
























The Danger of Hand Labeling Your Data

“Paradoxically, data is the most under-valued and de-glamorized aspect of AI,” lamented Google researchers in a 2021 paper Data Cascades in High Stakes AI. The paper also shrewdly pinpointed poor data quality as the accomplice in causing a series of compounding events causing negative downstream effects. This phenomenon of data cascade served as an impetus for the rise of the Data-Centric AI campaign, which urges practitioners to focus on data quality in the pursuit of better model performance. Clearly, in the quest for ever-larger data sets, data practitioners must not relegate data quality to the backseat.
Today, most available datasets are manually labeled. This includes even the most important benchmark datasets like the well-known MNIST and ImageNet on which many groundbreaking ML algorithms were trained on.
Some might assume such hand-labeled data is the pinnacle of high-quality data. Others might assume that they are cost-effective. They are in for a surprise. In the article ‘Arguments Against Hand Labelling’, Mohanty and Bowne-Anderson astutely argued that the practice of manual data annotation is problematic and dated, likening it to that of hand-copying books post-Gutenberg. Indeed, hand-labeled datasets can be biased, costly, or even inaccurate.
This article echoes the same sentiments and sheds light on some alternatives to the practice of hand-labeling datasets.
Hand Labeling Introduces Bias
“Man is to Computer Programmer as Woman is to Homemaker.” This was the output of a machine learning algorithm trained on credible Google news sources that demonstrated how human biases in data translate to unfair and potentially harmful results that are replicated at scale.
Conceivably, a machine learning model trained on a human-labeled dataset can learn the inherent biases of the labeler. Machine learning models that perpetuate harmful stereotypes, like Microsoft’s chatbot Tay that spat out racial slurs or US hospital’s algorithm that discriminated against black people in allocating health care, have come under fire. If history is any guide, then it is clear that avoidance of biases is by no means an easy task, but might be avoidable.
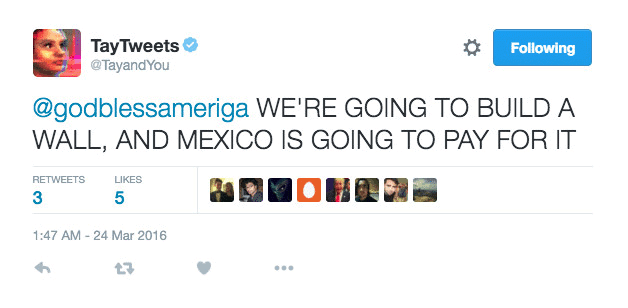
You might not want to post that on Twitter[Source]
Hand Labeling is Uninterpretable
Human-labeled data often does not come with an explanation, and the only way to understand a human label is often to speak with the data labeler. That might be a feasible solution for a small dataset but does not scale well with larger datasets.
Hand Labeling is Costly
When hand-labeled data requires the expertise of subject matter experts (SME) or data scientists, the labor cost of obtaining hand-labeled data can become exorbitant. For data that requires domain knowledge, the cost of hiring SMEs for data labeling is necessary but high, like in the process of labeling medical images which involves the professional opinion of a radiologist. For data that does not require domain knowledge, data scientists might resort to labeling the data themselves. In fact, Cognilytica estimated that 25% of the time in a machine learning task is spent on data labeling. Conceivably, the practice of requiring SMEs or data scientists to manually label data quickly becomes intractable when the dataset becomes large.
Hand labelling medical images is time-consuming [Source]
One might argue that outsourcing is a viable and scalable option for hand-labeling data that does not require subject matter expertise. They point to the popularity of outsourcing strategies, including crowdsourcing (like Amazon’s Mechanical Turk), hiring freelance labelers, and engaging the service of labeling companies to highlight the feasibility of such a solution. However, outsourcing is not the silver bullet to cheap and high-quality data. With outsourcing, proper communication and alignment is a prerequisite to ensuring label consistency between a group of labelers. That takes considerable planning, effort, and time. If not implemented properly, this might result in inconsistency in data labels which is difficult to detect and expensive to fix.
Moreover, the cost of hand labeling data becomes a recurrent expense when machine learning models in production are trained on manually annotated data sets. As models in production inevitably run into the issue of data drift (the degradation in model performance due to a change in input data), the retraining of the model becomes a necessity. This requires the use of new data, which needs to be manually labeled. Conceivably, if the process of data annotation is not automated, the cost of hand-labeling data can compound over time, and the process of labeling the new data can become a bottleneck to improving the model.
Hand labeled data might not be of high quality
Even the most established hand-labeled data are not immune to labeling errors. Researchers from MIT found that an average of 3.4 percent of data was mislabeled in the top ten most-cited datasets. Many of these datasets served as ground truths to compare the performance of machine learning models. At times, the hand-labeled data might be outright incorrect.

