
























What is Synthetic Data Generation?

Machine learning projects require large datasets with accurately labeled real-world data. Typically, the larger and more diverse the dataset, the better the model performance will be. However, it can be difficult and time consuming to collect the required volume of data samples and label them correctly. A growing alternative to real-world datasets is synthetic data.
Instead of collecting and labeling large datasets, there are several techniques for generating synthetic data that has similar properties to real data. Synthetic data has major advantages, including reduced cost, higher accuracy in data labeling (because the labels in synthetic data are already known), scalability (it is easy to create vast amounts of simulated data), and variety. Synthetic data can be used to create data samples for edge cases that do not frequently occur in the real world.
You can create synthetic data for any type of dataset—from simple tabular data to complex unstructured data such as images and video. We’ll discuss several techniques for generating synthetic data, with a special focus on the challenge of generating synthetic images for computer vision projects.
In This Article
3 Techniques for Generating Synthetic Data
Generating Data According to a Known Distribution
For simple tabular data, you can create a synthetic dataset without starting from real data. The process starts from a good prior understanding of the distribution of the real dataset and the specific characteristics of the required data. The better your understanding of the data structure, the more realistic the synthetic data will be.
Fitting Real Data to a Distribution
For simple tabular data where a real dataset is available, you can create synthetic data by determining a best-fit distribution for the available dataset. Then, based on the distribution parameters, it is possible to generate synthetic data points (as described in the previous section).
You can estimate a best-fit distribution by:
- The Monte Carlo method—this method uses repeated random sampling and statistical analysis of the results. It can be used to create variations on an initial dataset which are sufficiently random to be realistic. The Monte Carlo method uses a simple mathematical structure and is computationally inexpensive. However, it is considered inaccurate compared to other synthetic data generation methods.
Neural Network Techniques
Neural networks are a more advanced method for generating synthetic data. They can handle much richer distributions of data than traditional algorithms such as decision trees, and can also synthesize unstructured data like images and video.
Here are three neural techniques commonly used to generate synthetic data:
- Variational Auto-Encoder (VAE)—an unsupervised algorithm that can learn the distribution of an original dataset and generate synthetic data via double transformation, known as an encoded-decoded architecture. The model formulates a reconstruction error, which can be minimized with iterative training. Learn more about VAE in the excellent post by Baptiste Rocca.

Images generated with a Variational Autoencoder (source: Wojciech Mormul on Github).
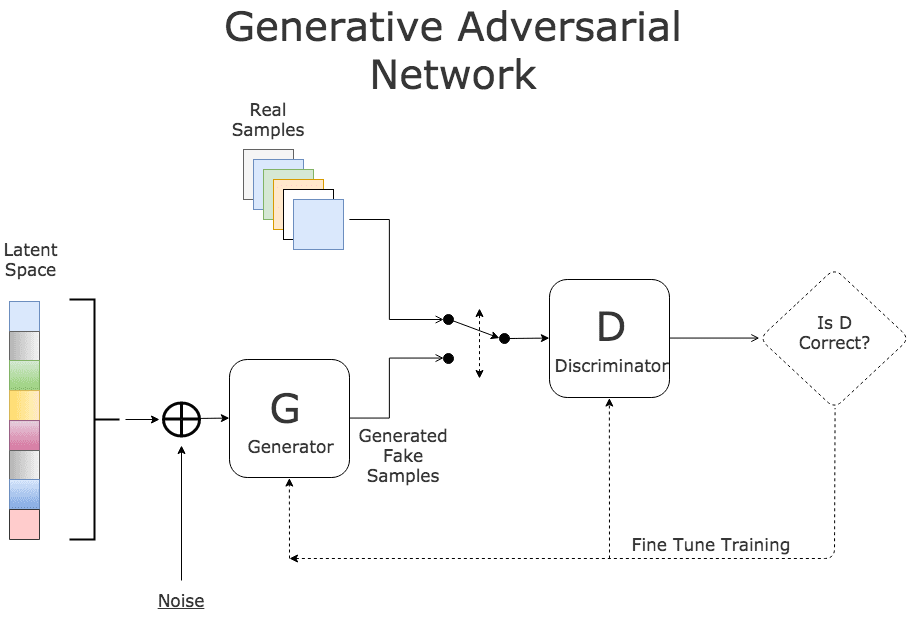
- Generative Adversarial Network (GAN)—an algorithm based on two neural networks, working together to generate fake yet realistic data points. One neural network attempts to generate fake data points while the other learns to differentiate fake and real samples. GAN models are complex to train and computationally intensive, but can generate highly detailed, realistic synthetic data points.

