
























Breakthroughs in Synthetic Data from NeurIPS 2022

Last year, we reported five top papers from NeurIPS 2021 in the field of synthetic data technology. NeurIPS is back this year, with more exciting developments. Here, we round up five noteworthy breakthroughs from NeurIPS 2022.
1. TotalSelfScan: Learning Full-body Avatars from Self-Portrait Videos of Faces, Hands, and Bodies
It is no secret that one can use 360-degree videos to reconstruct the model of a human. Yet, such methodology leaves much to be desired. While the body can be reconstructed with relatively high fidelity, it is often challenging to reconstruct the face and hands perfectly due to their relatively small sizes compared to the body.
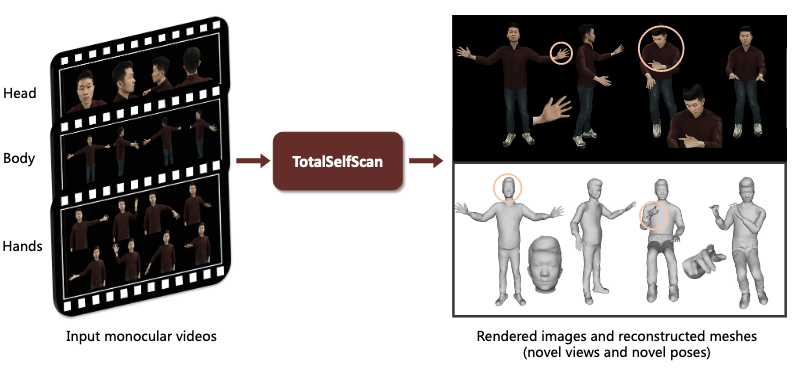
Dong et. al. proposed to solve the problem with TotalSelfScan (Figure 1), a new approach for body reconstruction based on not one, but multiple 360-degree scans of a person. Each scan focuses on the face, hand, and body respectively so that there is sufficient footage for the reconstruction of each part.
Not only that, TotalSelfScan proposes the use of multi-part representation to model the face, hand, and body respectively. Such a multi-part representation marks a departure from the existing method that represents the face, hand, and body in one representation. The observation from each part can then be combined into a single human model.
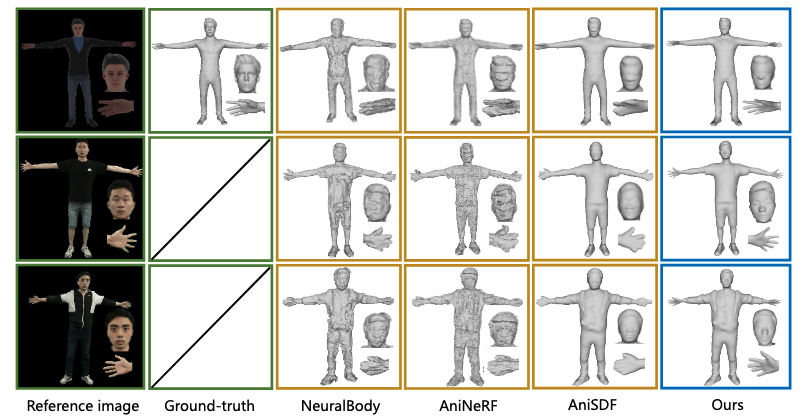
Such a modular approach gives the authors freedom to generate photorealistic videos from any angle for any human pose, a feat we can observe qualitatively from Figure 2 when comparing TotalSelfScan with existing state-of-the-art methods.
{kind=link}
2. Generalized One-Shot Domain Adaptation of Generative Adversarial Networks
The task of adapting a generative adversarial network (GAN) is not new. Numerous publications have successfully demonstrated that it is feasible to transfer a pre-trained GAN to a new target domain with little training data. Yet, few have investigated the possibility of doing so in one-shot (with a single target image).
That is why Zhang et. al. published the Generalized One-shot Domain Adaptation of Generative Adversarial Networks. With this finding, we can change the style of an existing StyleGAN given only one target image. (Figure 3)

The adaptation takes into consideration not only the transfer of the overall style but also of new entities in the source domains. To do so, each target image comes with an “entity mask”, which marks the section of the image containing the entity to be transferred. For example, note how the entities in the following target images (Figure 4, highlighted in green) are all successfully transferred from the source to the target.
Sign Up for Our Free Trial. Generate Your Free Dataset!

