
























Four Technological Takeaways from CVPR 2022

The annual CVPR is the gathering of the brightest minds in the world of computer vision. It represents the amalgamation of ideas–both incremental improvements and monumental discoveries –that collectively advance the state of computer vision.
Having perused the papers submitted to CVPR 2022, we distilled four key learning points from four key technologies – transformers, multi-modal models, generative adversarial networks (GAN), and neural radiance fields (NeRF).
1. Transformers are gaining popularity for vision tasks
The transformer architecture is the de facto leader for many NLP tasks today. Its brilliance stems from its self-attention mechanism, which gives different significance to each part of the input. In CVPR 2022, we see computer vision researchers applying transformer architectures to visual tasks, creating visual transformers (ViT).
One takeaway from CVPR is that the performance of ViTs scales with the model size and compute. Google researchers scaled ViT models and data, up and down, and studied the impact on error rate and the amount of compute. They also presented a two-billion parameter ViT model with state-of-the-art results on ImageNet.
Visual transformers are becoming more efficient. Mobile-Former, the intersection of MobileNet with transformer, is an example of such an effort. As its name suggests, MobileNet is a lightweight CNN-based model ideal for mobile and embedded vision tasks. Mobile-Former combines the local processing of MobileNet and the global interaction of the transformer architecture. Consequently, it could outperform MobileNetV3 on ImageNet classification at a low FLOP (floating point operations per second) regime.
Vision transformers are rather robust. Researchers discovered that ViT generalizes better than convolutional neural networks (CNNs) under distributional changes. While CNNs are more likely to learn biases on backgrounds and textures, ViTs remember shapes and structures. To enhance the robustness of ViTs, researchers from Alibaba proposed Robust Vision Transformer to deal with adversarial examples, common corruptions, and distribution shifts.
2. Multi-modal models are advancing vision and language tasks
Since OpenAI connected text and images with CLIP, there has been renewed interest in the CV community on multi-modal research. The significant progress made in this domain is apparent from CVPR 2022.
In particular, Microsoft published the GLIP (grounded language-image pretraining) model. It learns object-level, language-aware and semantic-rich visual representations. To do so, GLIP is pre-trained on phrase-grounding, which is the task of linking phrases in a sentence to objects in an image (Figure 1). The pre-trained model can be used for transfer learning. Amazingly, a 1-shot GLIP achieved state-of-the-art results on 13 downstream object detection tasks.

Figure 1. Phrase-grounding is the task of linking phrases to objects (Source)
Further, Globetrotter demonstrated a novel approach for a machine translation task using multi-modal learning. Globetrotter builds on the observation that the visual appearance of the object remains consistent even if the language used to describe it varies dramatically (Figure 2). Trained on a dataset that aligns text from different languages with the images of the same object, Globetrotter outperforms existing supervised translation tasks.
Read our Benchmark on Leveraging Synthetic Data for Hands-on-Wheel Detection

{kind=link}
Figure 2. Same object, different languages (Source)
3. GANs are getting better at generating images and videos
Generative Adversarial Networks (GANs) laid a solid foundation for image synthesis. CVPR saw researchers pushing the limits of GAN.
It is now easier to control the output of GANs. One of the papers presented in CVPR 2022 is SemanticStyleGAN. Its predecessor StyleGAN allowed for control over the global attributes of the generated images. SemanticStyleGAN one-upped StyleGAN by giving practitioners control over local attributes and achieving exceptional disentanglement between different spatial areas (e.g. skin, eyes, eyebrows, mouth, and hair) (Figure 3).
BodyGAN is yet another improvement of GAN presented at CVPR 2022. When generating human images, BodyGAN utilizes a pose encoding branch and appearance encoding branch to effectively disentangle pose and appearance. Thus, BodyGAN offered fine-gained control over the poses, body shapes, and skin color (Figure 4).

