
























10 Promising Synthesis Papers from CVPR 2021

The 2021 Conference on Computer Vision and Pattern Recognition (CVPR) has just commenced. With topics running the gamut from autonomous driving to medical imaging, CVPR 2021 features an exciting lineup of state-of-the-art technology that shows tremendous potential for practical applications. Navigating the labyrinth of highly information-dense papers is not exactly a walk in the park. Thus, we distilled ten promising CVPR papers related to three broad themes – image synthesis, scene reconstruction, and motion synthesis.
Control over GANs in Image Synthesis
“We don’t have better algorithms. We have more data,” said Google’s Research Director Peter Norvig. This aptly reflects the pervasive mantra of “more data is (generally) better” in the machine learning community. In the realm of computer vision, recent years have seen the advent and advancement of Generative adversarial networks (GANs) in synthesizing and editing photorealistic images.
However, computer vision practitioners lament the lack of control over the images synthesized by such generative models – and rightly so. Here, we explore some CVPR 2021 papers that boast to provide more control in the process of generating images. These advancements represent a step towards the widespread adoption of GAN.
1.GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields (Github)
The task of controlling the objects in the generated image requires the model to reason in 3D. This is by no means trivial for models that operate in 2D space. To solve this, the paper introduces a compositional 3D scene representation in the model, allowing the control of the position, orientation and perspective of objects independently.
The model is capable of first identifying objects in the foreground and the background before changing their position, orientation and perspective. It then combines all the objects to generate an output image. In this example, a model that is trained on a collection of images of cars can generate images of cars of different sizes, positions, and orientations. GIRAFFE is also capable of changing the backgrounds and even the number of cars in the scene.

2. IMAGINE: Image Synthesis by Image-Guided Model Inversion
IMAGINE, the IMage-Guided model INvErsion (IMAGINE) Method generates high-quality and diverse images from one single image without the need to train a generator. One of its key features is its ability to enforce constraints over semantics (like shape and location of the object) during the synthesis process and provides users intuitive control over the control. Unlike its predecessors like SinGAN which struggles to create non-repetitive objects, IMAGINE creates high-quality images of non-repetitive images.

Watch On-Demand “Implementing Data-Centric Methodology with Synthetic Data” with Meta and Microsoft
3. HistoGAN: Controlling Colors of GAN-Generated and Real Images via Color Histograms (Paper)
Another aspect of GAN that was difficult to control was the color of the images. Inspired by a class histogram-based color transfer method, researchers at the Technical University of Munich and Google developed HistoGAN.
HistoGAN leveraged StyleGAN2’s architecture by modifying the last 2 blocks of the StyleGAN to incorporate histogram features. Thus, by incorporating a target color histogram as part of the input to the HistoGAN, one can control the tones of the image.

The use of histogram as a lever to change the colors in images is intuitive and domain-independent, allowing images from different domains and practitioners to potentially use HistoGAN. The effect of the target color on the generated images is visible in the HistoGAN figure above
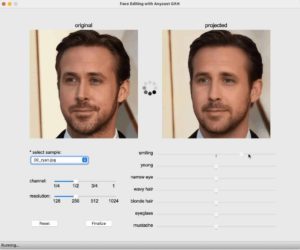
4. Anycost GANs for Interactive Image Synthesis and Editing (Github | Paper)
The high computation cost of state-of-the-art networks like StyleGAN2 has prohibited users from generating images instantaneously and interactively. Today, a full generator takes approximately 3 seconds to render an image, which is too slow for many purposes. This problem heralded Anycost GAN for interactive natural image editing.
With Anycost GAN, users can control to generate images at lower channel and resolution configurations in exchange for faster results and lower computational cost. With such controls, users can potentially generate visually similar images at 5x faster speed.
This finding paves the way for users to generate images at various cost budgets and hardware requirements, representing a step of democratizing GANs to users without computational resources.
Synthesis of Dynamic Objects and Humans
We have seen how GANs allow static images to be recreated and controlled. But what about dynamic images? In the next section, we see advancements in modeling and synthesizing objects in motion.
5. Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation
“We’re entering an era in which our enemies can make anyone say anything at any point in time,” those were the words of a President Obama reconstructed from hours of footage in 2018. Since then, the computer vision community has achieved the feat of creating talking heads with accurately synchronized lip movement from audio clips. However, the problem of controlling the poses of the talking head is challenging and represents the bottleneck to generating talking heads with personalized rhythmic head movements.
The Pose-Controllable Audio Visual System (PC-AVS) promises to address that by achieving free pose control while creating arbitrary talking faces with audios. PC-AVS can transform a single photo of an actor, an audio clip, and a source video of another actor’s pose into a realistic talking head. This method outperformed existing methods like Rhythmic Head (Chen et al) and MakeitTalk (Zhou et al) especially under extreme conditions of the audio, like when the audio is noisy.

