
























Facial Landmarks and Face Reconstruction: An Intro

Face (facial) landmarks are essential attributes of a human face that allow us to distinguish between different faces. Facial landmarks are used to identify and represent key parts of a human face, such as nose, eyebrow, mouth, or eye corners. A face image’s landmarks are usually the 2D coordinates of their positions in the image plane.
These landmarks are widely used for computer vision applications, like 3D face morphing, head pose estimation, face reconstruction and extraction of facial regions of interest. A common representation of facial landmarks using predefined 68 points is presented in Figure 1. Unfortunately, many important face characteristics cannot be adequately recovered solely based on a set of sparse facial landmarks. It is difficult, for example, to tell if a person has high cheekbones without landmarks on the cheeks. Therefore, creating a high-quality 3D model solely based on a few facial landmarks does not seem possible.
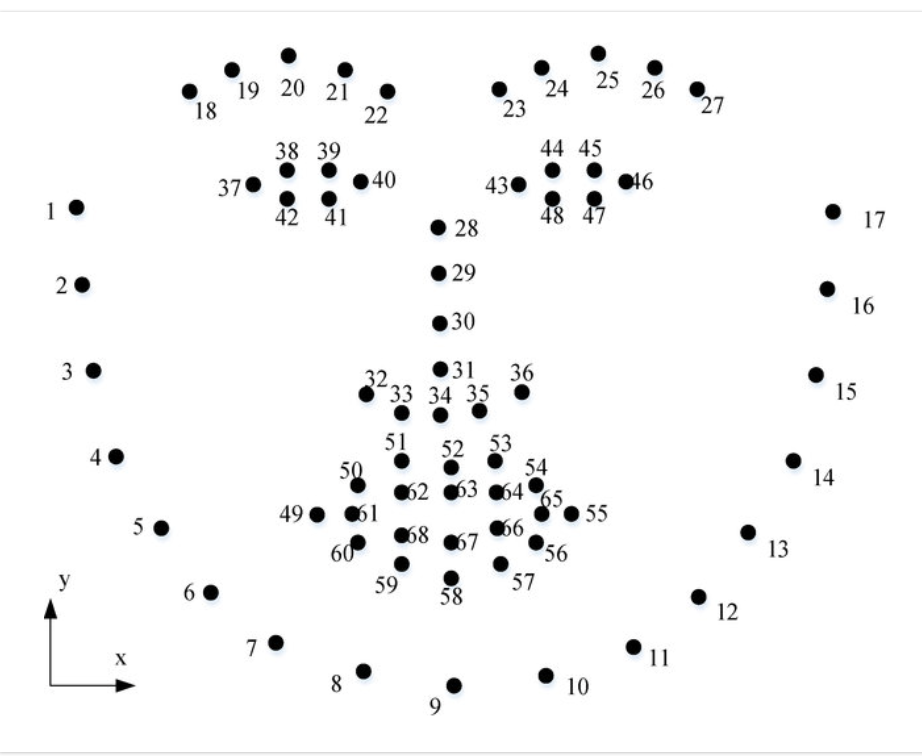
Fig.1: 68 facial landmarks
To overcome this hurdle, additional characteristics of face images are used to build 3D face models. For example, previous works harnessed optical flow (between face images taken from different angles) and depth maps information for this task. These characteristics (optical flow and depths) are usually leveraged in addition to landmarks as constraints on a 3D face model. For example, optical flow computed using a 3D face model, reconstructed from a face image sequence, should be consistent with ground-truth optical flow for this sequence. Unfortunately, relying on these characteristics for face reconstruction can be problematic as they are often inaccurate, difficult to obtain and expensive.
Facial landmarks are often combined with the aforementioned characteristics to build more accurate face models with the help of differential rendering techniques. Differentiable renderers are applied to determine the relationship (usually quite complex) between the facial identity features (such as landmarks or 2D projections) and the 3D face model parameters for shape and texture. Such renderers allow for construction of differentiable loss function for face model parameters which is usually optimized by gradient descent algorithms. Unfortunately, differentiable rendering methods are highly complex and usually involve intricate procedures of neural network training. Additionally, in many cases simplifying assumptions on face images properties are required to make these methods computationally feasible.
The authors of the paper ask the following question: is there a way to construct a high-quality 3D face model based on ONLY facial landmarks without exploiting other image characteristics like depth maps/optical flow and without using differentiable rendering techniques? We already know that it is not possible to build an accurate face model solely based on a sparse set of facial landmarks, covering only a frontal part of the face. But perhaps we can do it, if we have a dense set of landmarks, which cover the entire head (see Fig. 2). Having such a rich set of landmarks seems to contain sufficient information to build an accurate 3D face model.

