
























Using Synthetic Images To Uncover Biases

In January 2020, Robert Williams was arrested for shoplifting after examining the security footage. The investigators followed the lead of a facial recognition system that flagged Williams’ photo as a match against the grainy footage (Figure 1). The problem? Williams was nowhere near the crime scene when the incident happened.

Figure 1. A photo of the alleged shoplifting suspect from the security footage and the driver’s license photo of Robert Williams
Williams’ wrongful arrest raised awareness of the fallibility of facial recognition, particularly in underrepresented minorities. The source of the problem is the biased and unbalanced dataset used to train many existing facial recognition AI today.
Image datasets are problematic
Unfortunately, even the most established datasets today proliferate existing social biases. Pundits initially lauded the now-defunct Tiny Images Dataset as a comprehensive library of items, only to be disappointed later by revelations that it is rife with racist, misogynistic, and demeaning labels. Machines trained on such biased datasets perpetuate the biases in their outputs against vulnerable and marginalized individuals and communities.
Even if datasets do not contain harmful labels, they are likely to under-represent minority groups. Unsurprisingly, models trained on unbalanced datasets perform poorer on the minority class in an effect dubbed bias amplification. In particular, Buolanmwini et al. found that commercial gender classification systems performed much poorer on dark-skinned females than light-skinned males. Another study found that face recognition and age estimation models were biased towards faces under 18 and over 60 years old.
We cannot understate the harmful effects of such underrepresentation. A passport robot that tells Asian applicants to open their eyes is a PR nightmare (Figure 3). An autonomous vehicle that cannot recognize dark-skinned individuals can cause a life-threatening tragedy.
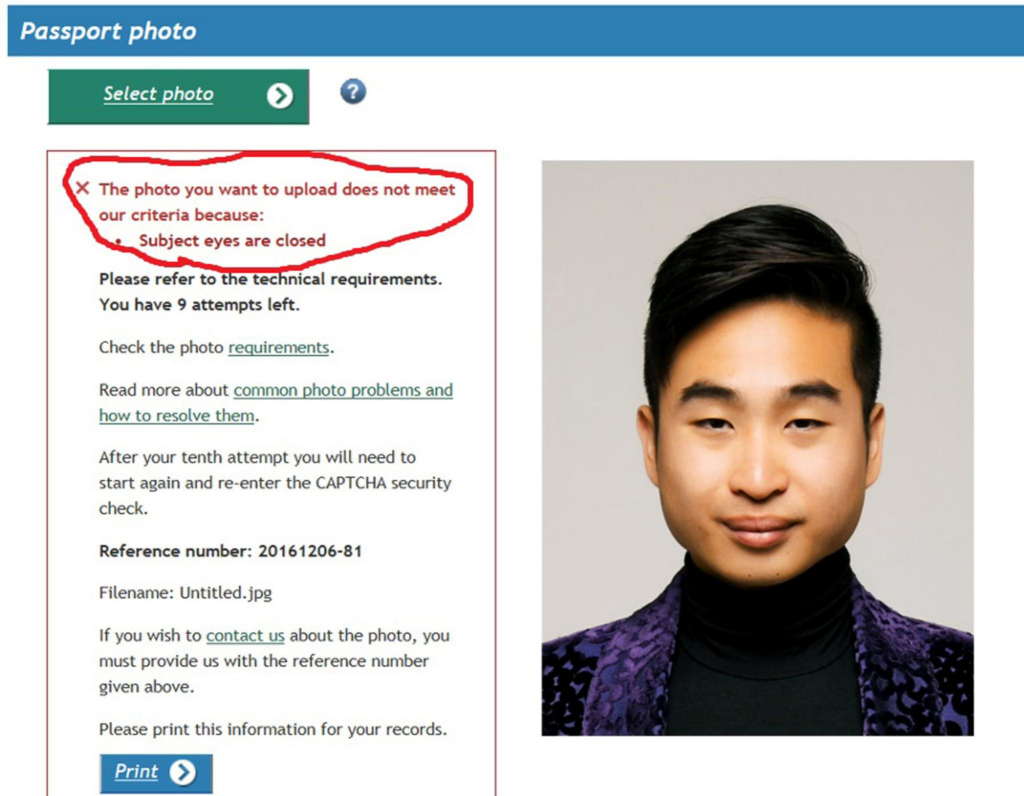
Figure 3. A screenshot of an erroneous passport photo rejection notice (Source)
Unfortunately, many real-world applications inherit biases encoded in training images. Computer vision practitioners ought to catch such biases before they cause harm. Yet, the question remains–how do we detect biased computer vision systems?
Detecting biased computer vision systems
One existing solution is to use balanced, richly annotated real-world datasets to detect the difference in performances across different groups. For example, KANFace features diverse ages, genders, and skin colors capable of uncovering biases for various face analysis tasks (Figure 4).

Figure 4. KANFace is annotated for identity, exact age, gender, and kinship (Source)
Another solution is to use synthetic data for detecting biases against minority classes. This idea is not new. Tesla demonstrated its simulated environments (Figure 5) used to test their autonomous vehicles in edge cases.

