
























Review of Synthetic Data Generation using Imitation Training Paper
Aman Kishore, et al. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, October 2021
A Review of Synthetic Data Generation using Imitation Training Paper
Problem Statement: One of the central challenges of supervised learning methods is training models that are robust enough to handle examples not adequately represented in the training dataset. Achieving good performance on the rare edge cases comprising the long tail of data distribution can often be difficult and expensive.
The paper proposes a novel technique for synthetic data generation, based on the imitation learning method, called DaGGER (Dataset Aggregation), initially proposed for reinforcement learning applications. The proposed scheme leverages the imitation training paradigm to create synthetic pieces of data to compensate for deficiencies of the original training dataset distribution. The strategy chosen by the authors relies on the observation that many of the model failure cases were due to hard examples, such as heavy occlusion, truncation, etc.
The authors propose to train a model (or a system) on the original data, mixed with previously generated synthetic data, with the aim of identifying instances in which the model performs poorly (e.g. false positives and false negatives when detecting objects in images). After that, synthetic data is created using a domain randomization method to enrich data distribution in the neighborhood of the weakly-performing examples.

This way, data generated with the proposed scheme balances the data distribution in the underrepresented and challenging areas for the model and improves the model performance. The proposed approach can be viewed as a hard example mining strategy that makes use of synthetic imagery for generation of difficult (for the model) examples.
A major focus of this paper is training Deep Neural Networks (DNNs) for autonomous driving on object detection tasks. Nevertheless, the proposed approach can be easily employed in a wide range of other domains such as medical imaging, speech recognition, or with any machine learning model type.
Researchers showed that the incorporation of synthetic data, generated with the proposed scheme, with DNN training led to a substantial mAP (mean average precision) performance improvement for several datasets.
Short Scheme Description
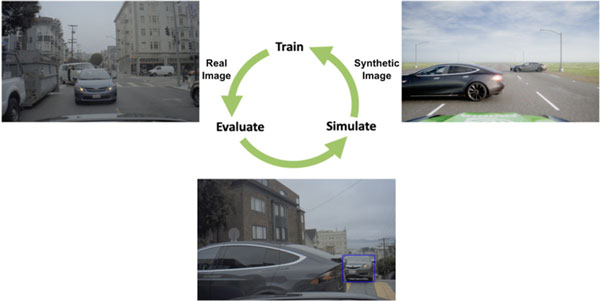
This method proceeds iteratively and consists of three main stages:
- Train a baseline model (DNN) using original (non-synthetic) data.
- Identify scenes with incorrect and imprecise predictions (identify failure points).
- A simulator emulates these “problematic scenes” using ground truth objects’ information and randomly perturbing them (domain randomization approach).
- The machine learning model/s is/are retrained again using both newly generated synthetic data as well as existing data.
- Steps 2-4 are repeated until model performance gains converge (become insignificant) or the portion of synthetic data reaches a maximal threshold. Each iteration over steps 2-4 is called an imitation cycle.
The imitation training scheme
Description of the Main Paper Idea
Optimal Synthetic Data Generation Policy: Theoretical Considerations
In this paper, a technique from the family of imitation learning (IL) methods is used. The goal of imitation learning is to obtain knowledge from human or artificially created experts and mimic their behavior. In contrast to the classic IL approach, the authors propose to train DNNs to achieve better performance through optimizing synthetic data generation policy. Optimizing synthetic data generation is done by minimizing expected loss on the task (object detection). The authors dub the proposed technique “imitation training”. Note that, the conditions for convergence of data aggregation based imitation learning were investigated in DaGGER (Dataset Aggregation),
As was mentioned earlier, imitation training has an objective of finding a data generation strategy (policy) minimizing the expected loss on the task. The authors chose 0-1 loss l(.), equal to 1 if the model output is wrong (wrong object detection and mis-detection) and zero otherwise (correct object detection). Mathematically, an optimal data generation policy π* is defined by:
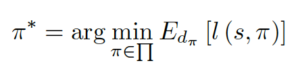
where π is a data generation policy, s is the current state of the trained DNN and dπ is an average distribution over DNN states, achieved by merging synthetic data with the original dataset.
Synthetic Data Generation Policy: How to make it work in practice
The pseudocode of the proposed techniques is laid out below:


Model and Training Procedure
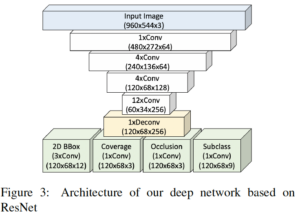
The paper uses ResNet architecture as a main feature extractor to derive output detection proposals from multiple output grids. Afterwards, these proposals are clustered (aggregated) to produce the final detection results. The authors applied the classical binary cross-entropy (BCE) loss for coverage score (a measure of an object’s likelihood to appear within a bounding box), occlusion and classification score training. L1 loss was used for bounding box layer training.
Synthetic Data Proportion Considerations
The paper specifies an upper limit of 50% for synthetic data ratio with respect to real data since the network overfits to synthetic data when the ratio of synthetic data is too high. Yet, the performance of the imitation training is expected to saturate at a certain point due to the following reasons:
- The synthetic data simulator does not have the same or similar assets of the misdetected objects (e.g. unusual road debris)
- The simulator cannot simulate a similar environment (e.g. snowy country roads)
Examples
The truncated vehicle was hard to detect and a synthetic piece of data was created to fix it.

