
























Five Top Papers from NeurIPS 2021

The Conference on Neural Information Processing Systems, NeurIPS, is one of the most anticipated AI research conferences. Apart from neuroscience and machine learning, NeurIPS features a dazzling array of topics like cognitive science, psychology, information theory, and computer vision.

NeurIPS 2021 featured an exciting lineup of keynote speakers, paper presentations, and panel discussions. One of the main highlights of NeurIPS is the workshops, which deep dive into specific themes of machine learning. One such topic is data-centric AI.
The NeurIPS Data-Centric AI Workshop
Data-centric AI (DCAI) made its way into the ML vocabulary in recent years. It is a movement that shifts the focus of ML development from hyperparameter tuning to data quality improvement. Yet, creating high-quality datasets is a painstaking endeavor due to the lack of tools, best practices, and infrastructure for data management in modern ML systems.
Thus, the NeurIPS Data-Centric Workshop aimed to address such a gap by bringing together industry experts of the DCAI community. With its impressive lineup of speakers, the workshop showcased state-of-the-art solutions that enable data-centric AI. These solutions run the gamut from data generation, data labeling, data quality evaluation to data governance.
Here, we summarize five key takeaways from the DCAI workshop.
1. Generating Synthetic Documents in Natural Scene
In 1989, Yann LeCun and his team at AT&T penned the seminal paper Backpropagation Applied to Handwritten Zip Code Recognition. This demonstrated that computer vision models could read text from images. Since then, neural networks have evolved to perform more sophisticated text-processing tasks, like text layout detection and recognition.
Training these neural networks requires a large corpus of digitized documents. Today’s open-source datasets contain high-quality scans of digitized documents (Figure 1A) but are lacking in scans taken in natural scenes (Figure 1B).

Figure 1A: A high-quality scan of a form

Figure 1B: The same form taken in a natural scene [Source]
Watch On-Demand “Implementing Data-Centric AI Methodology” with Microsoft and Meta
Today, most scans are taken by non-professionals with mobile phones. Thus, models should be trained on such scans for them to perform well in the real world. Sim2Real Doc solves this problem with synthetic data. Specifically, it is a Python framework that synthesizes datasets and performs domain randomization of documents in natural scenes (Figure 2). It integrates with the open-source Blender project, a 3D modeling and rendering tool.

Figure 2: Synthetic documents generated by Sim2Real [Source]
Sim2Real systematically create synthetic documents with the following pipeline:
• Randomly sample base document images (like a PDF)
• Randomize the content of the documents
• Add noise to the document (e.g. fax, photocopies)
• Randomize the scene of the document, like the camera position and orientation, camera focus, and background.
• Render the image using the path-traced rendering process.
Sim2Real Docs has a diverse range of use cases. Most notably, the resulting synthetic data can be used to train models to classify documents, detect logos, and separate documents from their backgrounds, among others.
2. Detecting Label Errors in Autonomous Vehicle Dataset with Learned Observation Assertion
It is well-known that real-world datasets are replete with errors. Such errors rear their ugly heads in downstream processes, where trained models produce incorrect predictions that are potentially dangerous. Yet, it is often difficult to quantify how much error is present in a dataset.
Such errors ought to be caught or quantified in datasets used to train high-stake applications autonomous driving cars (Figure 3).

Figure 3: Example of labels missing in the Lyft Level 5 dataset (red bounding boxes)
Currently, existing error-detection systems implement Model Assertions (MA), which are black-box functions that provide severity scores. A high severity score is a telltale sign of whether an ML model or human label has an error.
Yet, MA does not leverage organizational resources like existing labeled datasets labels and trained ML models. The alternative to MA–hiring data auditors for error quantification–is prohibitively expensive.
To address this situation, researchers at Toyota and Stanford propose Fixy, which is a system that aims to find errors in human labels. It implements learned observation assertion, which leverages existing organizational resources to learn a probabilistic model for finding errors in labels.
Fixy is superior to existing solutions in finding errors as compared to existing models that use Model Assertions. Particularly, the researchers checked for errors using the Lyft Level 5 dataset. Fixy could rank potential errors with two times the precision of model assertion. It also uncovered errors that human auditors missed. (Figure 4)