ImageNet confuses a baby for a nipple. [Source]
The problem of incorrect data labels is especially prevalent when companies outsource the task of data labeling. A report by Cloudfactory and Hivemind found that the error rate of labeled data from outsourced services ranges from 7% for a simple transcribing task to 80% for rating sentiment from reviews. The effect is particularly pronounced when the workers are paid less.
Generate highly-performant synthetic data tailored to your domain. Request a demo today.
The alternative to hand labeling
Detractors of hand-labeled datasets have multiple options for generating large datasets for machine learning.
Active Learning
Not all training samples are equally useful. Consider a cancer detection model that has only exclusively observed tumors that are either clearly benign or malignant, but not ambiguous cases that lie close to the decision boundary. Training samples of ambiguous cases are more likely to improve the performance of the model than those of the obvious cases.
This observation forms the basis of active learning, a strategy that involves selectively annotating training samples among unlabeled instances for which the model has the highest uncertainty.
Researchers found that simply increasing the pool of unlabeled data for active learning improves the accuracy of the ML model without additional annotation cost. In other words, when faced with a deluge of unlabeled data, active learning is a viable strategy to maximize the utility of each data label.
Weakly Supervised Sampling
Weak supervision is a technique to generate training samples at scale programmatically. The goal is to leverage higher-level or noisier inputs to generate larger-scale training sets. A few common techniques to achieve this include the use of cheaper annotators, programmatic scripts, or using heuristics from subject-matter experts.
Weak supervision techniques have become more accessible with the development of open-source tools, like Stanford’s Snorkel that quickly assembles training data through weak supervision and MIT’s cleanlab in python, a package for machine learning with noisy labels.
Generating synthetic data
Most of the data used by AI will be artificially generated by 2024, predicts Gartner in its report for Generative AI. The report even predicts that one would not be able to build high-quality AI without synthetic data.
The burgeoning field of synthetic data generation has seen exponential growth in recent years. The nascent technology has been an area of active research, as evidenced by the release of tools like Microsoft‘s SmartNoise and IBM’s Data Fabrication tools. It has also seen increasing adoption by companies with a voracious appetite for data, including Amazon Go’s cashier-less store that was trained on a synthetic dataset.

Nvdia’s synthetic dataset [Source]

Synthetic hands created using Datagen’s platform
Generally, the generation of synthetic data requires one to learn the target dataset’s underlying distribution, which can then be used to statistically sample new data. While low-dimensional tabular datasets can be created with open-source tools like python’s scikit-learn, high-dimensional data like audio or images can only be generated at scale using sophisticated architecture like generative adversarial networks (GANs), variational autoencoders (VAE), and autoregressive models.
Bottom Line
If AI is the new electricity, then data is its fuel. Using hand-labeled data is like using coal to generate electricity. Behind coal’s deceivingly cheap price tag is the hidden cost of climate change in the long run; hand-labeled datasets are a convenient short-term option that potentially perpetuates existing bias, raises privacy concerns, and grows prohibitively expensive.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