Source - Diffusion Models—algorithms that corrupt training data by adding Gaussian noise until the image becomes pure noise, then train a neural network to reverse this process, gradually denoising until a new image is produced. Diffusion models have high training stability and can produce high quality results for both image and audio.

Further in this article, we’ll explain how these techniques are applied to the challenge of generating synthetic images for computer vision projects.
A Process for Generating Synthetic Data
If you would like to generate synthetic data for a machine learning project, here are the general steps you should take to determine your approach:
- Determine business and compliance requirements—the first step is to understand the objectives of the synthetic dataset and for which machine learning processes it will be used. In addition, understand if there are constraints such as organizational policies or compliance standards, in particular privacy requirements, that affect your project.
- Determine which model to use—in the following section we present a few options, including Monte Carlo simulation, VAE, and GAN. The model you choose will determine the technical expertise required and the computational resources needed for the project.
- Build the initial dataset—most synthetic data techniques require real data samples. Carefully collect the samples required by your data generation model, because their quality will determine the quality of your synthetic data.
- Build and train the model—construct the model architecture, specify hyperparameters, and train it using the sample data you collected.
- Evaluate synthetic data—test the synthetic data created by your model to ensure it can be useful for your scenario. The best test is to feed synthetic data into your production machine learning model and evaluate its performance on real data samples. Use this feedback to tune your synthetic dataset to better suit the needs of the ML model.
Generating Synthetic Images for Computer Vision Projects
Synthetic data can be extremely useful for training computer vision algorithms. Computer vision models require large numbers of images that meet specific criteria, and traditionally these images were real-world images annotated by teams of human operators.
However, manual image annotation is costly and can be inaccurate, due to human error and subjective biases of the annotators. For example, it is very common to have different annotators assign a different label to the same image. This can be resolved by multiple people labeling the same image and using a majority vote to determine the best label.
Let’s review neural network models commonly used to create synthetic images.
Synthetic Image Generation with Variational Autoencoders (VAE)
VAEs are deep neural systems that can generate synthetic data for numeric or image datasets. They work by taking the distribution of a sample dataset, transforming it into a new, latent space, and then back into the original space. This is called an encoder-decoder architecture. The resulting space is evaluated and the model calculates a reconstruction error, which it tries to minimize over multiple training cycles.
To generate synthetic images, VAEs take in vectors representing real-world images, and generate output vectors that are similar, but not identical, to the source images. A VAE uses a layer of means and standard deviations to introduce variability, while ensuring that the output is not too different from the source images.
The main drawback of VAEs for synthetic image generation is that they generate blurry outputs, which also tend to be unrealistic. Recent research has suggested modifications to the original VAE model that can improve output quality.
Synthetic Image Generation with Generative Adversarial Networks (GAN)
GAN is a neural network architecture that can be used to generate highly realistic variations of real-world data. It uses two neural networks connected in a loop, where one neural network (the generator) attempts to create fake representations, and the other network (the discriminator) attempts to learn to distinguish real images from fake ones created by the generator. Eventually, the generator becomes very effective at generating fake data points.
GAN is being widely used to generate photorealistic images and videos, and its application to synthetic data is compelling. However, using GAN for synthetic data generation presents a few challenges:
- Models can be difficult to control and might not generate images that fit the requirements of the researcher.
- Training GAN models is time consuming and requires specialized expertise. It is also computationally intensive, requiring an investment in computing resources.
- GAN models can fail to converge—this means the generator and discriminator do not reach a balance and one overpowers the other, resulting in repetitive output.
- GAN models can collapse—this means GAN produces a small set of images with minor changes between them.
What Are Some Challenges of Synthetic Data Generation?
While there are many benefits to synthetic data, it presents some challenges:
- Data quality—quality is a key concern for training data, and is especially important for synthetic data. High-quality synthetic data captures the same basic structure and statistical distribution as the data on which it is based. However, in many cases synthetic data differs from real data in ways that can affect model performance.
- Avoid homogenization—diversity is critical to successful model training. If the training data is homogenous, focusing on specific types of data points and failing to cover others, the model will have poor performance for those other data types. Real data is highly diverse, and it is necessary to generate synthetic data that captures the full range of diversity. For example, a training dataset of human faces must show the full variety of ages, genders, and ethnicities the algorithm is expected to deal with.
Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
