
























Dual-Generator Face Reenactment

Introduction
Face reenactment (FR) is a conditional face generation technique aiming to accomplish two objectives given a pair of face images (source and reference faces):
1) Translate an expression and pose of a reference face (=face shape) into a target face.
2) Transfer an identity of a source face into a target face.
The goal of FR is to create a photorealistic face image with the source face identity and the reference face pose and expression.
Over the past decade, FR has attracted enormous research efforts because of its practical applications in filmmaking, facial animation, and augmented reality. A common FR approach is Landmark-Assisted Generation (LAG), involving face shape transformation, followed by reenacted face generation through the use of facial landmarks. Another family of FR schemes employs reconstructed 3D meshes of the source and reference images to learn the optical flow needed to construct a reenacted face without relying on facial landmarks.
While FR techniques have made significant progress in the past decade, reenacted faces generated with them still have some issues. The reenacted image photorealism and quality are still subject to improvement. Moreover, the reenacted face identity doesn’t coincide with the source image identity, due to inaccurate face landmarks/3D mesh estimation. Second, most approaches only consider median pose variation (yaw angle at 45 degrees) and are not capable of tackling large or extreme poses.
Main Idea of the Paper
The paper, Dual-Generator Face Reenactment, proposes a novel approach, dubbed Dual-Generator (DG), comprising 2 generative models. The first model, called ID-preserving Shape Generator (IDSG), generates facial landmarks of the reenacted face lt, e.g. transfers the pose and expression of the reference face Ir to the source face Is. The second model, called reenacted face generator (RFG), utilizes the generated facial landmarks lt and the source face to generate the reenacted face It. The flow diagram of DG is depicted in Fig.1 below.
{kind=link}
Fig1: DG building blocks
The authors used 3D facial landmark detectors to control the quality of visible pose-dependent face shape details to enable large-pose reenacting. RFG synthesizes the target face with the required identity, pose and expression from the facial landmarks generated by IDSG.
First, RFG and IDSG are trained in the so-called self-reenactment regime, in which the reenacted ground-truth image (and its landmarks) are known. Then it is trained for cross-ID reenactment (cross-reenactment) when the target image is unknown. The parts of the loss function using ground truth image information are not used for model optimization during cross-ID reenactment training.
Detailed Explanation of the Paper Idea
ID-preserving Shape Generator(IDSG): Workflow
IDSG objective is to create reenacted face landmarks, using the source and reference images as inputs. As a first step, facial landmarks (including their visibility) are extracted from the reference image. This is followed by the construction of deep features of these landmarks. The next step is to build the source image features. Finally the reference image landmarks and the source image features are used to produce reenacted face landmarks.
IDSG: Building Blocks
IDSG consists of 6 neural nets while 2 of them (Face encoder ![]() and 3D facial landmarks detector
and 3D facial landmarks detector ![]() ) are off-the-shelf models and their parameters are not updated during training (see Fig 2).
) are off-the-shelf models and their parameters are not updated during training (see Fig 2).

Fig 2: IDSG Building Blocks Face encoder : extracts essential image features; 3D facial landmark detector : builds image landmarks; Facial landmark encoder : produces landmark features; Facial landmark decoder : reconstructs facial landmarks from its features; Landmark discriminator : distinguishes between real and generated landmarks; Identity classifier : classifies face identity from landmarks
IDSG: Loss Function Structure
The IDSG loss function consists of 5 main components, which we briefly outline below. The first loss component, Adversarial Loss, controls the photorealism of facial landmarks, produced by IDSG. It ensures that the generated landmarks represent actual image landmarks.
The second component, Visual Loss Shape Loss (VLS), has two objectives. The first one aims at improving reference image landmark accuracy by minimizing distance between reference image landmarks and its ground-truth landmarks. The second VLS objective is to make reenacted image landmarks further from the reference image landmarks, as they correspond to different identities (of the reference and source images, respectively).
The third loss component, Action Loss, is designated to ensure that the pose and expression of the reference image are transferred to the reenacted image. It tries to minimize the distance between the representations (codes) of the reenacted and the reference images landmarks. A landmark representation here encodes mostly image pose and expression characteristics, discarding most identity features.
The fourth loss component, Subject Class Loss, encourages the model to produce reenacted image landmarks with the same identity as the source image.
The final loss component, Localization Loss, complements the VLS loss and aims to enhance the match between the reference and reenacted landmarks and their ground-truth counterparts.
Reenacted Face Generator(RFG)
RFG: Workflow
RFG creates reenacted face images based on reenacted image landmarks and the source image. First, a source image style code (which encodes image identity features) is generated. Using this style code and the landmarks in the reenacted image, a reenacted face is constructed.
RFG architecture is based on StarGAN2 and comprises 5 networks.