Figure 4: Example of a motorcycle missed by a human auditor but caught by Fixy
This paper demonstrated how data annotated by the best tools is far from perfect. Fixy addresses the weakness of human-labeled datasets by detecting the label error. Such errors still have to be manually fixed, which requires additional resources. Synthetic data holds the potential to eliminate such errors in data labels.
3. Ontolabeling: Re-Thinking Data Labeling For Computer Vision
State-of-the-art computer vision models have a huge need for image and video data. This fueled the proliferation of ever-larger datasets like NuScenes (Figure 5), ArgoVerse (Figure 6), and Mapillary, just to name a few.

Figure 5: A labeled scene from NuScenes [Source]

Figure 6: A labeled scene from Agroverse [Source]
Today’s data labeling practices fail to define the semantics and taxonomies of the labels (Figure 7). Consequently, the definition of the same label cannot be mapped from one dataset to another. As a result, datasets today are static and heterogeneous.

Figure 7: Label today has a semantic tag (e.g. “car”), a labeling construct (a bounding box), a reference to the file name (Image_Car_1.jpg), and additional metadata. Over the long term, machine learning practitioners will find it challenging to use, compare, extend or repurpose existing datasets. Clearly, the data labeling process is ripe for a revamp.
Watch On-Demand “Implementing Data-Centric AI Methodology” with Microsoft and Meta
That is why authors from VicomTech and DeepenAI proposed Ontolabeling. This new methodology separates data labels into two data model layers – structure and semantics (Figure 8). The structure layer consists of spatio-temporal labels for sensor data (like camera data), while the semantics layer uses ontologies to structure, organize, maintain, extend, and repurpose the semantics of the annotation.
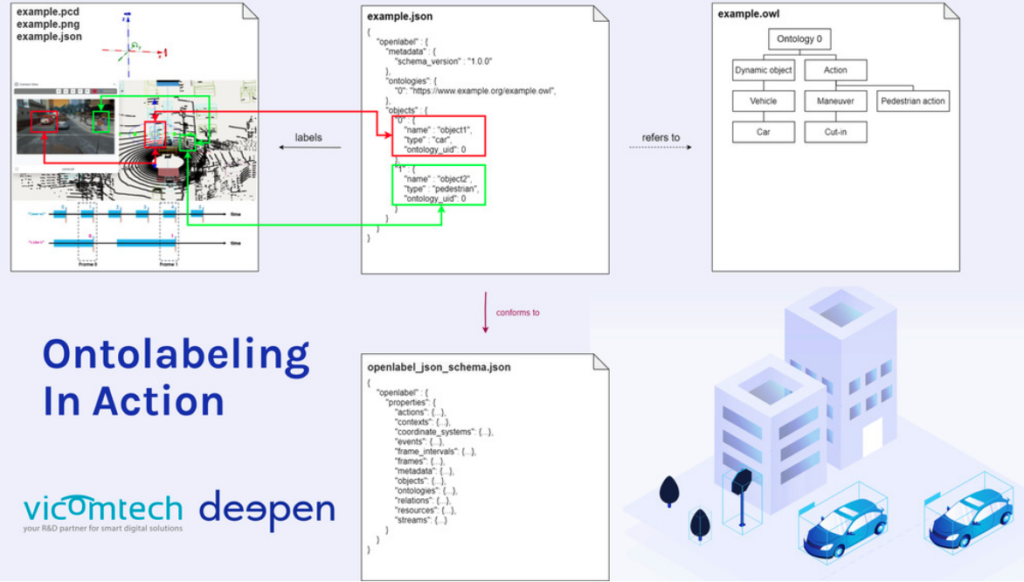
Figure 8: example.png labeled with Ontolabeling principle [Source]
For example, in the labeling of the file “example.png” (Figure 8), the files “example.pcd”, “example.png” and “example.json” represent the structure layer that contains the sensor data. On the other hand, the file “example.owl” consists of the semantic layer that describes the car as a dynamic object and its action as cutting into a lane.
Ontolabeling principles have garnered momentum as more open-source toolkits like OpenLABEL begin adopting it.
4. Towards a Shared Rubric for Dataset Annotation
Recent years saw the rise of third-party data annotation services to fulfill the demand for labeled datasets. Yet, in the absence of a rubric to compare annotation services, companies have a hard time evaluating vendors holistically. Instead, they turn to price as the ultimate yardstick. Alas, the resulting race-to-the-bottom leads to a lose-lose situation where companies are offered sub-optimal services while high-quality vendors are forced to cut corners.
As such, Adobe presented a shared rubric that evaluates dataset annotation services on fifteen areas (Table 1). This rubric serves as a scorecard for a fair comparison across vendors. It is also an excellent tool for clients to communicate their expectations to the data annotation vendors.
Table 1: The 15 areas of the proposed data annotation rubric
| Area | Brief description |
| Annotation Guide: Versioning | The annotations follow best practices in versioning (like semantic versioning) |
| Annotation Guide: Language | The presence of manual translation of clients’ instructions to annotators’ native language |
| Annotation Guide: Questions | The ease for annotators to ask the client clarifying questions. |
| Annotation Guide: Testing and refinement | The presence of processes to test and refine the annotation instructions. |
| Ethical treatment of annotators: Payment | The compensation of annotators |
| Ethical treatment of annotators: Work conditions | The working condition of annotators. |
| Assessing annotation quality | The presence of processes that frequently assess and improve annotation quality. |
| Assessing annotator reliability | The presence of tests for identifying outlier annotators |
| Merging of individual annotations | The use of merging strategies that account for individual annotators’ previous accuracy |
| Data Delivery | The provision of detailed metadata |
| Acquiring Data: Ethics | The ethics of practices surrounding privacy and copyright |
| Acquiring Data: Bias and Domain Shift | The use of techniques that monitor distribution for societal bias and domain mismatch |
| Prioritizing Items | The ease and ability for the client to prioritize items |
| Starting with Seeded Data | The use of seed data to measure the impact of anchoring bias. |
5. Using Synthetic Images To Uncover Population Biases In Facial Landmarks Detection
The performance of a machine learning model needs to be evaluated with a test set before it is pushed into production. As such, the test set should ideally be large enough to detect statistically significant biases by including all sub-groups in the target population.
Yet, most real-world datasets today do not satisfy this criterion. Detractors might point to balanced, richly annotated datasets like KANFace (Figure 9) as a counter-example. Unfortunately, such datasets are far and few between.

