
























Task2Sim: Towards Effective Pre-Training and Transfer from Synthetic Data

Review:
Neural network (NN) models pretraining on large datasets, like ImageNet, became a standard procedure in computer vision in the last years. Model pre-training is especially effective when only a small amount of data is available for training. In this case, training highly expressive models, for example large-scale neural networks, may lead to overfitting and model pre-training is one of the means to reduce it (overfitting).
Synthetic data, generated by a graphic simulator, can be leveraged to enrich datasets used for model pre-training. Naturally, downstream task performance (e.g. accuracy) of a model, pretrained with synthetic data, depends on the synthetic data characteristics. For example, synthetic data generated with different simulator parameters (e.g. lighting, object pose, backgrounds, etc.) usually leads to different downstream task performance. It is therefore worthwhile to customize pre-training data based on downstream tasks.
Now the question is whether it is possible to optimize synthetic data simulator parameters to maximize pre-trained model performance for a specific downstream task? The paper addresses the aforementioned problem by proposing a technique, called Task2Sim, which is designated to determine the best simulator parameters for a given downstream task. Task2Sim is trained on a set of downstream tasks (called “seen” tasks in the paper) and was shown to be able to predict best simulation parameters for “unseen” tasks without need of additional training.
Task2Sim Architecture:
Finding optimal simulator parameter configuration is a challenging problem due to a high number of possible simulator parameters. As a result, the number of possible parameter configurations is very large (and grows exponentially with every parameter added), making a brute force approach impractical. Instead, Task2Sim trains a neural network, mapping downstream task representation into an optimal configuration of simulator parameters.
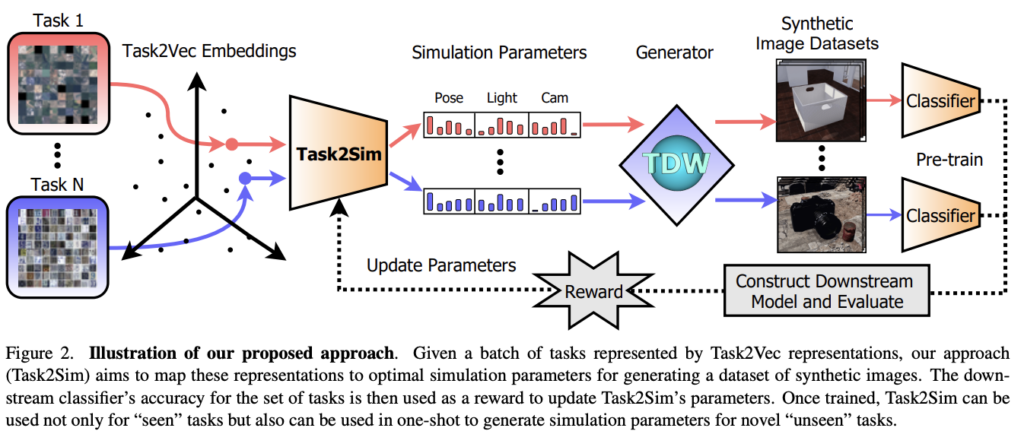
To construct such mapping we need downstream task representation, aka task embedding vector. Such representation should reflect semantic similarity between tasks. For example, representation of a cat breed classification task should be much closer to a dog breed classification task than to a truck classification task. Fortunately, technique for constructing task representation was developed in the paper TASK2VEC: Task Embedding for Meta-Learning. This technique, called Task2Vec, is capable of building fixed-dimensional embedding for a variety of visual tasks, while the task is represented by its dataset with ground truth labels. A major advantage of Task2Vec embedding is the fact that it does not rely on any knowledge of class label semantics and doesn’t depend on the number of classes. Therefore Task2Vec can be leveraged to represent a wide spectrum of visual tasks.
Now our objective is to train a model predicting the simulator configuration, achieving maximal accuracy, for a Task2Vec representation of a given downstream task. Simply put, vector representation of a downstream task is fed into a NN, called Task2Sim, which maps this vector to synthetic data generator parameters (e.g. a blur amount, lighting direction, backgrounds, etc). Then the data simulator (the authors used Three-D-World platform) generates a dataset of synthetic images based on these parameters. A NN-based classifier is pretrained on these synthetic images, and its accuracy is used to update Task2Sim’s parameters based on the pre-trained classifier performance on the downstream task.
Task2Sim NN outputs a distribution over quantized values (e.g. several blur amount levels or lightning directions) of each simulation parameter. Denoting the number of simulator parameters by M, Task2Sim output is M distributions ![]() over the simulator parameters.
over the simulator parameters.
