
























Neural Radiance Field (NeRF): A Gentle Introduction

A neural radiance field (NeRF) is a fully-connected neural network that can generate novel views of complex 3D scenes, based on a partial set of 2D images. It is trained to use a rendering loss to reproduce input views of a scene. It works by taking input images representing a scene and interpolating between them to render one complete scene. NeRF is a highly effective way to generate images for synthetic data.
A NeRF network is trained to map directly from viewing direction and spatial location (5D input) to opacity and color (4D output), using volume rendering to render new views. NeRF is a computationally-intensive algorithm, and processing of complex scenes can take hours or days. However, new algorithms are available that dramatically improve performance.
In This Article
NeRF and Neural Rendering: Basic Concepts
In order to understand how NeRF works, let’s cover some basic concepts.
Rendering
Rendering is the process of creating an image from a 3D model. The model will contain features such as textures, shading, shadows, lighting, and viewpoints, and the role of the rendering engine is to process these features to create a realistic image.
Three common types of rendering algorithms are rasterization, which projects objects geometrically based on information in the model, without optical effects; ray casting, which calculates an image from a specific point of view using basic optical laws of reflection; and ray tracing, which uses Monte Carlo techniques to achieve a realistic image in a far shorter time. Ray tracing is used to improve rendering performance in NVIDIA GPUs.
Volume Rendering
Volume rendering enables you to create a 2D projection of a 3D discretely sampled dataset.
For a given camera position, a volume rendering algorithm obtains the RGBα (Red, Green, Blue, and Alpha channel) for every voxels in the space through which rays from the camera are casted. The RGBα color is converted to an RGB color and recorded in the corresponding pixel of the 2D image. The process is repeated for every pixel until the entire 2D image is rendered.
View Synthesis
View synthesis is the opposite of volume rendering—it involves creating a 3D view from a series of 2D images. This can be done using a series of photos that show an object from multiple angles, create a hemispheric plan of the object, and place each image in the appropriate place around the object. A view synthesis function attempts to predict the depth given a series of images that describe different perspectives of an object.
How Neural Radiance Fields Work
A NeRF uses a sparse set of input views to optimize a continuous volumetric scene function. The result of this optimization is the ability to produce novel views of a complex scene. You can provide input for NeRF as a static set of images.
A continuous scene is a 5D vector-valued function with the following characteristics:
- Its input is a 3D location x = (x; y; z) and 2D viewing direction (θ; Φ)
- Its output is an emitted color c = (r; g; b) and volume density (α).
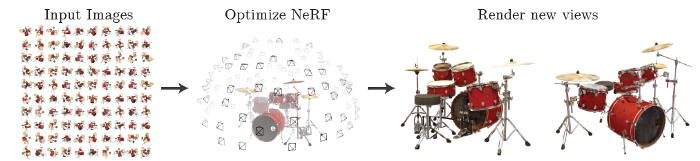
Image Source: NeRF Paper (Mildenhall1, Srinivasan1, Tancik, et. al), 2020
Here is how you can generate a NeRF from a specific viewpoint:
- Generate a sampled set of 3D points—by marching camera rays through the scene.
- Produce an output set of densities and colors—by inputting your sampled points with their corresponding 2D viewing directions into the neural network.
- Accumulate your densities and colors into a 2D image—by using classical volume rendering techniques.
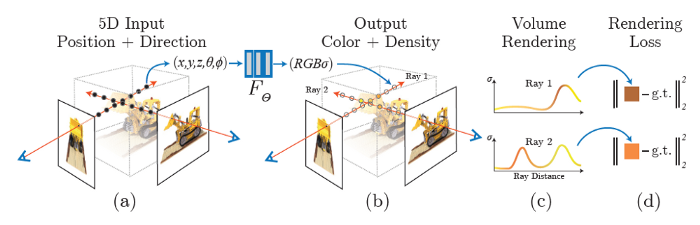
Image Source: Matthew Tancik
The process above optimizes a deep, fully-connected, multi-layer perceptron (MLP) but does not require using convolutional layers. It uses gradient descent to minimize errors between each observed image and all corresponding views rendered from the representation.
Improving NeRF Performance
The original NeRF model had several drawbacks—it was slow to train and render, only able to handle static scenes. It is also inflexible, because a NeRF model trained on one scene cannot be used for other scenes.
Here are several methods that build on NeRF and attempt to resolve some of its problems.
RegNeRF
RegNeRF (CVPR 2022) stands for regularizing neural radiance fields (RegNeRF) for view synthesis from sparse inputs. It helps address a problem in the performance of neural radiance fields (NeRF), when the number of input views is low.