{kind=link}
The authors modified existing adaptation frameworks to achieve this feat. In particular, the authors used a new generator that has an extra auxiliary network that synthesizes the entities while the original generator generates the stylized image exclusively.
The qualitative results speak for themselves. The authors are able to achieve adaptation in various domains. Not only that, the adapted model can be used to perform semantic editing (Figure 5) and even entity removal (Figure 6).

{kind=link}
{kind=link}

3. D2NeRF: Self-Supervised Decoupling of Dynamic and Static Objects from a Monocular Video
Many research hours have been poured into decoupling a dynamic object from a static scene in a video. Yet, current solutions that solve this problem from a 2D perspective lack 3D understanding and have lackluster outcomes.
D2NeRF by the University of Cambridge and Google Research breathed fresh air into this task. It reconstructs a 3D scene representation and generates static and dynamic objects separately from any viewpoint in a time-varying fashion.
More specifically, the researchers adapted Neural Radiance Field (NeRF) to time-varying scenes by decoupling the static and dynamic objects of the scenes into separate radiance fields. The authors also propose a new loss function that allows the composite radiance fields to be learned without over-fitting.
The method produced amazing results. It can generate novel viewpoints of a static background even if it is heavily covered with moving objects and strong shadows (Figure 7). Apart from that, it can also correctly segment dynamic objects and shadows on 2D images.
D2NeRF can decouple and reconstruct 3D models of static backgrounds despite the distractions of a dynamic object

4. ShapeCrafter: A Recursive Text-Conditioned 3D Shape Generation Model
Machine learning practitioners are no strangers to text-to-image models like DALL-E and Stable Diffusion. These fascinating networks could generate fantastical portraits at the whim of a text prompt.
It is only natural to wonder if such successes in the 2D world can be extended to the 3D domain. The answer is yes, but with caveats.
The 3D shapes generated with existing text-to-shape methods cannot be recursively changed with another text prompt. That flies in the face of how humans describe shapes. We tend to start with a rough description of the initial shape and progressively furnish details that get us closer to the final desired shape.
That is why researchers from Brown University invented ShapeCrafter, a neural network for generating 3D shapes recursively based on text descriptions. ShapeCrafter is a tool for generating and editing 3D shapes from text prompts (Figure 8). The authors demonstrated the robustness of ShapeCrafter against long phrase sequences and even typos (Figure 9). Interestingly, it is even able to generalize to novel shapes that it has not seen during training.