Task2Sim Training
As a key objective of Task2Sim is to maximize downstream task accuracy after pre-training, this accuracy serves as a measure of the training success. The paper assumes that downstream task accuracy is not a differentiable function of the simulator parameters, which enables usage of any graphic simulator as a black box. Therefore, gradient-based training methods cannot be used for Task2Sim optimization. Instead, the paper leverages the REINFORCE algorithm to estimate the gradient of downstream task performance with respect to Task2Sim parameters.
REINFORCE is a classic reinforcement learning (RL) algorithm belonging to a family of policy-gradient methods. A RL algorithm goal is to determine the policy with a maximum reward, while policy is a strategy for picking a particular action at a given time. Policy gradient methods are iterative techniques for modeling and optimizing policy directly. However, what are rewards, policy, and action in our case?1
Naturally a reward is the downstream task accuracy after pre-training for a dataset generated with a given configuration of simulator parameters. A simulator parameter configuration is actually the “action” leading to a reward. An “action” is a vector ![]()
![]() of simulator parameter configuration, where
of simulator parameter configuration, where ![]() is a value of i-th simulator parameter. This parameter configuration is fed to the simulator to build a synthetic dataset. This dataset is used to pretrain a model and then downstream task performance (reward!!) is estimated with the pretrained model.
is a value of i-th simulator parameter. This parameter configuration is fed to the simulator to build a synthetic dataset. This dataset is used to pretrain a model and then downstream task performance (reward!!) is estimated with the pretrained model.
A policy is M distributions of simulator parameters, generated by Task2Sim NN. i-th configuration parameter is generated from distribution ![]() .
.
In formal terms, an action ![]()
![]() can be generated by sampling from these M distributions. Probability of action is defined by:
can be generated by sampling from these M distributions. Probability of action is defined by: 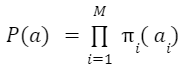 and
and ![]() is the distribution of the parameter of the i-th simulator. An “action” distribution is computed by feeding task-embedding Task2Vec to Task2Sim models. Then the following function is maximized with respect to Task2Sim NN parameters
is the distribution of the parameter of the i-th simulator. An “action” distribution is computed by feeding task-embedding Task2Vec to Task2Sim models. Then the following function is maximized with respect to Task2Sim NN parameters ![]() :
:
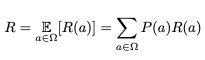
where Ω denotes space of all possible actions a and R(a) is the reward (downstream task accuracy) achieved when the training data is created with the action a (simulator parameters).
As we already mentioned, the authors used REINFORCE technique to update Task2Sim NN weights ![]() . REINFORCE updates these weights, using the gradient of reward R with respect to
. REINFORCE updates these weights, using the gradient of reward R with respect to ![]() , which is estimated by the following expression:
, which is estimated by the following expression:
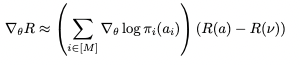
where R(a) is approximated by a single sample ![]()
![]() from distribution over configuration P(a) and
from distribution over configuration P(a) and ![]() is the set of configuration parameters corresponding to the mode (argmax) values of distributions
is the set of configuration parameters corresponding to the mode (argmax) values of distributions ![]() 2
2
NN weights θ are updated using mini-batches of downstream tasks sampled from a set of “seen” tasks. In addition, the paper updates these weights via “replaying” high-reward actions encountered in the past (self-imitation learning).
Performance Evaluation and Results:
Task2Sim performance on a downstream task is estimated by applying a 5-nearest neighbors classifier on features generated by a backbone NN, on a dataset generated with the simulator parameters outputted by Task2Sim. In other words, the label for example x is determined by the labels of 5 labeled examples that are closest to x in the feature space. Apparently, this technique is faster than the commonly used techniques for transfer learning methods evaluation, such as linear probing or full network finetuning.
The tables below contain the comparison of Task2Sim performance with several other performance methods.