Fig.2: Given a single image (top), we first robustly and accurately predict 703 landmarks (middle). To aid visualization, we draw lines between landmarks. We then fit our 3D morphable face model to these landmarks to reconstruct faces in 3D (bottom).
However, annotating a human face with a dense set of landmarks is a very difficult task. Even though humans are capable of labeling face images with a small number of landmarks accurately, annotating them with hundreds of dense landmarks seems almost impossible. Several methods have been developed for predicting dense facial landmarks, but unfortunately these methods often suffer from high computational complexity and are incapable of predicting landmarks densely covering the whole head, including eyes and teeth and therefore will not suffice the task of 3D head reconstruction.
Paper’s Idea: An Essence
The authors of this paper tackle this problem with a different approach. Instead of using real data, the researchers suggest using synthetically generated facial images with perfect annotations of dense landmarks. The proposed approach consists of three main stages:
1. Rendering 100k synthetic face images, using the method proposed by Wood et al. with 700 perfectly consistent 2D landmarks, fully covering the whole face region. The generated set covers human faces with different hairstyles, clothing, facial expressions and textures made from different camera locations.

Fig.3: Given an image, we first predict probabilistic dense landmarks L, each with position µ and certainty σ. Then, we fit our 3D face model to L, minimizing an energy E by optimizing model parameters Φ.
2. Training of a convolutional neural network (CNN) for prediction of landmark location along with the prediction uncertainty. Importantly, the rendered face images themselves are not explicitly used for the model training procedure but solely their 2D landmarks.
3. Fitting of a morphable 3D face model to these dense landmarks
It is noteworthy that the synthetically generated facial images with their dense landmarks are the primary enabler of the proposed scheme as a human annotation of 100K images with 700 landmarks is impractical.
Landmark Prediction Model Training:
The landmark prediction model is probabilistic. Namely a neural network is trained to predict expected position = (x, y) of a landmark together with its standard deviation(std) , which measures the prediction uncertainty. The model is trained to predict small σ-s (low uncertainty) for visible landmarks (e.g. on the front of the face), whereas high values of σ are predicted for hidden (e.g. behind hair) landmarks to represent their high uncertainty. Note that a rendered image contains only the landmark positions but not their uncertainty.