6.Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans (GitHub)
How many video cameras does one need to recreate human actions in 3D accurately? It used to take a room full of cameras for a decent chance, especially for complex body movements like dancing. It now takes as few as four cameras thanks to Neural Body, an implicit neural representation with structured latent codes.
The task, formally known as the novel view synthesis, was possible with a dense array of monocular cameras but seemingly improbable with sparse multi-view video. The model cannot rely entirely on piecing multiple 2D images to create 3D views. Instead, the model learns to piece together multiple 2D images on a deformable mesh and integrate observations across frames.
Watch On-Demand “Implementing Data-Centric Methodology with Synthetic Data” with Meta and Microsoft
Synthesis of Novel Views
Last year saw the introduction of the highly popular Neural Network Fields (also known as NeRF). A simple fully connected network trained, NeRF was regarded as one of the best solutions to synthesize novel views of complex scenes using multiple pictures with state-of-the-art results. This year, researchers extended NeRF by enabling quicker and more advanced scene reconstruction.
7. pixelNeRF: Neural Radiance Fields from One or Few Images (Website)
Using NeRF, one needs to optimize the model for hours, if not days, on multiple views of the same scene in pursuit of synthesizing high-quality images, as shown below.

pixelNeRF addressed the shortcomings of NeRF by promising to reproduce novel views with much fewer views of the scene in a significantly shorter time. It achieves this by introducing an architecture that enables the network to be trained across multiple scenes to learn a prior scene. For instance, with only three input views, pixelNeRF produced superior results than NeRF. This can potentially reduce the cost of synthesizing views by requiring less computation and fewer input images, making such technology more accessible.

8. NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis (Paper | Video | GitHub)
While NeRF allows the rendering of the same scene from novel views, it does not provide a way to reproduce the same scene with novel lighting conditions. Therefore, researchers at Google, MIT and Berkeley proposed NeRV, Neural Reflectance and Visibility Fields for Relighting and View Synthesis. NeRV takes in images of an object with known lighting and outputs its 3D representation from novel viewpoints under arbitrary lighting. This enables the relighting of objects and even a change in the material of the objects.


Scene Reconstruction
Today, 3D scene reconstruction in real-time has found applications in creating immersive Augmented Reality and Virtual Reality environments. This year, researchers took an interest in reconstructing scenes with much fewer resources than previously needed.
9. NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video (Github | Paper)
Current reconstruction technology is only practical with the presence of expensive specialized cameras with depth sensors. What if we can perform a 3D scene and object reconstruction using only monocular cameras like those on our smartphones? NeuralRecon can do so with videos captured by monocular cameras with known camera poses in real-time.
NeuralRecon’s real-time reconstruction is made possible by its relatively lower computational cost than existing state-of-the-art methods like Atlas. Impressively, a NeuralRecon model trained on indoor data could reconstruct homogenous textures like walls effectively and generalize to outdoor scenes well.
It is conceivable for smartphones to leverage the NeuralRecon network to create realistic scenes in real-time, potentially catalyzing the mainstream adoption of AR and VR shortly.
Prediction of Protein Interactions
The scientific community was in awe when DeepMind announced that AlphaFold, its attention-based neural network algorithm, has successfully solved the 50-year-old grand challenge in biology – the protein-folding problem. This was a testament that deep learning is a potent solution to existing problems in protein science.
10. Fast End-to-End Learning on Protein Surfaces (Paper)
Another problem in protein science is to identify the interaction sites of proteins and by extension how proteins bind with one another (due to their structural and chemical characteristics). In this paper, the authors showed that computer vision can be used to address these two problems with high accuracy without pre-computed hand-crafted chemical and geometric features of the proteins. As a result, computations can be made on the fly with a small memory footprint, making it practical to make such predictions on a larger collection of protein structures.
This paper achieved state-of-the-art performance with faster run times than previous models. This breakthrough in the modelling of protein can enable the prediction of protein function and catalyze the design of synthetic proteins. This development, together with other deep learning approaches, might prove to be one of the keys to solving many of the open problems in protein science.
CVPR 2021: Image Synthesis is the Future
In this conference, we learn of the impressive progress made in the computer vision space. Particularly, instead of delegating control to black-boxes, practitioners can look forward to better control in the process of generating novel images and videos. We also marveled at the community’s advances in recreating motion more accurately and its creativity in applying computer vision to protein science.
The 2021 CVPR is a testament to the resourcefulness of the computer vision community in advancing image generation technology. We are confident that this community of committed practitioners keep the image generation technology bustling with rapid breakthroughs in years to come. We are incredibly excited to keep pace with such development as we continue advancing our capabilities in photo-realistically recreating the world around us. Today, we work with the most innovative companies in the world to fuel and accelerate their computer vision development and are backed by some of the most respected investors in the space.
Watch On-Demand “Implementing Data-Centric Methodology with Synthetic Data” with Meta and Microsoft
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
