
























Production-Ready Face Re-Aging for Visual Effects

Introduction
Digital re-aging of faces in video involves the process of altering the appearance of a person in a video to make them look younger or older. This can be a very complex and challenging process, as the technology should be able to accomplish the following goals:
Motion and Changes in Expression: As the person in the video moves and changes expressions, the model should maintain the desired age transformation in each frame.
Consistency: The transformations applied to each frame should be consistent and accurate; specifically, the model should be able to recognize and maintain the unique features of each face as it ages.
Artifacts: When transforming the appearance of a face in each frame, it is essential not to introduce any distortions or unwanted artifacts that could negatively affect the quality of the video.
To put it simply, a face re-aging model should be able to accurately alter the age of the person while maintaining other aspects of the image (identity, background, pose, facial expression, etc). Despite significant advancements in deep learning (DL) based face re-aging, frame-by-frame re-aging faces models struggle to meet these objectives.
Main Idea
One of the most prominent techniques for face re-aging in video is frame by frame re-aging, which alters a person’s face appearance in each individual frame of a video. In order to train a frame-by-frame re-aging Machine Learning (ML) model, satisfying the aforementioned requirements, it is essential to collect an immense amount of high-quality images of individuals with diverse appearances over a long time period(e.g. decades). Such a dataset would be nearly impossible or at least very expensive to construct. The paper proposes to use SOTA generative re-aging neural models(for still images) to generate numerous synthetic facial images that exhibit consistent and photorealistic aging effects. While these models often fail on real-life images, they can still be leveraged to synthesize massive datasets of high-quality facial images spanning a wide age range. Importantly, the synthetic images created with these models remain consistent throughout the lifespan of the individual.
Furthermore, the authors observe that a frame-by-frame re-aging problem can be interpreted as an image-to-image(I2I) translation task. It is long known that U-Net-based neural net architecture is perfectly suited for I2I tasks (e.g segmentation and superresolution). The authors propose leveraging U-Net strength to train a neural network, performing re-aging of a facial image. In other words, for a given image of an individual and a target age, the model output is the person image at the target age, while all the other image details remain intact (e.g. background, facial expression, pose, lightning etc). The proposed model is called Face Re-Aging Network or simply FRAN.

Fig 1: FRAN Results: several video frames of an individual (age 35), re-aged to 65 (top row) and 18 (bottom row) re-aged with FRAN
FRAN Model Architecture
Recall that FRAN relies on highly effective U-Net architecture to perform image re-aging (frame-by-frame). This U-Net predicts per-pixel RGB deltas (offsets), which are added over the input image to construct the re-aged image. An input to FRAN is 5-channel tensor composed of the following components:
- RGB input image (3 channels)
- Input Age Representation: is a single channel image with the same resolution as the input. The age “image pixels” are normalized between 0 and 1, reflecting a continuous age spectrum (years/100).
- Target Age Representation: built similarly as the input age representation.
- Pre-trained Face Segmentation Network (optional) can be used to aid in detecting face areas that are relevant for re-aging.
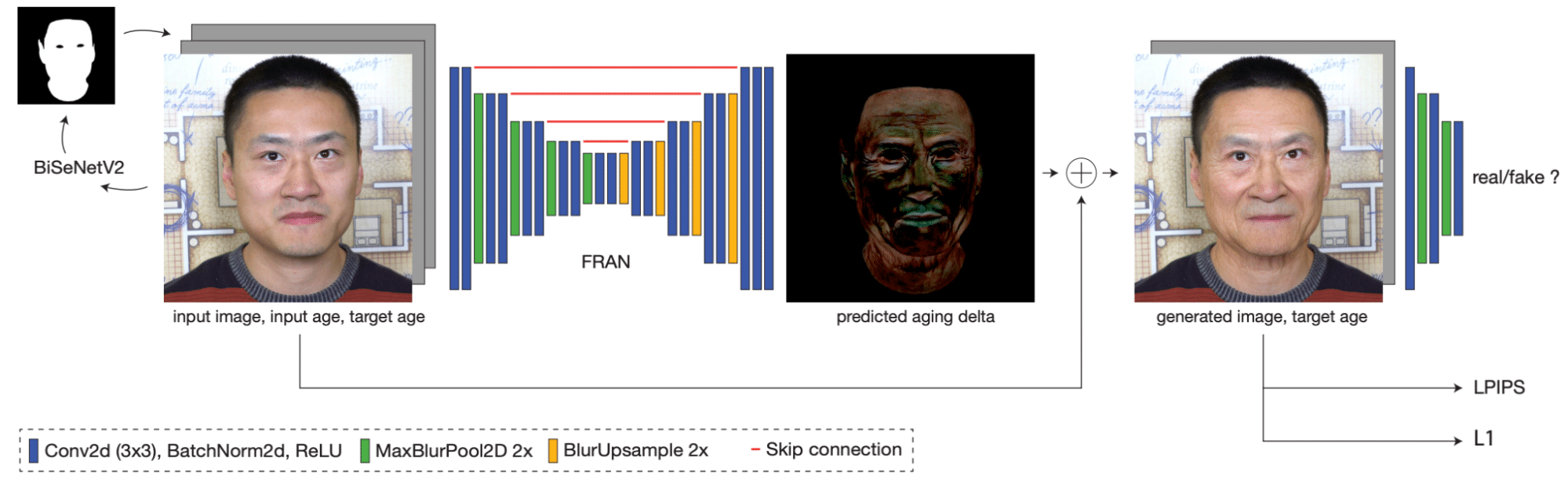
Fig 2: FRAN architecture: A high-level view
As FRAN is given both the input and target ages, it can focus on predicting aging deltas by rather than trying to estimate an input image age. Interestingly the target age representation is not required to be constant over the spatial dimension. Filling an target age map with varying values enables FRAN to achieve different “re-aging” levels across different face areas (Fig. 3).

