
























Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion

A 3D avatar is a digital representation of a person or character in a 3D environment. A 3D avatar is essentially a type of 3D model, as it is a digital representation of a 3D object (a person or character). 3D avatars can be used in a variety of applications, including video games, virtual reality, social media, videoconferencing, online education (to construct more engaging and interactive learning experience), healthcare (to build virtual patient simulations for training purposes/for remote consultations with doctors).
Generating high-quality 3D avatars can be very resource-intensive, both in terms of memory and processing power. This is because 3D models are typically much more complex than 2D images, and they require a greater amount of data to represent all of the details and features of the avatar.
Main Idea
In the paper, a ML model, dubbed Rodin, is trained to generate a 3D avatar of an individual from his/her frontal-view image. Rodin allows users to customize avatars by either capturing given image attributes or using a text prompt to edit them.

Figure 1: Rodin can produce high-fidelity 3D avatars(1st row). It also supports 3D avatar generation from a single portrait and allows for text-based semantic editing (2nd row).
In the authors’ study, a model is trained to generate 3D avatars represented by neural radiance fields(NeRF). NeRF is an implicit 3D model (of a scene or an object) representation, modeled by a neural network(NN), which defines its shape and objects. In other words, NN is trained to produce color and density of the scene/object from a spatial coordinate and a viewing direction. The classical approach for NeRF construction, introduced by Ben Mildenhall in his seminal paper, builds an instance-specific implicit 3D model representation from several views of a scene. With NeRF, a NN has to be trained in order to build a multi-view representation of every scene. Compared to this approach, the authors trained a single model of synthesizing a neural volumetric representation of an avatar from a given image and doesn’t require any additional training.
In order to accomplish this task, the paper leverages the power of diffusion denoising probability models (DDPM or diffusion models). DDPM is a class of generative models capable of synthesizing diverse data types such as images, audios, and videos. DDPMs generate data with a NN, which is trained to gradually denoise data starting from pure noise. First small amounts of noise are gradually added to the data until it is totally destroyed. Then a NN is trained to reverse this process by reconstructing the noise added to data in each iteration. Finally the denoising model is iteratively applied to noise samples to synthesize new data pieces.
Proposed Model: A General View
Construction of a 3D avatar model is composed of the following stages:
- Low resolution(64×64) tri-plane volumetric representation (will be explained in the next section) is built from an image latent vector (this vector is sampled from the latent space for unconditional avatar model synthesis)
- Tri-plane representation is upsampled to 256×256 resolution.
- This representation is fed to a shallow fully-connected network (MLP) to obtain view-dependent color c ∈ R3 and its density σ > 0 for every spatial coordinate (x, y, z) and the viewing direction d ∈ S2 of the 3D avatar model.
- This multi-view representation is fed to a volumetric renderer to build a 3D avatar model.
- A convolutional NN (convolutional refiner) enhances the quality (adding delicate high-resolution details) of the avatar model while upscaling it to 1024×1024 resolution.
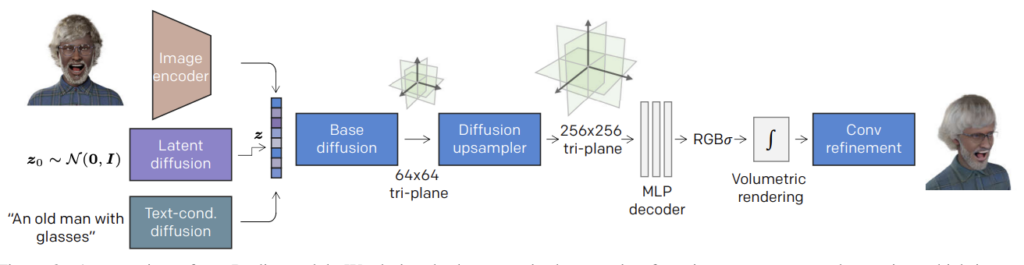
Figure 2: Rodin Overview
Rodin Training: Tri-plane Representation Learning with DDPM
Rodin fits DDPM to construct a NeRF representation of an avatar. The authors leverage a tri-plane representation of a 3D avatar model. Tri-plane representation(TPR) combines the advantages of both implicit(e.g. NeRF) and explicit(voxel-based) representations. TPR is a way of representing a 3D object or environment by dividing it into a set of axis-aligned planes, arranged in a regular grid. Essentially, the tri-plane features represent the projection of neural volume to the frontal, bottom, and side views. More specifically, TPR stores in memory 3 planes with a resolution of ![]() , where C denotes the number of channels. A spatial location (point) is projected to these planes, their corresponding representations(C-dimensional) are summed and fed into a shallow NN(MLP decoder) together with the view direction d to reconstruct the color c(p, d) and density σ(p):
, where C denotes the number of channels. A spatial location (point) is projected to these planes, their corresponding representations(C-dimensional) are summed and fed into a shallow NN(MLP decoder) together with the view direction d to reconstruct the color c(p, d) and density σ(p):

