
























Edge Cases in Autonomous Vehicle Production

“Because [the autonomous vehicle] is a product in the hands of customers, you are forced to go through the long tail. You cannot do just 95% and call it a day. The long tail brings all kinds of interesting challenges,” says Andrej Kaparthy, the director of artificial intelligence and Autopilot Vision at Tesla, at the 2020 CVPR Keynote.
Here, “long tail” refers to edge cases in autonomous vehicles (AV). Edge cases are probable scenarios that have a low probability of occurrence. These rare occurrences are easily missed and thus are often missing in datasets. While humans are naturally proficient at dealing with edge cases, the same cannot be said of AI. Thus, they have to be dealt with carefully.

Figure 1: A real image of a truck with a reflective surface (Source)

Figure 2: A real image of a chair flying across the road (Source)
The cost of ignoring edge cases is high. In 2018, a Google autonomous vehicle crashed into an oncoming bus when it detected sandbags surrounding a storm drain and had difficulty interpreting the situation correctly. In 2020, Toyota’s autonomous e-Palette collided with a visually impaired pedestrian. “It shows that autonomous vehicles are not yet realistic for normal roads,” Toyota CEO Akio Toyoda commented after the accident.
The pressure to deal with edge cases is mounting for car manufacturers. AVs which can better handle edge cases are safer and have a better prospect of becoming fully driverless quicker.
Watch On-Demand “Using Synthetic Data to Address Real-World Applications: From the Metaverse to Medical and Automotive”
Dealing with edge cases is not a trivial task. This blog post analyzes how synthetic data can handle edge cases in production. We will focus our attention on the development of autonomous vehicles, which remains a challenging feat due to the sheer number of possible edge cases.
Edge Cases Come in Multiple Forms
Kai Wang, the Director of Prediction at Zoox, shared that edge cases come in perceptual and behavioral forms. Perceptual edge cases involve rare sightings like trucks with protrusions. Behavioral edge cases are events that require more careful maneuvering of the vehicle, like making a tight three-point turn, navigating through a dense crowd, or dealing with jaywalking pedestrians.
In the CVPR talk, Andrej Kaparthy illustrated examples of perceptual edge cases that Tesla observed when training their vehicle to stop. Some examples (Figure 3) of these include:
- Conditional stop signs (e.g. “stop except right turn”)
- Moving stop signs (e.g. on a school bus)
- Temporary stop signs (e.g. held by a person)
- Occluded stop signs (e.g. hidden by a vehicle)
 |
 |
 |
|

Figure 3. A variety of stop signs that constitute edge cases (Source)
Challenges of Edge Cases in Production
Models in production are fallible – and can perform poorly when faced with edge cases. That is why Tesla has a “Data Engine” that empowers its development of autonomous vehicles (Figure 4).
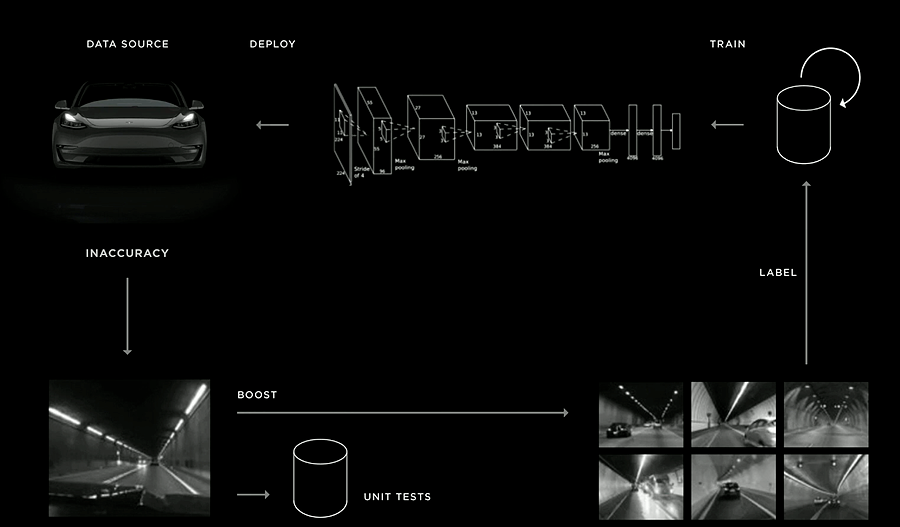
The principle of the data engine is easy to understand. First, inaccuracies in existing models are detected. Tesla then adds such cases to its unit tests. It also collects more data of similar cases to retrain the model. Such an iterative approach allows it to catch as many edge cases as possible.
Conceivably, the act of collecting and labeling edge cases can be exorbitantly expensive, and in some cases dangerous and impossible. Here’s an example of a dangerous edge case to replicate (Figures 5A and 5B)

Figure 5A. A man emerging from a manhole remains undetected by the vehicle |
Figure 5B. A man emerging from a manhole is incorrectly classified. (Source: DRisk and BBC) |

Testing model in production on edge cases using synthetic data
This is where synthetic data can help address the problem. As early as 2018, Bewley et. al. demonstrated that their autonomous vehicle trained only on simulation data drive in public urban roads in the UK (Figure 6). Since then, more researchers have explored the use of synthetic data for training autonomous vehicles.