{kind=link}
Figure 3. Local style transfer using SemanticStyleGAN

Figure 4. BodyGAN gives practitioners control over (a) body pose (b) skin colors and (c) face (Source)
We also see from CVPR 2022 the application of GANs to video generation. StyleGAN-V is a continuous video generator with the price, image quality, and perks of StyleGAN2. Video generators thus far (like MoCoGA-HD and DIGAN) are slow to train and produce short videos of low quality. StyleGan-V is different. Given sparse videos, it could generate infinite videos of high quality.
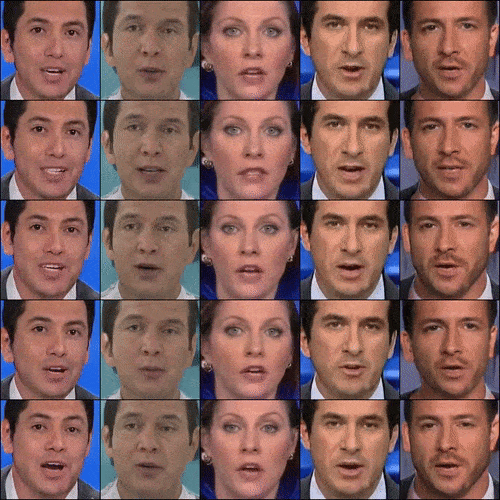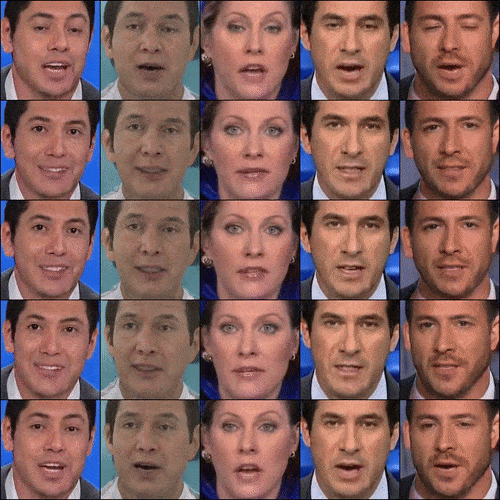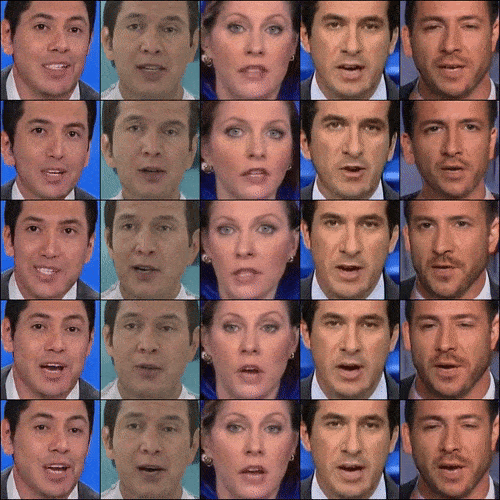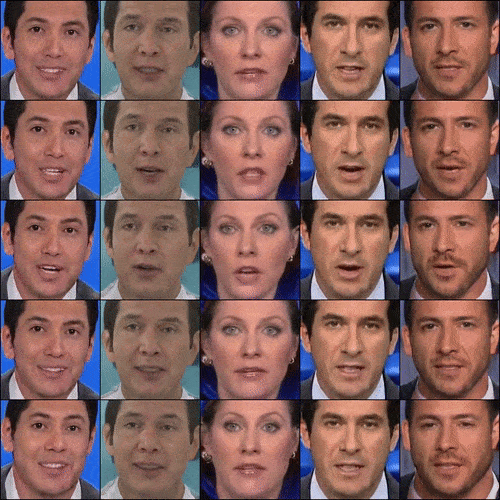
Figure 5. StyleGAN-V’s videos (Source)
4. NeRFs now require fewer or lower quality inputs
Neural Radiance Fields (NeRF) is a cutting-edge method for creating novel views of complex scenes. It requires only a few images of a scene to optimize its volumetric representation. NeRF still remains an active field of research two years after its inception in 2020. This year, researchers showed that NeRF could work with fewer or lower quality inputs, making NeRF more versatile than ever.
Thanks to Pix2NeRF, practitioners need only one image (instead of a few) to generate the scene of a specific class (Figure 6). To do that, Pix2NeRF uses an unsupervised single-shot framework that could translate an input image into a neural radiance field (NeRF).
Further, NeRF could now work on low-quality raw images. In the paper RawNeRF, Google researchers successfully synthesized high dynamic range (HDR) views from noisy raw images, like dark images. Further, they can manipulate the image in terms of its focus, exposure, and tonemapping after the image was generated (Figure 7).

Figure 6. Pix2NeRF could generate views from different poses given one image (Source)

Figure 7. Google reconstructed dark scenes using noisy images.
Not only that, researchers also found ways to pause a video at any frame and generate a 360-degree view of a human subject. More specifically, the rendering method, dubbed HumanNeRF, produces free-viewpoint renderings of humans in motion from a single video. Gone are the days when multiple videos of the same person is needed to reconstruct the person from another angle. The challenge was in generating photorealistic details of the body, face, and clothing, and HumanNeRF excels at that.
So much to see, so little time
Having attended CVPR 2022, we are absolutely fascinated by the advancements that the community has to offer. There are so many noteworthy topics and fascinating discoveries this year that it’s impossible to cover them all.
If you are intrigued, we invite you to study the accepted papers and attend some workshops and tutorials. See you at the other end of the rabbit hole!
Read our Benchmark on Leveraging Synthetic Data for Hands-on-Wheel Detection
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
