
























SynFace: Face Recognition with Synthetic Data

Face Recognition: Intro
The face (facial) recognition objective is to determine or verify a person’s identity through their face. Face recognition is one of the most widely used computer vision applications with significant commercial potential. Today, we rely heavily on facial recognition technology for many tasks including:
- Unlocking our smartphones
- Adding friends to Facebook posts based on their facial images
- Identifying a person at customs (based on the person’s image/s, stored in the customs’ database).
In the past decade, deep learning techniques have enabled face recognition technology to advance significantly. It is well known that deep learning approaches for face recognition require large-scale and diverse training sets in order to deliver high performance. Today, the majority of existing face recognition datasets are collected from the internet, but their labeling is low-quality (the same person might have different labels) and lacks proper annotations of essential image attributes like illumination and pose. The latter issue makes it difficult to analyze how these attributes impact deep learning model performance. Furthermore, privacy concerns may arise when collecting such datasets.
Synthetic Data for Face Recognition Systems
Synthetically generated datasets can be leveraged for significant reduction of the amount of real-world images required for training deep face recognition models. Generating synthetic facial images of new identities and diversifying attributes (new poses/hairstyles, different illumination conditions, wearing accessories, etc.) of the existing individuals are capable of alleviating the above-mentioned issues.
Now the question is: are synthetic datasets of facial images “good enough” for training of face recognition models? Namely, what is the optimal way to incorporate synthetically generated images into the training of face recognition models? In order to address these questions, the authors propose SynFace, an approach that combines real and synthetic facial data to improve the performance of face recognition models.

{kind=link}
Figure 1: Real (the first row) and synthetic (second row) face images
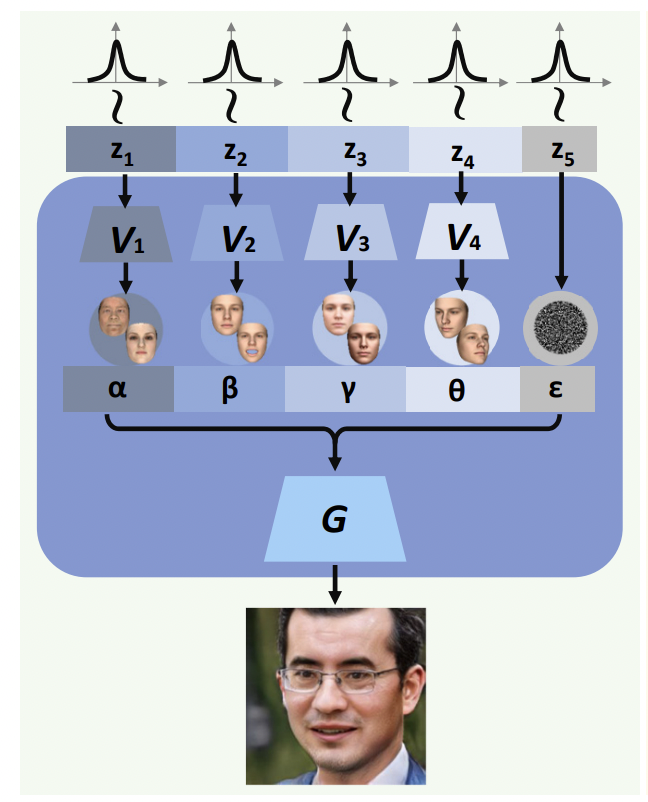
Synthetic data is usually created by generative models. The paper used DiscoFaceGAN, which is capable of synthesizing diverse face images for a given set of the essential face image parameters (latent variables). This set contains four parameters: identity α, expression β, pose θ and lighting conditions γ.
{kind=link}
Figure 2: Image generation with DiscoFaceGAN
Main Idea of the Paper:
First, the authors compared the performance of two face recognition classifiers trained with real and synthetic data, respectively. As it turned out, when tested on real data, models trained on synthetic data performed worse than those trained on real data. The paper points out that there are 2 main reasons for the inferior performance of models, trained on synthetic data:
- A lack of intra-class variability: there is too much similarity between face images of the same identity.
- Domain gap between synthetic and real facial images: simply put, synthetic images “look different״ from the real ones (have dissimilar features).
Remark: To assess a performance gap between models, trained on real and synthetic data, the authors trained a neural network, proposed in ArcFace, which uses a margin-based softmax loss function for a face recognition task. Next two synthetic facial images datasets, denoted by Syn_10K_50 and Syn-LFW, based on CASIA-WebFace and LFW respectively, were generated by using DiscoFaceGAN. Then face recognition models were trained on CASIA-WebFace and Syn_10K_50 and their performance were evaluated on LFW and Syn-LFW.