Figure 6. Comparison of simulated training and actual test environments in “Learning to Drive from Simulation without Real World Labels” (by Bewley et. al.)
More recently, NVIDIA recently proposed a strategic approach named “imitation training” (Figure 7). In this approach, the failure cases of existing systems in the real world are replicated in a simulated environment. They are then used as training data for the autonomous vehicle. This cycle is repeated until the model’s performance converges.
Watch On-Demand “Using Synthetic Data to Address Real-World Applications: From the Metaverse to Medical and Automotive”
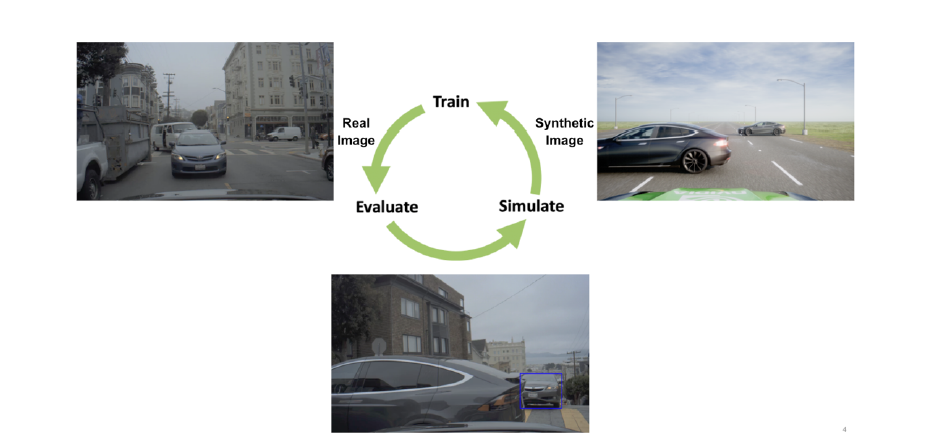
Figure 7. The imitation training approach involves the “train, evaluate and simulate” cycle (Source)
Consider the following edge case involving a partially visible truck (Figure 8). The original model produced an incorrect bounding box (left, yellow rectangle). After training on synthetic imitation data (Figure 9), the improved model could produce the correct bounding boxes on this edge case (Figure 8, right)

Figure 8: The baseline model prediction of the truck (left, yellow) compared against the improved model trained with synthetic data (right, blue). The ground truth is in gray.

Figure 9: Examples of synthetically generated images imitating the false truck detection in Figure 8
In general, the models trained using the synthetic imitation data strategy are found to have superior performance as compared to those trained on real data only.
Testing model in production on edge cases using synthetic data
Apart from training models in production, one can also create synthetic data to test existing models on edge cases.
As AI matures, more data teams find value in developing test cases for their AI models. Much like software engineering has test-driven development (TDD) as part of its best practices, AI practitioners are likely to develop unit tests for their AI models, argued Yaron Singer from Robust Intelligence. To extend that principle, Yaron also suggested the use of fuzzing for AI, where random inputs are fed to the model in hopes of uncovering its vulnerabilities. Having a robust testing protocol reduces the possibility of AI accidents or AI systems breaking unexpectedly.
Testing model performance
To thoroughly evaluate the robustness of an AI system, the unit tests must include both the general and edge cases. Yet, certain edge cases might not be available from existing real-world datasets. To that end, AI practitioners can use synthetic test data.
One example is the ParallelEye-CS, a synthetic dataset for testing the visual intelligence of autonomous vehicles. The benefit of creating synthetic data over using real-world data is the high degree of control over the scene of each image. Figures 10 and 11 below illustrate how the authors tweaked the scenes and environments to include different edge cases in the data set.

Figure 10: The same scene but in different environments. (top left: rainy; top right: dark; bottom left: sunny; bottom right: flood)

Figure 11. Scenes with varying levels of occlusions. (top left: with railing; top right: with divider; bottom left: with a hidden bus; bottom right: with all occlusions)
Testing model for fairness in edge cases
Apart from optimizing model performance, AI practitioners must also ensure that the AI models in production are fair, even in edge cases. Such a sentiment is echoed by Martin Fowler, who called for AI practitioners to validate their models in production for potential biases.
For instance, the model should not perform poorly on minority classes (like the facial recognition software which misidentifies black faces). Neither should a model discriminate against minority groups (like how Amazon’s AI recruiting tool penalized female candidates).
Companies can no longer afford to turn a blind eye to AI fairness as regulations like GDPR start imposing fairness requirements on decisions made by machine learning models. Yet, there are limited toolkits and publicly available datasets for AI practitioners to evaluate their AI on fairness.
Synthetic data can help. Datagen recently published our findings on the use of synthetic images in uncovering population biases in facial landmark detections (Figure 12). In particular, we discovered that the performance of a facial landmark detection model differs significantly between two populations of a synthetic dataset (e.g. men vs women). This is a telltale sign that the model in production is biased against a certain group.
We can extend this concept to AVs. For example, we can test the model on pedestrians of different races and ages to uncover its population biases.
Synthetic data for edge cases
Synthetic data is here to stay as a viable solution to edge cases in production AV models. It supplements real-world datasets with edge cases, ensuring that AVs remain robust even under freak events. It is also more scalable, less prone to errors, and cheaper than real-world data.
With the rise of the data-centric AI movement, AI practitioners are starting to improve on the value of the data. At Datagen, we believe that the use of synthetic data in solving edge cases will not be restricted to autonomous vehicles. It can be extended to facial recognition, medical imaging, advanced manufacturing, and many other industries.

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