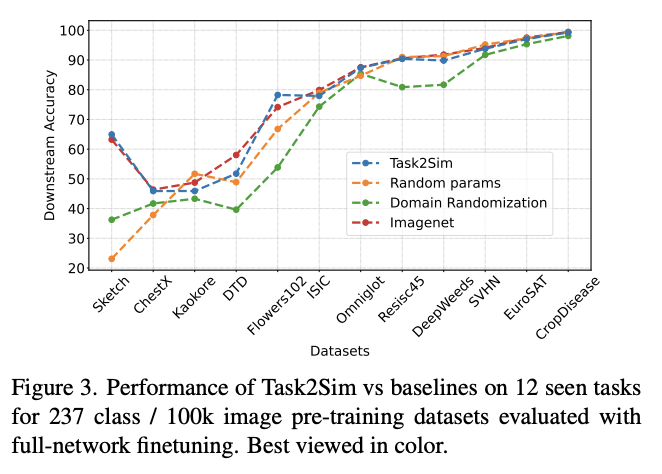
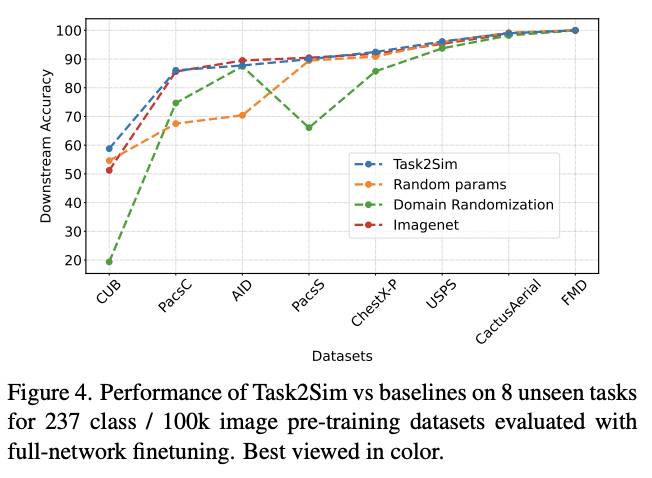
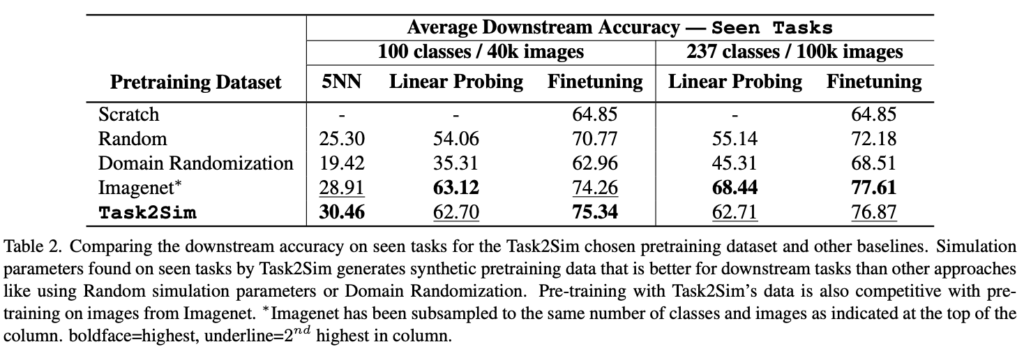
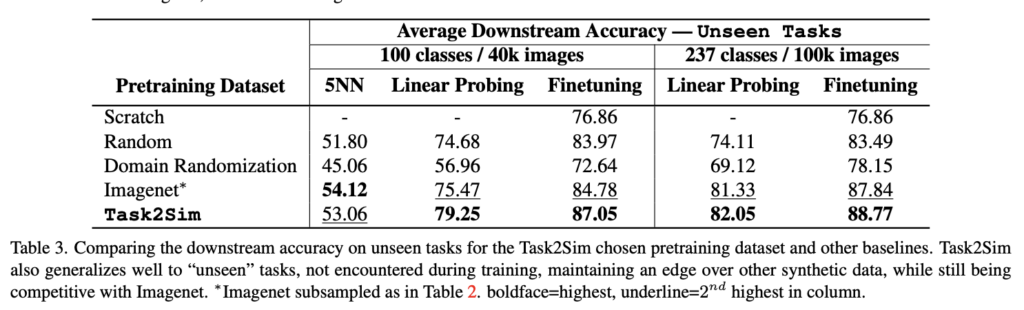
Task2Sim significantly outperforms two “basic” model pretraining approaches: “Random” (simulator parameters chosen at random) and “Domain Randomization” (Uses all variations from simulation in each image) on 12 downstream tasks. This conclusion holds for both seen (pre-training is performed on downstream tasks) and for the unseen tasks configurations (model is NOT pretrained on downstream tasks). In addition, Task2Sim performance is almost as good as that of ImageNet data pretraining on seen tasks, and it is even better on the unseen tasks. The latter is really impressive: it means that synthetic data, generated with Task2Sim allows for building (pretraining) more robust models, even than with the real data.
Footnotes:
- The RL framework, proposed by the paper, does not involve any state and thus can be viewed as either a stateless RL or contextual bandits problem.
- In fact, the authors propose to sample from a noised version of the simulator parameters(action) distribution to encourage exploration of the “action space”.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
