation, target age accuracy, realism, age transition naturalness (“Natural Progression” column in the table), and their overall preferences regarding the transformed face images. There was a significant performance gap between CUSP and these methods in every category.
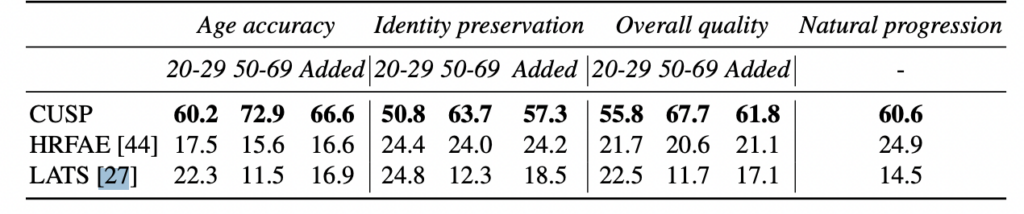
Fig. 3: User study results (comparison with HRFAE and LATS). Column, called “Added” in Fig.3 is just an average between ‘20-29’ and ‘50-69’ columns
Next CUSP produces images that match “aged” versions of the input image better than its competitors (strangely all “aged” images wear glasses – maybe it is related to the chosen blurring parameters).

Fig. 4: “Aging” with the proposed approach vs. other schemes
Finally the authors analyzed an impact, caused by different values of a structure preservation degree (=blurring parameters) on the image structural info preservation degree. One can see that the larger are blurring parameters, the less image details remain intact after the transformation (as expected).
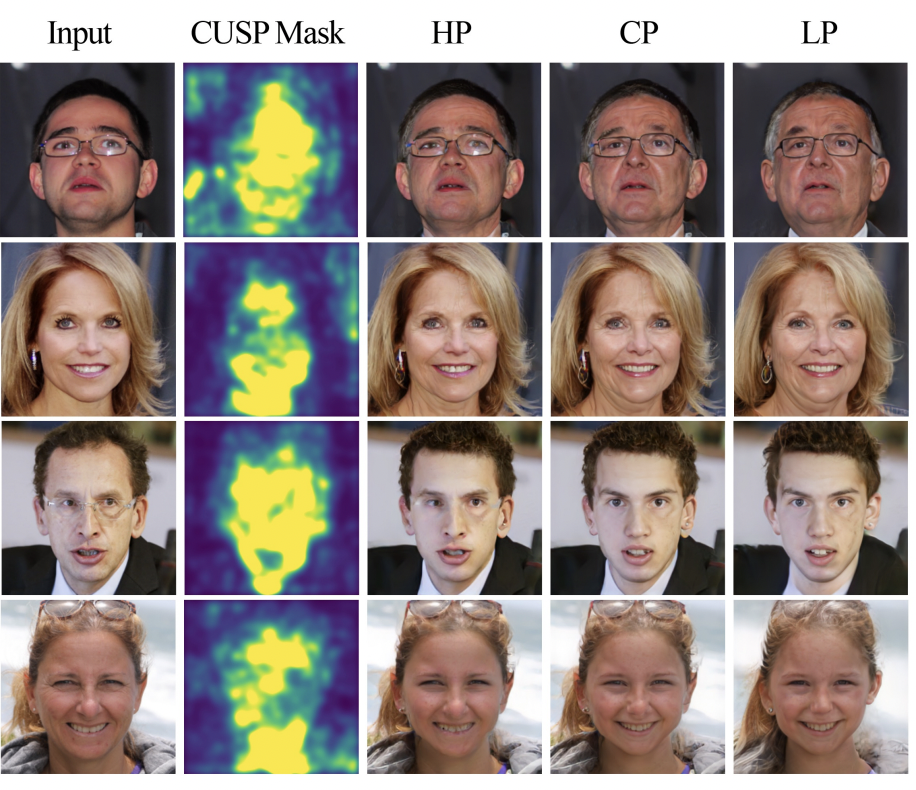
Fig. 5: Impact of the kernel value: images obtained with High, Low, and Custom structure preservation (LP, HP, and CP). HP:(σm, σg) = (0, 0); CP:(σm, σg) = (9, 0); HP:(σm, σg) = (9, 9). The second column shows the mask estimated by CUSP
Conclusions
This paper presents a novel face age transformation method that allows structure preservation of the target images to be controlled during inference through two parameters. Users can decide to what extent they want to retain the background and the face identity of the original input image based on the task at hand. The researchers conducted an extensive performance evaluation for the proposed model to show that it outperforms the existing methods(four different performance metrics were used for the comparison).
A notable disadvantage of CUSP is its inability to enforce desired characteristics on the transformed image. For instance, it is unclear how to choose structure preservation parameters that will result in drastic hairstyle changes (e.g. baldness) to the “aged image”. In other words, the structure preservation degree parameter space is not clearly interpretable. Inadvertent addition of glasses to the “aged” images is another side effect of this lack of interpretability of the parameter space, as shown in Fig. 5 (last column).
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