In order to cope with these limitations, the authors proposed to utilize a technique known as mixup, which is widely used for data augmentation in deep learning. Mixup generates weighted (convex) combinations of random image pairs from the training data. An augmented image z is created by combining x and y as follows:
z = ϕx + (1 – ϕ)y, 0 < ϕ < 1
The paper suggests applying two mixup techniques to reduce the performance gap between real and synthetic images:
Identity Mixup (IM): Basically, the authors propose to generate images by “mixing up” facial images of different individuals. As opposed to most mixup applications, here mixup up is performed in the latent space and not in the original image domain. IM is performed on the latent representations of identity latent vectors α1 and α2 in the following fashion:
α = ϕ α1 + (1 – ϕ)α2 , 0 < ϕ < 1
Note that α1 and α2 are generated by feeding normally distributed vectors Variational AutoEncoder V1(see Fig.2), which is a building block of DiscoFaceGAN.
The resulting face image is then synthesized by the DiscoFaceGAN generator with the other face parameters μ = [β, γ, θ]) (expression, pose and illumination respectively). Note that the label η of the “mixed-up” image is naturally derived as a convex combination of the “mixed-up” images’ labels:
η = ϕ · η1 + (1 − ϕ) · η2 , 0 < ϕ < 1
Domain Mixup (DM): Low intra-class variability of synthetically generated face images is a major contributing factor to the domain gap between real and synthetic images. To reduce this gap, the authors proposed to perform a mixup between real and synthetic domains. Namely, they suggest to generate a new “mixup” face image X from real and synthetic face images in the following fashion:
X = ψ · XS + (1 − ψ) · XR , 0 < ψ < 1,
where XR is a real face image and XS is the synthetic one. Note, that compared to IM, DM is performed in the original image space and not in the embedding space. The label for the “mixed-up” is built similarly to IM with the convex combination of the labels YS and YR of XS and XR:
Y = ψ · YS + (1 − ψ) · YR.
YS and YR are labels of real and synthetic images.
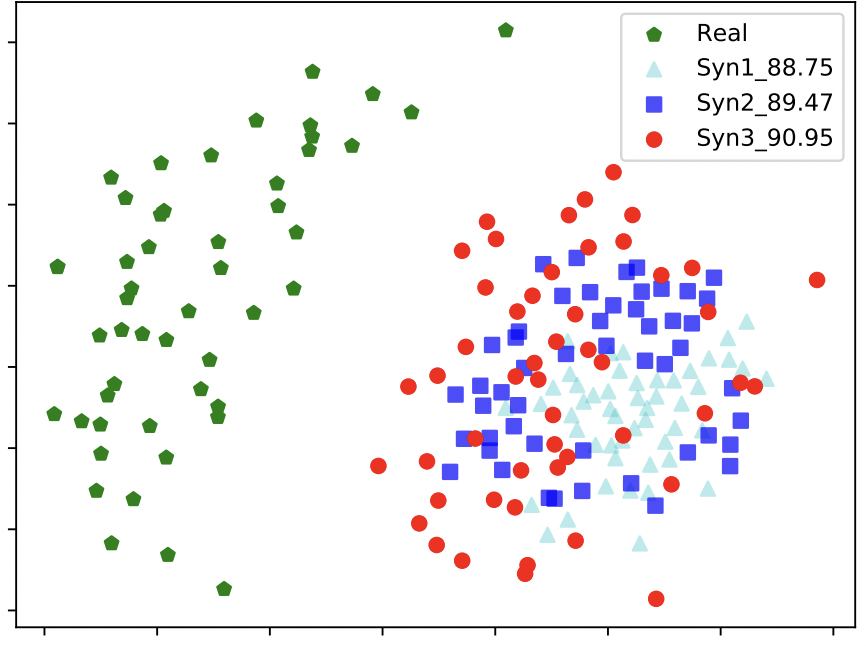
It is important to understand that the more images are generated using IM, the more intra-class variability the resulting dataset will contain. Furthermore, the paper shows (experimentally) that the higher the intra-class variation, the better the face recognition model performs (see Fig. 3).
Remark: Intra-class variation is assessed for the dataset made up of the “mixed-up” fake identities, generated with IM for different pose, expression and illumination parameters. Recall that these fake identities are generated with DiscoFaceGAN by feeding vectors, sampled from a normal distribution, into Variational AutoEncoder V1 of DiscoFaceGAN (see Fig. 1).
