
























Data-Centric AI: The New Frontier

What Is Data-Centric AI?
The term data-centric artificial intelligence (AI) or data-centric machine learning is a new paradigm for the way AI systems are developed.
Traditionally, model-driven AI focused on creating and training the best possible model for a task, with the data being a second priority. Collecting data, cleaning it, and preprocessing it was a one-off event, and iterations were performed only on model improvements.
By contrast, data-centric AI focuses on systematically iterating over data to improve its quality and performance, with the understanding that data has a huge impact on model performance – even more significant than model performance itself. Data collection, annotation, and preparation of training data is an ongoing process that continues even after models are deployed to production.
In This Article
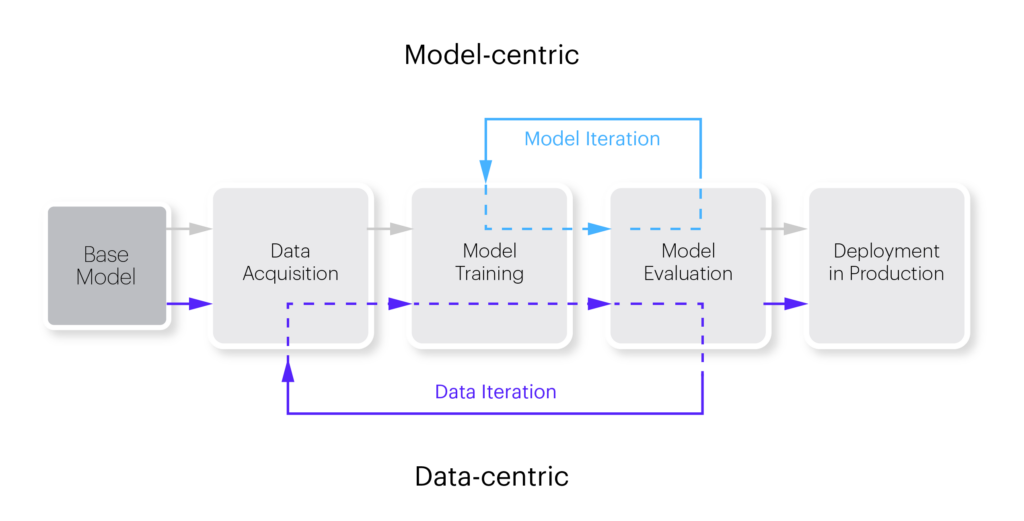
Data-Centric vs. Model-Centric Machine Learning
A model-centric approach focuses on developing experimental iterations to improve the performance of a machine learning model. It involves choosing the most suitable model architecture and training process for your model. You spend most of your time working on code and improving the model architecture while keeping the data as-is.
The case for model-centric machine learning
Most AI applications are model-centric, possibly because the AI sector closely follows academic research on machine learning models, and 90% of these papers are model-centric.
The model-centric approach was also fueled by the success and popularity of neural network models – these models produced impressive results, and so the industry focused on developing them and put the data quality question aside. Researchers taking this approach believed that a larger model with more parameters will provide better results, regardless of the data.
The case for data-centric machine learning
Model-centric machine learning involves focusing on code and treating data collection as a one-time event. However, this approach overlooks the importance of data.
A data-centric machine learning methodology systematically evolves and improves datasets to increase the accuracy of machine learning applications. The central objective of this approach is working on and improving the data. It involves labeling data, which can be a time-consuming endeavor.
The assumption behind this approach is that model improvements will eventually converge, with further model iterations yielding only small improvements. However, data improvements may yield stronger results over multiple iterations. This is especially the case when a model needs to deal with edge cases, and additional data can help the model better understand each edge case.
Data-centric vs model-centric machine learning
Here are key differences between the two approaches:
| Model-centric ML | Data-centric ML |
| The main focus is improving model parameters | The main objective is improving data |
| You deal with data noise by optimizing the model | You work on noisy data by improving data quality |
| Assumes that inconsistent data labels may average out if the model is good enough | Aims to achieve high data consistency |
| Iterations aim to improve model parameters, for example by retraining models | Iterations aim to improve data quality and coverage (for example by adding data about edge cases) |
Related content: Read our guide to ground truth
Data-Centric AI Principles
In data-centric AI development, teams spend more time labeling, screening, and scaling data because the quality and quantity of the data is key to a successful outcome. Therefore, data should be the main focus of iterations in AI projects.
Here are three key principles of a data-centric approach to AI:
- Training data quality—increasingly, important advances in AI development do not come from improved algorithms, feature engineering or model architecture, but from the quality of the training data AI models learn from and their ability to iterate on this data in an agile and transparent manner.
- Scalable strategies—data-centric AI programs are designed to address the large amount of training data required for today’s deep learning models and the practical difficulty of manually and iteratively searching for labels in most real-world environments. Manually labeling millions of data points is impractical, and the process of labeling, managing, scaling, cleaning, and iterating data must be automated.
- Subject matter experts—data-centric AI requires subject matter experts (SMEs) as an integral part of the development process. By incorporating SMEs into the development effort, AI researchers can fully understand how to label and manage data, and leverage SME knowledge directly in their models. This expert knowledge should be structured and used to oversee data quality over time.
How to Adopt Data-Centric AI Approach
Create Datasets in Collaboration with Domain Experts
Data scientists are experts in building algorithms and deriving useful insights from data—but in many cases they are not experts in the business domain. Domain experts can help AI experts understand the business problem, how it can be represented with available data, or how to create new sources of data.
An agile work methodology is an excellent way to organize this effort. Build “stories” describing the business objective of the algorithm you are building, and iterate together with domain experts on data that can help the algorithm learn. In every iteration, the objective is to obtain more and better data that can help the algorithm better meet its defined objectives.
Define How Much Data is Enough
In data centric AI, the amount of data should not only be determined by algorithm considerations (for example, how much data is required to train the model according to the available literature). Many more considerations come into play, which can allow you to invest your efforts wisely:
- Identify what level of accuracy is necessary to provide initial value to the business. For some problems, 70% accuracy could be sufficient, while others problems will require 99.9% accuracy.
- Identify the real world labels or classes that are important for the business problem, and see what distribution of data will allow the model to predict them correctly. You will need enough data representing each label or class.
- Once you have an initial data set, perform initial testing and check empirically how much data is needed to provide meaningful results. In some cases you might discover good performance with a small dataset, which could mean you’ll need less data to succeed.
Whatever the size of your initial dataset, you should create a repeatable pipeline that allows you to add more quality data over time.
Ensure the Dataset is Representative
It is critical to ensure the dataset is representative of real world data. There are several ways to do this:
- Traditional descriptive statistics
- Data visualization tools like pandas-profiling
- Monitor datasets using observability tools like WhyLabs
- Generate synthetic datasets that reflect the real-world data distribution
Note that the real world changes, and so should your data. The dataset must be constantly updated to reflect changes to the underlying population you are modeling.
Acknowledge Bias in Your Dataset
Datasets created by humans are, by nature, biased. When humans collect or create data, this data will reflect their interests and beliefs. While it is impossible to completely eliminate bias, you can aim to identify and minimize it. A good way to identify bias is to use two or more people to annotate the same data points and see where they disagree. Majority voting between annotators can help you discover a label that is in consensus.
Generate Synthetic Data with Our Free Trial! Start Now
Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