Fig. 3: Painting a target age map allows for re-aging different parts of the face with different age targets
FRAN Training
Recall that FRAN is trained on a diverse synthetic dataset of facial images across a wide range of ages. The objective of FRAN is to predict the difference (delta) image between the input and the target(re-aged) image. The loss function of FRAN is composed of the following 3 components:
- Discriminator Loss: The authors train the Discriminator(D) neural net to differentiate facial images synthesized by FRAN from ground-truth target images (which are synthetic as well). D is a modified version of the well-known PatchGAN discriminator (it compares only local patches of the images). It is important to note that an input age map is fed into D along the ground-truth and the generated target image.
- LPIPS perceptual loss between FRAN output and the target image: computes the similarity between the activations of image patches for pre-trained VGG (shown to match human perception).
- L1 loss between FRAN output and the target image.
Note: It is not clear which part(s) of the loss function explicitly penalizes the model on generating re-aged images with different identity. In spite of this, FRAN achieves superior performance on identity preservation over other SOTA approaches
Results
First the authors evaluated a visual coherence of the re-aged facial images, produced by FRAN, for a wide range of ages (20 to 80). The synthesized images are smooth and coherent across ages, and the input image identity is fully preserved (see Fig.4)
Fig. 4: FRAN results for still images
Then the paper compared target age preservation (measured by pretrained age prediction model) of images produced by FRAN against several re-aging approaches. Although FRAN achieved superior results for most ages, it was slightly inferior to SAM for older ages (see Fig. 5).
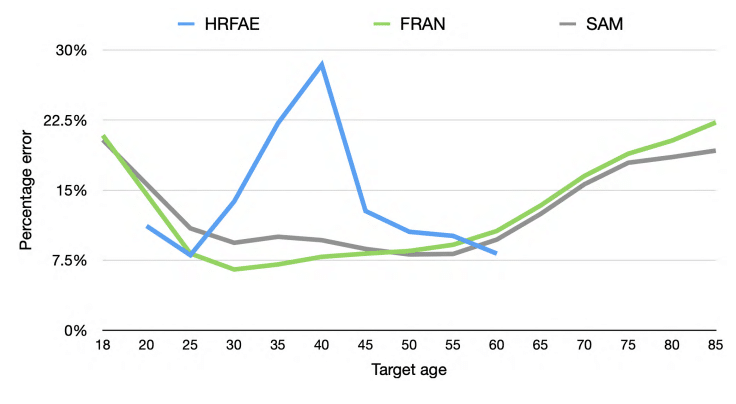
Fig. 5: Target Age Matching Comparison
A further benefit of FRAN is that the re-aged images, corresponding to different video frames, retain details that are irrelevant to the aging of the image.

Fig. 6: VIdeo frames re-aged with FRAN
The authors also compared FRAN results with several re-aging models (for images). Compared to other methods, FRAN results look more consistent and retain facial expressions, pose and background of the input image.

Fig. 7: FRAN Comparison with other re-aging approaches
As we mentioned earlier, one of the most important aspects of a high-quality re-aging approach is its ability to preserve the individual identity across ages. The authors compared FRAN mean identity loss (measured with a pretrained recognition model) across a wide range of ages with several other re-aging methods (see Fig.8). FRAN was capable of achieving better results than the competitors but the margin was not substantial (against HRFAE).
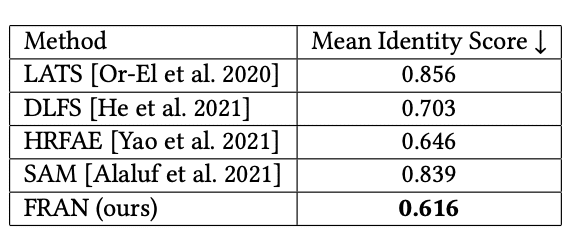
Fig. 8: FRAN Identity Preservation (Mean Identity Score, lower is better)
Finally, the researchers carried out human evaluation of FRAN results against four aging approaches. A total of 32 participants were asked to compare FRAN results (still images) with four other aging methods. According to most evaluators, FRAN preserves the identity of the individual and matches their target age better than its competitor (see Fig.9).
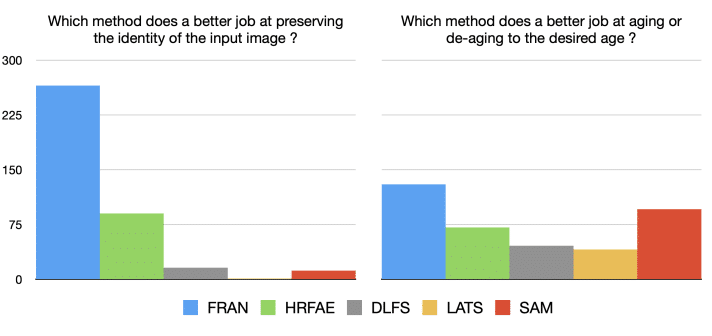
Fig. 9: Human evaluation of FRAN
Final Remarks
From my perspective, I believe that the re-aged images generated by FRAN are over-optimistic, portraying an 85-year-old individual as appearing 75 years old, or possibly even a bit younger. For example, changes in hair texture that take place when aging (gray hair, baldness) are not reflected in the re-aged images.
Conclusion
The paper proposes a relatively simple and intuitive method for re-aging faces in video images that is fully automatic and ready for production. The proposed approach formulates re-aging in video as frame-by-frame image re-aging and trains the model on synthetically generated dataset of images across a wide spectrum of ages. FRAN produces re-aged images that match the target age while preserving all other input image details. There is a great deal of potential for FRAN to be used in a variety of applications, such as advertising and entertainment.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