Here ξ(yp) is the Fourier embedding of the tri-plane features. Using neural tangent kernel (NTK) apparatus Ben Mildenhall et al showed that a vanilla MLP is not capable of modeling high frequencies present in a 3D model. Applying Fourier transform on low-dimensional input (3D coordinates) enables an MLP to learn high-frequency characteristics of a 3D model (density, shape, color).
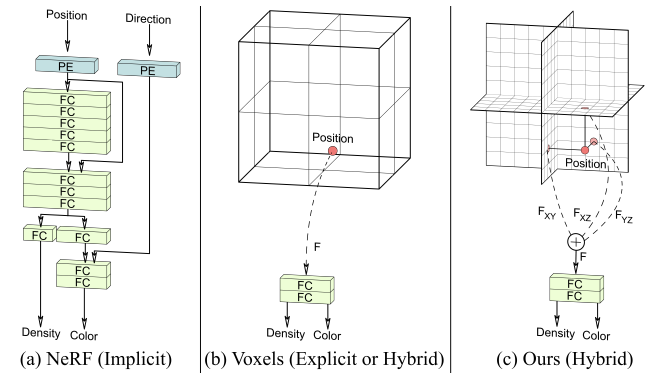
Figure 3: Explicit, implicit and tri-plane volumetric representations
Rodin Architecture: 3D-Aware Convolution
Next we elaborate on a novel architecture, dubbed 3D-aware convolution, behind the diffusion model synthesizing a low-resolution tri-plane representation of an avatar. Diffusion models powering most notable generative models, such as DALL-E2 or Imagen, use different variants of 2D UNet architecture (usually accompanied with the attention mechanism) to model a data denoising process (= noise prediction).
It turns out that the standard 2D UNet is not well suited for processing of TPR features, since they come from orthogonal planes. The lack of spatial alignment between features from the orthogonal planes makes channel-wise concatenation of them problematic for CNN processing. To battle this issue, the authors proposed 3D-aware convolution, which relies on the observation that tri-plane features corresponding to the same part of the 3D object, should be processed together. 3D-aware convolution is an elegant way to aggregate tri-plane features of the same 3D object piece in such a way that they can be simultaneously treated by 2D convolution.
Rodin Architecture: Latent Conditioned Diffusion Models
In order to produce a 3D avatar model with specific visual attributes of a given individual, Rodin trains an image encoder to build a semantically-anchored latent representation of an input image. This latent vector is fed into the low-resolution diffusion model and is injected into the ResNet layers of 3D-Aware ConvNet. Note that a similar approach is used in a variety of generative diffusion models creating data of different types from text or images (DALL-E2, Imagen, Make-A-Video etc). Lastly, Rodin is capable of creating an unconditional 3D avatar model from gaussian noise fed to an additional (latent) diffusion model (more on this later).
Then the diffusion model is trained to produce tri-plane representation of the individual from this latent vector. Afterwise low-resolution(64×64) tri-plane representation is fed to the upsampler, which builds a 256×256 tri-plane representation of an avatar. The upsampler is powered by a diffusion model, but in contrast with the low-resolution model, it is trained to predict the data of the previous iteration and not the noise (Dall-E2 does the same).
Rodin also leverages the classifier-free guidance(CFG) technique which is widely used in generative diffusion models to improve sampling quality. CFG mixes the added noise predictions of a conditional (e.g. with a label or textual description) diffusion model with an unconditional diffusion model, while the models are trained together (no tagged data required). Unconditional diffusion models are usually trained by randomly replacing the conditional latent vector by zeroes during training a conditional diffusion model. Rodin trains an unconditional diffusion model in a bit different way: it trains DDPM to produce its latent vectors and then leverages it during data generation with CFG.

Figure 4: Unconditionally generated samples by our Rodin model
Finally to allow for customizing a 3D avatar for a given subject (represented by a frontal-view image) and a text prompt, Rodin computes the editing direction vector as a difference between CLIP embeddings of the text prompt. Then this difference is added to the image encoder output to construct the latent vector z, which is fed to the model.
Training Rodin
The training set of Rodin is composed of multi-view renderings (from different spatial locations p and view directions d) for 100K synthetic faces, generated with Blender software tool. These faces were generated for a variety of hair, clothing, expressions and other face features.
Rodin’s loss function enforces similarity between the rendered (by the volumetric renderer) images x = R(c(p, d), σ(p)) f and the ground truth image x(p, d) via L2 loss. Recall that c is a color and σ is a color density from (p, d). The authors also use perceptual loss between rendered and ground truth image to make avatars look more “realistic”. Lastly sparse, smooth, and compact regularizers are applied to improve the avatar quality
Results
As compared to several SOTA approaches, Rodin avatars are of better quality (Fig.5). Rodin also outperformed its competitors in terms of Freche Inception Distance (FID), which measures the quality of generated images (see Fig.6). Note that FID was computed with the features of the CLIP model.
Moreover, unconditionally generated avatars synthesized by Rodin display an impressive quality (see Fig. 4).


Figure 5: Rodin quantitative performance analysis
Rodin’s 3D avatars of an individual possess a high degree of visual resemblance(see Fig.6) to an individual’s actual portrait. Finally text-guided avatars look coherent with the text prompt they were edited with.

Figure 6: Avatars for a given individual
Conclusion
This paper describes a method for using diffusion models for synthesizing 3D avatar models represented as NeRF. By using the model to generate custom avatars based on input text or images, developers can create user-friendly interfaces that allow users to easily create personalized avatars. Rodin approach is superior to other SOTA methods in terms of creating sharp highly-detailed avatars with little to no visible artifacts.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