Research indicates that most artifacts in sparse input scenarios occur due to errors in the estimated scene geometry and divergent behavior during the beginning of training. Regularizing the appearance and geometry of patches rendered from unobserved viewpoints helps address this issue. The authors also proposed annealing the ray sampling space during the training process as a solution. The paper additionally uses a normalizing flow model to regularize the color of unobserved viewpoints.
pixelNeRF
The pixelNeRF (CPVR 2021) learning framework can predict a continuous neural scene representation based on one or several input images. Constructing NeRFs typically requires optimizing the representation of each scene independently, which involves many calibrated views and significant compute time.
This learning framework addresses these issues by introducing an architecture that uses a fully convolutional approach to condition the NeRF on image inputs. It enables training the network across several scenes to learn a scene prior, ensuring it can perform novel view synthesis in a feed-forward manner using as few views as possible (even one).
Mega-NeRF
Mega-NeRF (CVPR 2022) is a learning framework that uses NeRFs to build interactive 3D environments from large-scale visual captures, such as buildings and multiple city blocks collected mainly by drones. Traditionally, NeRFs are evaluated using single-object scenes. However, this method poses several challenges.
Traditional NeRFs require modeling thousands of images with diverse lighting conditions, each capturing only a small part of a scene and making it difficult to achieve the fast rendering that enables interactive fly-throughs. Additionally, these prohibitively large models require capacities that make it infeasible to train on one GPU.
Mega-NeRF addresses these challenges by analyzing visibility statistics for large-scale scenes. This requires a sparse network structure where parameters are specialized to different scene regions. It introduces a simple geometric clustering algorithm for data parallelism, which separates training images (or pixels) into different NeRF submodules that can be trained in parallel.
LOLNeRF
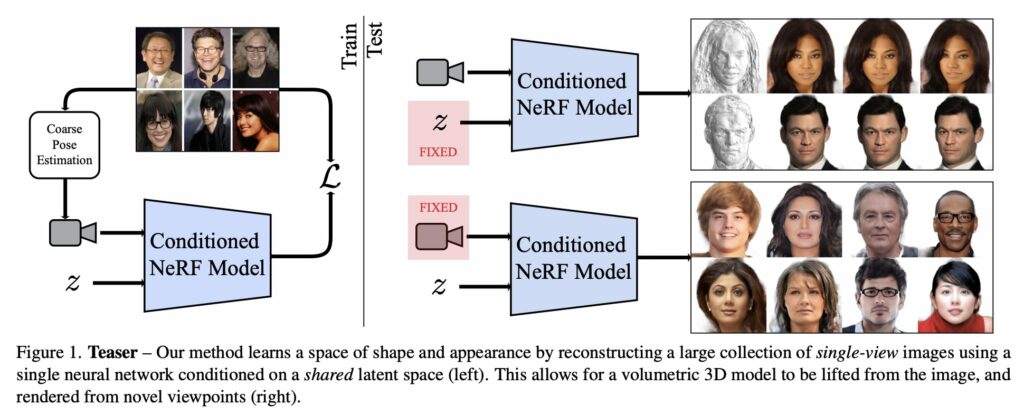
LOLNeRF (CVPR 2022) stands for Learn from One Look (LOL). This learning method uses NeRF for generative 3D modeling, training only from data with primarily single views of each object. It helps produce the corresponding 3D structure of objects in a way they can be rendered from different views.
This method uses the reconstruction of many images aligned to an approximate canonical pose with a single network conditioned on a shared latent space for learning a space of radiance fields that models shape and appearance for a class of objects. It involves training models to use datasets containing only one view of each subject to reconstruct object categories without depth or geometry information.
Neural Sparse Voxel Fields (NSVF)
NSVF (NeurIPS 2020) is a neural scene representation that enables fast, high-quality rendering that is not dependent on a specific viewpoint. It works by defining voxel-bounded implicit fields organized in a sparse network of cells, and progressively learns voxel structures in each cell of the network. It can render new views much faster by skipping voxels with no scene content—this technique makes NSVF over ten times faster than the original NeRF.
Mip-NeRF
Mip-NerF (ICCV 2021) extends the original NeRF model with the objective of reducing blurring effects and visual artifacts. NeRF used a single ray per pixel, which often caused blurring or aliasing at different resolutions. Mip-NeRF uses a geometrical shape known as a conical frustum to render each pixel, instead of a ray, which reduces aliasing, makes it possible to show fine details in an image, and reduces error rates by between 17-60%. The model is also 7% faster than NeRF.
KiloNeRF
KiloNeRF (2021) addresses the problem of slow rendering in NeRF, which is mainly related to the need to query a deep MLP network millions of times. KiloNeRF separates the workload among thousands of small MLPs, instead of one large MLP which needs to be queried many times. Each small MLP represents part of a scene, enabling 3X performance improvement with lower storage requirements, and comparable visual quality.
Plenoxels
Plenoptic voxels (2021) (Plenoxels) replace the MLP in the center of NeRF with a sparse 3D grid. Each query point is interpolated from its surrounding voxels. New 2D views are hence rendered without running a neural network, which greatly reduces complexity and computational requirements. Plenoxels provide a similar visual quality to NeRF while being two orders of magnitude faster.
Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