{kind=link}
Figure 3: Intra-class variations of datasets Syn1, Syn2 and Syn3 are increasing, leading to the consistent improvements on accuracy (88.75% → 89.47% → 90.95%). Syn1 is built without DM, Syn2 with ϕ =0.8 and for Syn3 ϕ is randomly sampled from the linear space which varies from 0.6 to 1.0(i.e., np.linspace(0.6, 1.0, 11)). Green points are embedding of face images of the same individual from the real-world dataset. Blue, red and light blue point represent embedding of the same individual face images for several synthetic/mixed-up datasets
SynFace Architecture:
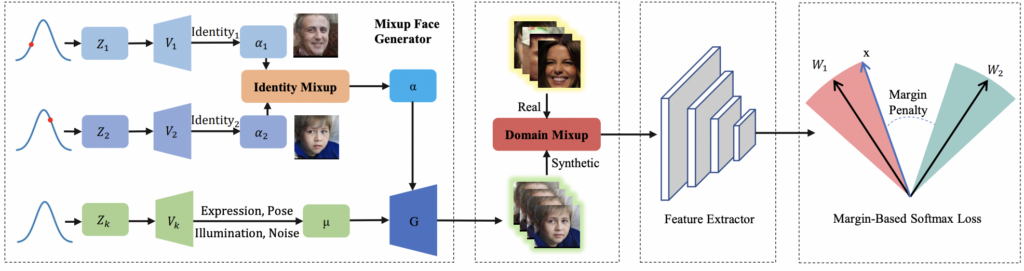
Now we outline the SynFace architecture. First IM is incorporated into DiscoFaceGAN to form the Mixup Face Generator. It allows for synthesizing face images with “mixed-up” identities while other face image parameters (pose, illumination and expression) are generated by DiscoGAN. Next, the face images with “mixed-up” identities are combined with real face images via DM and the output is fed to a deep feature extractor. The extracted features are used to compute the margin-based softmax loss which is utilized for model training. In addition, the extracted features can be exploited for face identification and verification tasks.
{kind=link}
Figure 4: SynFace Architecture
Performance Results:
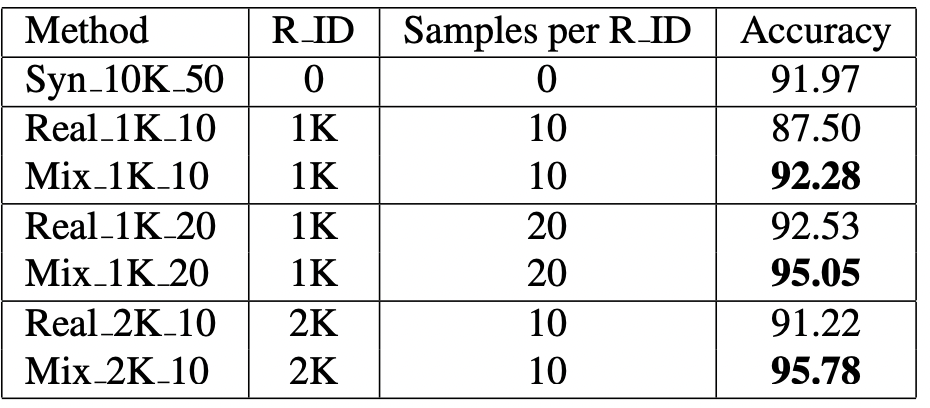
The authors used CASIA-WebFace for training and LFW datasets for testing their face recognition models. A number of experiments have been conducted demonstrating that identity and domain mixup improve the accuracy of face recognition models (see for example Table 2). Syn_10K_50 is a synthetically generated dataset containing facial images of 10K identities with 50 samples per identity. Mix_N_S is a mixture of N real identities with S images per identity with Syn_10K_50.
{kind=link}
Table 2: Face verification accuracies of models trained on synthetic, real and mixed datasets on LFW. R ID means the number of real identities.
Conclusions:
The paper explored the potential of using synthetic data for training face recognition models. The researchers showed that synthetically generated face images can substantially improve face recognition model performance while mixed with real facial images. This performance boost is achieved via applying identity and domain mixup techniques, presented in the paper. It is worthwhile to point out that performance improvement demonstrated by the authors was achieved with very little real data. Therefore, we do not necessarily have to obtain large real datasets of facial images to build high-performance face recognition models.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