{kind=link}
{kind=link}

{kind=link}

Better yet, the researchers noticed the dearth of text-to-3D-shape datasets and proposed the Text2Shape++ dataset which consists of 369 thousand shape-text pairs. Unfortunately, like Text2Shape, the dataset only supports chairs and tables for now.
5. LAION-5B: An Open Large-Scale Dataset for Training Next-Generation Image-Text Models
Despite the advent of revolutionary text-to-image models like CLIP and DALL-E, there has been a dearth of large-scale open-sourced text-to-image datasets. It’s about time that changes.
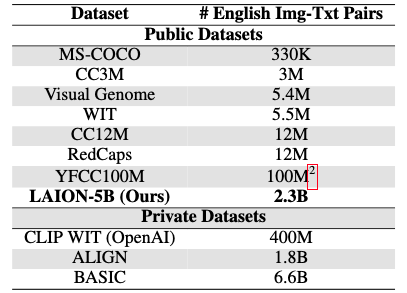
LAION-5B, a 5.85 billion image-text pairs, was introduced to democratize the research efforts on multimodal models. It contains an impressive corpus of English image-text pairs relative to existing datasets like MS-COCO and Visual Genome (Table 1). It also contains 2.2 billion samples from hundreds of other languages.
{kind=link}
The validity of the dataset is verified by recreating large-scale models like OpenAI’s CLIP models using the LAION-5B dataset. It was found that the models trained on LAION-5B performed equally well compared to OpenAI’s CLIP models on tasks running the gamut from zero-shot classification to image retrieval and fine-tuning.
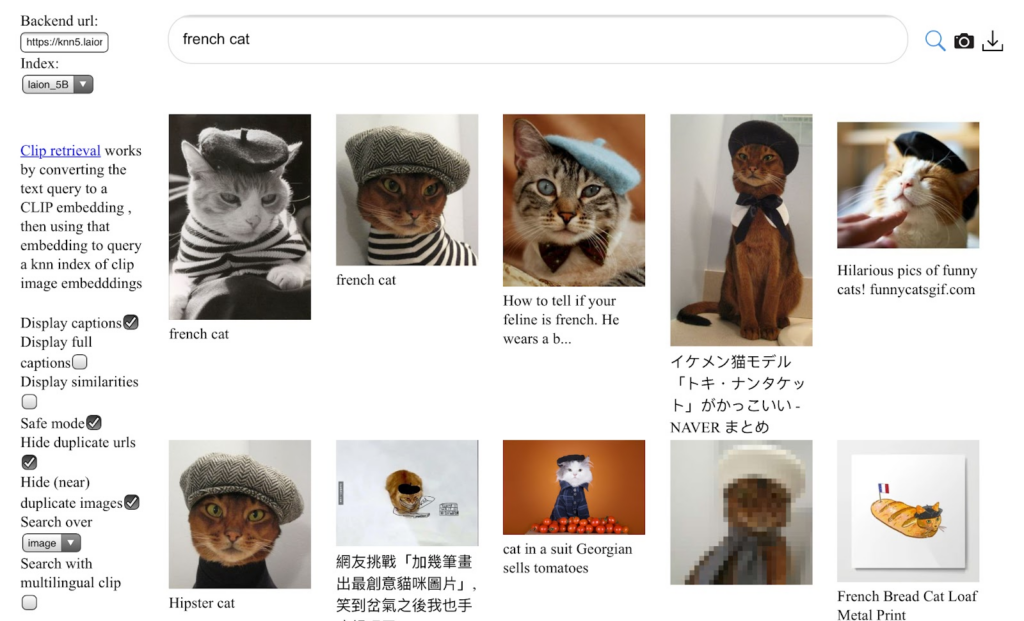
Practitioners would be delighted to find that LAION-5B is available for download here under the Creative Common license. Not only that, there is a web interface (Figure 10) for those who would like casual browsing of the dataset.
{kind=link}
Other Notable Mentions
There are also other noteworthy papers that we cannot cover extensively in one blog post. Instead, we will mention them in passing and leave the reader to read its details.
This method is a NeRF-based framework for synthesizing 3D faces. By introducing 3D face priors, the authors differentiated their approach from existing approaches with 3D controllability over synthetic face images.
Existing attacks on face recognition networks typically target low-level features like pixels. A unified framework for generating transferable attacks using high-level semantics, Adv-Attribute is a departure from that norm. Experiments on existing benchmarks like CalebA-HQ dataset showcases the ability of Adv-Attribute in generating transferable and inconspicuous adversarial faces.

Cutting-edge 3D generative models often use multilayer perceptrons (MLPs) to parametrize 3D radiance fields. The approach is slow and often causes the rendered viewpoint and content to no longer be independent. The authors thus propose the use of voxel grids, which are 3D grids of values organized into layers of rows and columns, for fast 3D generative modeling. The approach allows photorealistic images to be generated from any viewpoint.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