Figure 5. An example of a rare scene simulated by Tesla (Source)
Download our eBook “Solving Privacy Concerns with Synthetic Data”
Detecting biases in facial landmark detection
The same idea can be applied to uncover biases in models trained for facial analysis tasks, as we demonstrated in our paper Using Synthetic Images to Uncover Population Biases in Facial Landmarks Detection.
To validate this hypothesis, we found that the performance of a facial landmark detection model differs significantly between two populations of a synthetic dataset (e.g. men vs women). This leads us to conclude that synthetic images could be used to uncover population biases for landmark detection tasks.
Similar results are found when evaluating the same model on real datasets. This signifies that both synthetic images and real images are capable of testing the bias of a landmark detection model.
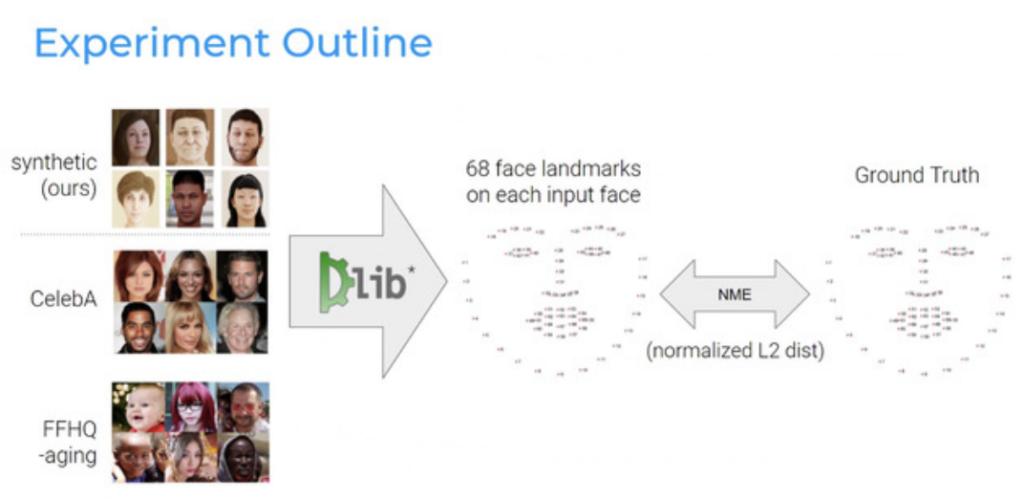
Figure 6: Steps for the experiment
Here are the steps to validate this hypothesis (Figure 6)
- Use the DLIB package to detect facial landmarks on two datasets–CelebA (Figure 7) and FFHQ-Aging (Figure 8). These datasets are used because they come with facial landmarks annotations and labels of appearance attributes (like gender, age, and skin color)
- Compute the normalized mean error (NME) between the model output and the ground truth. The NME reflects the deviance between the detected position and the ground truth.
- Stratify the errors based on the attributes to identify any biases in the model. For example, the model is biased against women if the NME for men is lower than women on average.
- Repeat steps 1 to 3 using a synthetic dataset created by Datagen (Figure 9).
- Compare the biases identified using the synthetic dataset against those identified using real datasets.

Figure 7. Sample images from CelebA dataset

Figure 8. Annotated examples from FFHQ Dataset
Figure 9. Example of face images from the Datagen synthetic dataset
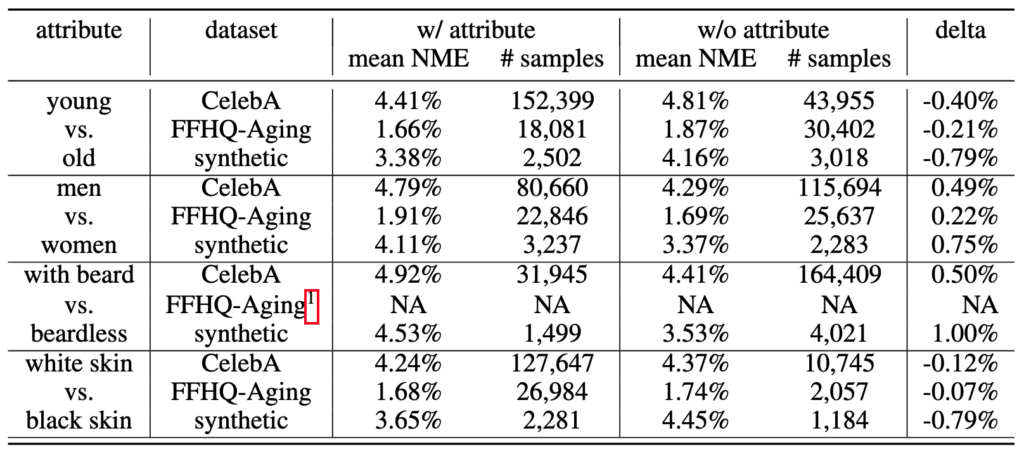
Table 1 shows the results of the experiment.
Table 1
1 FFHQ-Aging does not have the “beard” attribute annotation
In summary, the model’s bias is apparent when tested on both real and synthetic datasets. For example, when tested on CelebA datasets, the model’s mean NME on young faces is 0.40% lower than that on old faces. When tested on FFHQ-Aging and Datagen’s synthetic dataset, the model’s NME on young faces is similarly lower than those on older faces. Simply put, the model is shown to be biased against older individuals when tested on both real and synthetic datasets.
We observe the same results when testing the model on other attributes. The model favors men (vs. women), those without a beard (vs. those with a beard), and white-skinned (vs. black-skinned) individuals.
Using synthetic images to uncover population biases
This set of results gave us confidence that the synthetic face images generated can uncover weaknesses in a facial landmark detection model.
This is good news for computer vision practitioners who want to detect biases in their models. It is often challenging to set aside sufficient images in the test set to detect biases against certain groups. This is no longer a problem if developers have access to synthetic data.
Synthetic images for fair AI
Computer vision AI cannot be expected to make fair decisions when they are trained on datasets rife with existing social biases against underrepresented groups. AI practitioners have the onus to detect biased models and create fair AI models. Synthetic images will become a cornerstone in that process.
That is why we plan to test for biases against additional attributes in other trained models. Our future research aims to rectify such biases by adding synthetic data in the training process.
If you are interested in using synthetic data to detect potential biases in your systems, talk to us today.

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