Fig. 4: When parts of the face are occluded by e.g. hair or clothing, the corresponding landmarks are predicted with high uncertainty (red), compared to those visible (green).
To enforce these requirements on the trained model, the authors used a Gaussian negative log likelihood loss function:
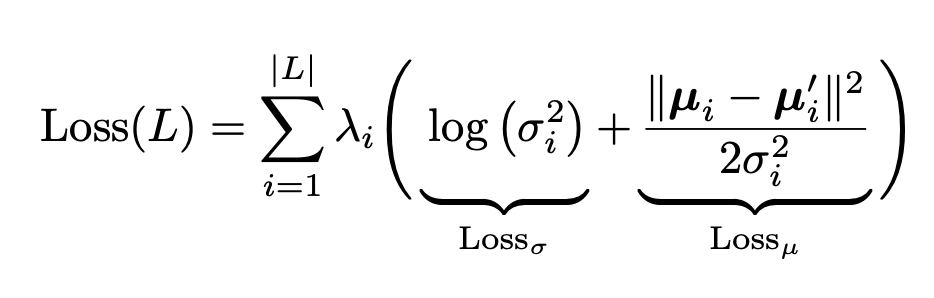
where L denotes the number of landmarks. The first part of the loss penalizes the model for too high uncertainty while the second part controls the prediction accuracy.
3D face model fitting:
After training the probabilistic landmark prediction model, a 3D face model is reconstructed by minimizing a two terms loss function:
1. The first term Elandmarks fits the probabilistic landmarks from the first stage. This term penalizes the 3D model for inaccurate “explanation” of 2D landmarks and has the following form:
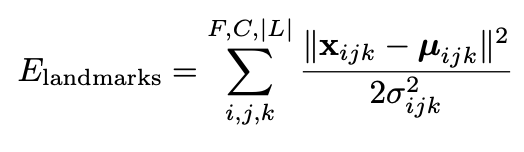
where, for the k-th landmark viewed by the j-th camera in the i-th frame [µijk, σijk] are the 2D location and uncertainty predicted in the previous stage, while xijk is the 2D projection of that landmark on the 3D model. Note that the loss function has a reduced penalty for the hidden landmarks (e.g., by hair or clothes), which are given a high uncertainty by the first stage model.
1. The second term is a regularizer imposing the inherent face properties on the model output. It consists of 5 terms: Eidentity, Eexpression, Ejoints, Etemporal and Eintersect. Here, Eidentitypenalizes unlikely face shapes, Etemporal requires face mesh vertices to remain still between neighboring frames, while Eintersect aims at avoiding skin intersections with eyeballs or teeth .Finally, the objectives of Eexpression and Ejoints are to minimize joint rotation and facial expression (with respect to a “neutral” face position and expression) when describing the training data (landmarks).
Performance Improvement:
The proposed approach performance was compared with several recent methods on 2 benchmarks: the NoW Challenge and the MICC dataset. The evaluation is made in the context of single and multi-view tasks, single view means a face model to each image separately while multi-view means a face model is built based on all images of a specific subject. For the former benchmark, the proposed technique outperformed SOTA methods for both tasks.
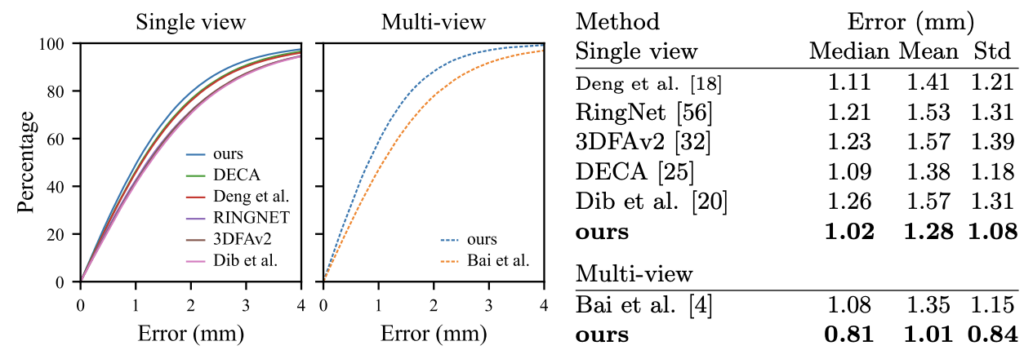
Fig. 5: Results for the NoW Challenge. We outperform the state of the art on both single- and multi-view 3D face reconstruction.
Furthermore, the authors showed that 3D face reconstruction is more accurate when fitting with more landmarks.

Fig.6: Ablation studies on the NoW validation set confirm that denser is better: model fitting with more landmarks leads to more accurate results. In addition, we see that fitting without using σ leads to worse results.
Conclusion:
A large dense set of facial landmarks has been shown to be a powerful signal for 3D face reconstruction. Construction of large datasets containing face images with such a high number of perfectly consistent landmarks can only be accomplished using synthetic data, since it is impossible to to manually annotate.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
