
























Experimenting with Real and Synthetic Data for Hands-on-Wheel Detection

This is the last part of our series outlining our benchmark on leveraging synthetic data for hands-on-wheel detection. You can read parts 1 and 2 here and here.
We conducted two types of experiments to demonstrate the added value of easily reachable synthetic data.
- We compare a model trained solely on the DMD real data with multiple models trained on synthetic data and fine-tuned with varying amounts of real data mixed with synthetic data. We assumed tagging a small amount of real data is feasible in most cases and preferable over tagging hundreds of hours.
- We show that one can boost performance by applying data-centric iterations–searching the test errors for edge cases that are missing from the dataset and adding them.
We evaluate our performance with AUC scores for each of the hands.
Training & Fine Tuning
We refer to a model trained on DMD as our reference, and compare it to a model trained mainly on synthetic data and boosted with a very limited amount of real data. We considered two methods for using the synthetic data.
- Train on the synthetic data alone and
- Train on the synthetic dataset followed by fine-tuning with a mix of real and synthetic data. We train all models using Adam optimizer [1] with ß1 = 0:9, ß2 = 0:9999, batch size of 128, weight decay of 0.1, and initial learning rate of 0.0001.
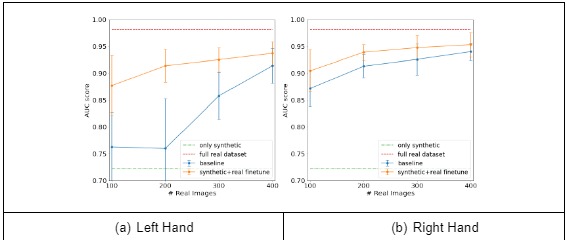
We would expect that due to the difference in dataset sizes, as well as because of the domain gap, that a model trained on a full real dataset will outperform the one trained only on synthetic data. This is exactly what we see in Table 2, the real dataset performs significantly better than the model trained on the synthetic dataset. We also sub-sampled the DMD dataset to create four small datasets with only 100, 200, 300, and 400 frames in them, respectively. We created the datasets by choosing five drivers and sample 5, 10, 15, and 20 frames from each of the four videos that each driver appears in. We trained the model on synthetic data and then fine-tuned it for 2,500 batches using a mix of synthetic data and real data from the small datasets. When fine-tuning, we made sure that each batch contains an even mix of synthetic data and real data. Without this technique, the network forgets its initial training on the synthetic data. We demonstrated the effectiveness of synthetic data by comparing to models trained solely on each of these small real datasets. We ran the experiment 11 times on different sub-sampling splits of the data and showed the AUC mean and standard deviation on the real test set for each small dataset in Figure 3. The large error intervals are caused by the sensitivity to the small amount of data in each split.
Since the right hand is clearly visible in most frames, the network receives enough variations to successfully learn even with a small amount of real data. Therefore, the synthetic data does not improve the model as much over the real data. However, for the left hand, which is often occluded by the right hand, the lack of variations is noticeable, and the synthetic data provides a clear improvement. This is especially true when there are fewer than 200 images in the real training set and the results improve from 0.76 AUC to 0.91. In this case, the network trained on real-data-only did not have the opportunity to see all the different edge cases that are only present in the synthetic data.
Generate synthetic data with our new free trial. Start now!
| Experiment | # Train Images | Left AUC | Right AUC |
| Real Only | 531K | 0.9813 | 0.9941 |
|---|---|---|---|
| Synth Only | 8,800 | 0.7226 | 0.7581 |
| Synth+100 Real | 8,900 | 0.8769 | 0.9045 |
| Synth+200 Real | 9,000 | 0.9139 | 0.9389 |
| Synth+300 Real | 9,100 | 0.9251 | 0.9475 |
| Synth+400 Real | 9,200 | 0.9369 | 0.9530 |
Table 1. AUC scores for models trained on synthetic dataset, real dataset, and tested on the real dataset
{kind=link}
Figure 1. AUC comparison between baseline results (blue) and synthetic fine-tune results (orange) for the left hand (3a) and right
Data-Centric Iteration
In addition to iterating on the model, we also iterated on the dataset. We used our base model, which was trained only on synthetic data (results in the second row of Table 2), and we visually analyzed the errors in the DMD validation split.
The majority of misclassifications can be divided into several specific categories:
- Occlusion – Hands overlap in the image, so the network has a hard time telling whether the left hand is on or off the wheel (See Figure 4a)
- Both Off – This is an uncommon case, so the network has a harder time classifying this case correctly (See Figure 4b)
- Opposite Side – The right hand is on the left side of the wheel or vice versa. The network will classify the left hand as ”on” and the right hand as ”off” (See Figure 4c)
- Blur – The video is blurry when the hand is in motion and so it’s unclear if the hand is on the wheel or not (See Figure 4d)

{kind=link}
Figure 2. Some examples of common types of errors. (2a) (2b) Left hand classified as on (2c) Left hand classified as on, Right hand classified as off (2d) Right hand classified as on
Based on our failure analysis we generated sequences with both hands off the wheel (total of 450 images).

{kind=link}
Figure 3. Some new frames with both hands off that were added to the synthetic dataset after the data-centric iteration.
Examples for the generated frames are shown in Figure 3. After retraining, performance on this specific scenario increased, with the recall and precision jumping from 0.77 and 0.98 to 0.85 and 0.99, respectively.
Conclusion
In this paper, we simulated a situation in which only a small amount of real data is available and demonstrated how synthetic data can compensate for the missing real data. We show that mixing real and synthetic data outperforms training on a small amount of real data alone. Introducing small amounts of real data to a synthetic-first model boosts performance by compensating the domain gap, reaching almost the same results as training on a large amount of real data. Furthermore, we followed the data-centric approach applying a single data improvement iteration, leveraging our configurable platform that successfully improved our model emphasizing the great potential of incorporating synthetic data in real-life models.
Further research is required to improve results when training solely with synthetic data. We believe that adopting more iterations of the data- centric approach will improve results. This involves iterations of failure analysis and updating the training dataset appropriately. Supplementing our model with additional information, such as depth maps or sequential frame information could also improve results.
Generate synthetic data with our new free trial. Start now!
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