Figure 9. KANFace is annotated for identity, exact age, gender, and kinship [Source] Thus, our Datagen team presented the use of synthetic images in uncovering population biases in facial landmarks detection. In this paper, we found that the performance of a facial landmark detection model differs significantly between two populations of a synthetic dataset (e.g. men vs women).
We also observed similar results when testing the landmark detection model on its biases against certain attributes, like old age, facial hair, and dark skin. This leads us to conclude that synthetic images generated with Datagen’s platform (Figure 10) could be used to uncover population biases for landmark detection tasks.
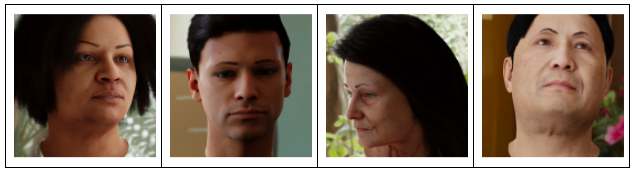
Figure 10
Synthetic Data drives Data-Centric AI
Clearly, generating high-quality data is not trivial at all. From the Data-Centric AI workshop, we observe how nascent solutions in the areas of data generation and labeling are pushing the boundary of data quality.
Watch On-Demand “Implementing Data-Centric AI Methodology” with Microsoft and Meta
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