A model trained only on real data had an issue in detecting partially visible trucks and occluded vehicles and generated data fixed it.

Experiments
Datasets
Researchers used two publicly accessible datasets: Waymo Open and KITTI datasets, as well as an in-house dataset from NVidia.
Performance Evaluation
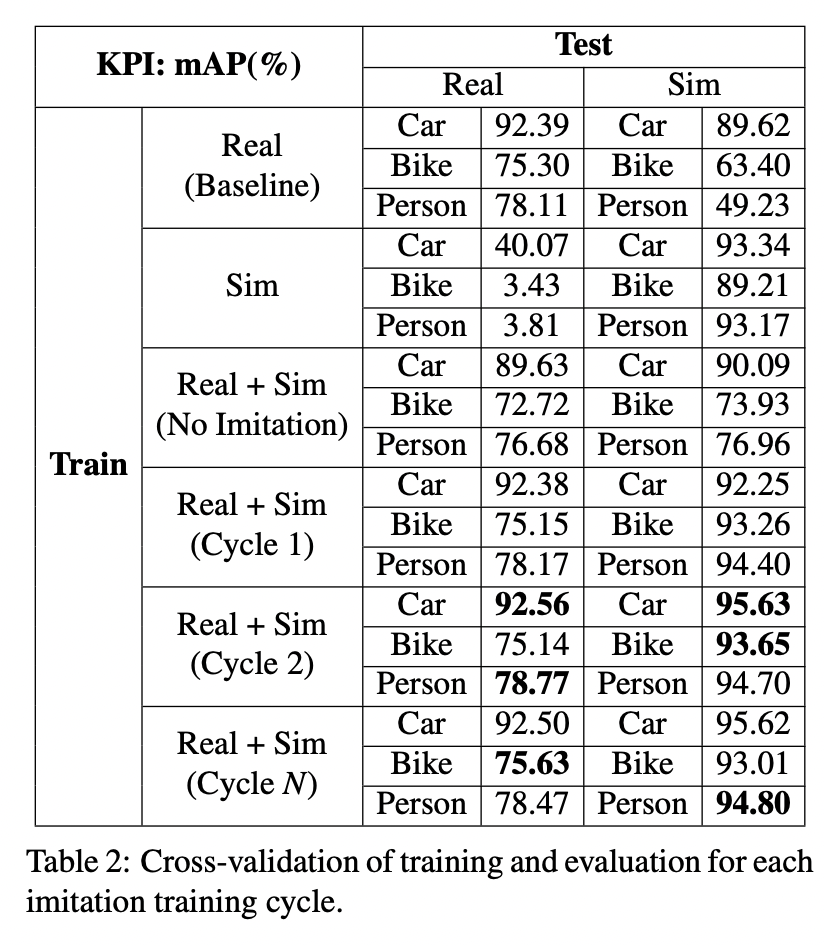
A summary of the proposed scheme’s performance (for in-house dataset) in several training regimes is shown in the table above. mAP (mean average precision) was used as a performance metric. Here is a breakdown of the results:
Model trained only with synthetic data (2nd row – “Sim”) : the model performed poorly with real test data, but well with the synthetic test data. The reason is that real-world scenes are complex, and synthetic data cannot represent them accurately.
Model trained with real and synthetic data without the proposed method (3rd row – “Real + Sim (No Imitation”). Here the model was trained on real data and randomly generated synthetic data. Compared to training on synthetic data, the results were better, but the model showed significant performance deterioration compared to the baseline model (trained on the real data only).
Model trained with real and synthetic data with the proposed method (4-6 rows – “Real + Sim Cycle 1, 2,…). Upon completion of the first imitation cycle, the model showed worse performance compared to the baseline. With more synthetic data (more imitation cycles), however, the results improved and reached the best performance at the second imitation cycle.
Similar performance improvement was observed while applying the imitation training to other datasets. Note that the performance gains achieved with proposed technique aren’t very large (92.5% vs. 92.39 mAP for the car detection)
Simulator Uses For Synthetic Scenes Generation
In order to generate synthetic images, the researchers utilized the game engine simulator Unreal Engine 2. Under the domain randomization paradigm, Unreal Engine 2 can generate diverse scenes with varying time, locations and weather conditions (https://arxiv.org/abs/1804.06516). In addition, obstacles (vehicles, pedestrians, bicycles, etc.) can also be placed randomly or at specific locations in the generated scenes.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