Fig 3: RFG Building Blocks Encoder-Decoder Face Generator : generates face image from landmarks and source face “style” code, Style Encoder : builds source image “style” code; Face Discriminator : distinguishes between ground-truth target faces and generated reenacted faces; Landmark Discriminator : distinguishes between ground-truth target faces and generated image landmarks
RFG: Loss Function Structure
RFG loss function includes the following components, which are briefly outlined below.
The first component, Adversarial Loss, is designated to enforce three objectives on the reenacted image:
- Photorealism (it must look like a real face)
- The same identity as the source image
- The same action (pose and expression) as the reference image
This loss is the standard GAN loss, but here we have 2 discriminators ![]() and
and ![]() with the face generator
with the face generator ![]() .
.
Attribute and Identity Losses aim at imposing similarity on the generated image and the ground truth reenacted image.
Style Consistency Loss encourages the model to produce reenacted image with the same style code (representing identity features) as the source image.
The last loss, Landmark Loss, component tries to ensure that the generated reenacted image has landmarks, generated by IDSG block
Performance Analysis
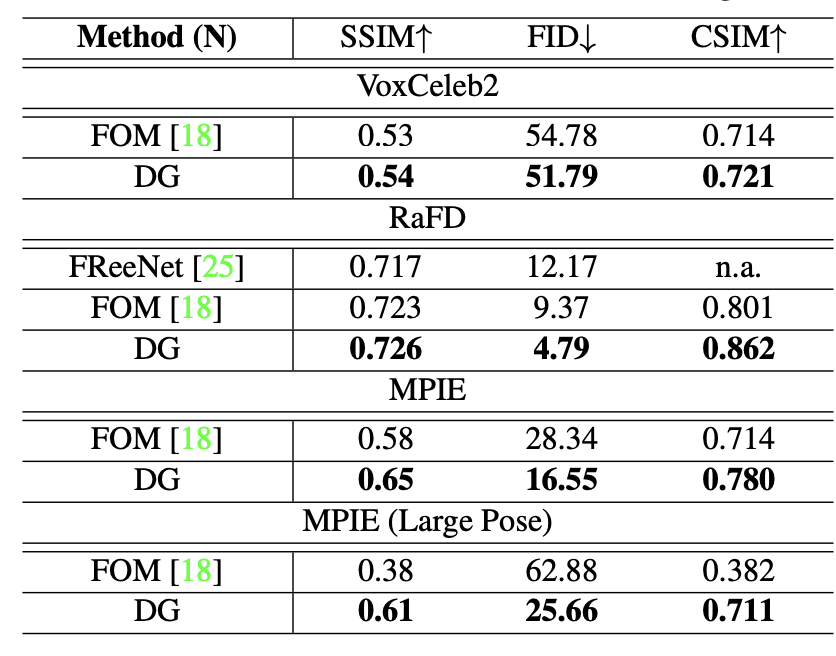
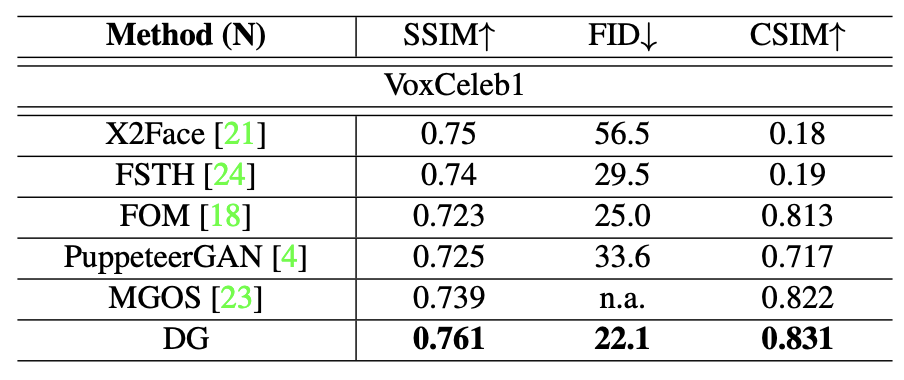
The authors evaluated DG performance on 4 datasets: RaFD, MPIE, VoxCeleb1 and VoxCeleb2. FID, SSIM and cosine similarity (CSIM) metrics were used to gauge the photorealism and identity preservation of generated face images. SSIM assesses low-level similarity between the generated images and ground-truth images. CSIM measures identity preservation by computing similarity between the source and generated facial image representations, extracted by feature embedding layers of ArcFace.
{kind=link}
Fig 4: Cross-reenactment (testing performed on unseen during training identities) performance compared with SOTA methods on VoxCeleb2, RaFD, MPIE and MPIE (Large Pose)
DG achieves the best performance across all 3 metrics compared to previous face reenactment schemes. Notably the most significant performance improvement was reached in large-pose reenactment due to the use of 3D face landmarks to the reenacted face generation.
{kind=link}
Fig 5: Comparison of self-reenactment performance with SOTA methods on the VoxCeleb1 dataset
In addition, faces generated by DG appear photorealistic and possess the desired properties of a reenacted image.

{kind=link}
Fig 6: Cross-reenactment comparison with FReeNet and FOM on the RaFD. Top row shows the references. Those enclosed by red bounding boxes are made by the DG
Conclusion
The paper proposes a dual-generator model for face reenactment that outperforms current SOTA methods, especially when it comes to large-pose reenactment. The performance improvement was achieved through the use of 3D facial landmarks along with a carefully engineered loss function which allowed for successful capture of visible face shape variations.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
