
























How Synthetic Data Enables Data-Centric Approaches

The speed, scale, and control of synthetic data
The practice of model-centric approaches to deep learning is deep-rooted within the AI community. Undeniably, the model-centric approach has led to groundbreaking advancements in the design of AI models.
A paradigm shift is on the horizon. Some practitioners are starting to recognize the weaknesses of model-centric approaches, and instead opting for a data-centric approach. They point to the oft-neglected potential of bettering AI systems by systematically improving the training and testing data.
A marked departure from the model-centric approach, the data-centric approach represents the practices that iteratively improve the underlying data’s quality and/or size while holding the model architecture constant (Figure 1).
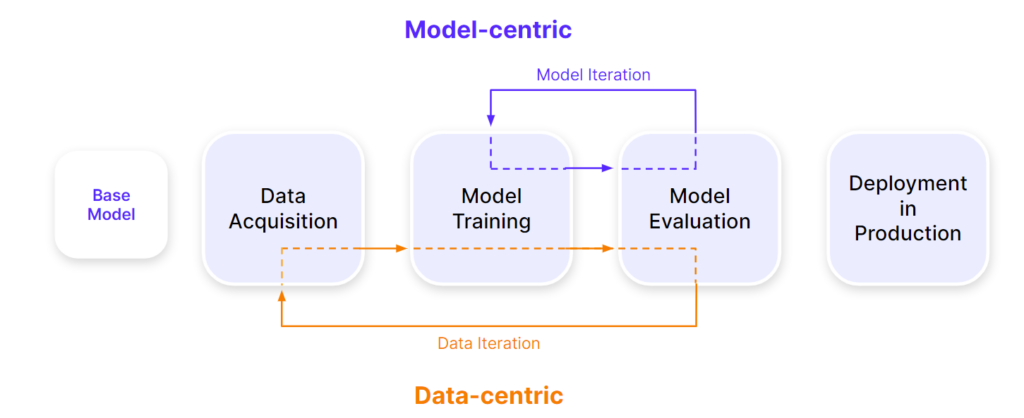
Figure 1. The difference between data-centric and model-centric approaches
To improve the datasets, one can improve the labeling consistency by having multiple labelers agree on all data points. Another method is to remove ambiguous labels that might contribute to dirty training signals.
The data-centric process is costly for manually annotated real-world datasets. Hand labels can also come with undesirable biases and errors. Against this backdrop, synthetic data is touted as the driver of data-centric AI. Synthetic data is artificially-manufactured data that does not represent events or objects in the real world.
Synthetic data triumphs over real-world data in many aspects. In this blog post, we explain why synthetic data offers the speed, scale, and control needed for a data-centric approach.
Watch On-Demand “Implementing a Data-Centric Methodology with Synthetic Data”
Synthetic data can speed up the iterative improvement of a dataset
A part of a data-centric approach is to perform error analysis, where incorrect predictions made by the model are singled out for further analysis. This ties in with the test-driven development, where practitioners create test cases to ascertain a model’s robustness. The weaknesses of the model are ameliorated by iteratively adding and/or improving on the data.
In most cases, collecting real-world data that fulfills the criteria is arduous. The search for open-sourced photos from existing datasets might also be futile.
The laborious process of data annotation is apparent in the process of the well-known Cityscapes dataset, a diverse set of video sequences recorded in 50 cities.
The process of labeling 5000 images with fine pixel-level annotations (Figure 2A) takes 1.5 hours on average each, amounting to a whopping 7,500 hours in total. Only by reducing the granularity of the annotation (Figure 2B) can the authors cut the amount of time needed to label an image to 7 minutes.

Figure 2A. Fine pixel-level annotation of a street from Cologne [Source: Cityscapes]

Figure 2B. Coarse polygonal annotation of a street in Saarbrücken [Source: Cityscapes]
The slow speed of data annotation forms a significant drawback. This is where synthetic data performs better than real-world data.
In most cases, synthetic data can be generated faster than one can collect real-world data. Moreover, the generated data is automatically labeled and does not require the input of a manual annotator.
Thus, researchers found an opportunity to complement Cityscapes using a synthetic dataset, SYNTHIA (Figure 3). This dataset addresses the limitations of Cityscapes. Not only does Synthia has automatic pixel-level annotation, but it also features a variety of objects and geographies that the researchers found to be absent in other datasets.

Figure 3. A sample frame (Left) with its semantic labels (right) from the SYNTHIA Dataset.
In a similar vein, practitioners aiming to complement their datasets can turn to synthetic data. For instance, if an object detection model is consistently underperforming in detecting dark objects against dark backgrounds, then they could iteratively add such synthetic images to the training and testing datasets.
Synthetic datasets are more scalable than real-world dataset
Real-world data is often limited in size and scale due to the cost of manual data collection and annotation.
“Many existing datasets do not have the volume of data needed to make significant advances in scene understanding that we aim in this work,” lamented researchers from the University of Cambridge working on understanding real-world scenes.
They substantiated the claim with examples like NYUv2 and SUN RGB-D, which are indoor environment datasets that have only 795 and 5,285 images respectively. Unfortunately, these datasets are small and contain errors. (Figures 4A and 4B)
|
Figure 4A. Missing labels from SUN RGB-D [Source] |
Figure 4B. Mislabeled frames from SUN RGB-D [Source] |


As such, the researchers created a synthetic dataset called SceneNet (Figures 5A and 5B), an open-source repository of annotated synthetic indoor scenes built using CAD models.
|
Example 5A. Sample office scene from SceneNet |
|
Example 5B. Examples of training data from the same scene |


The authors can place virtual cameras in the synthetic scenes, granting them the ability to generate potentially unlimited ground truth labeled data from different viewpoints (Example 5B). The authors also generated novel scenes and added noise to the synthetic data.
Data-hungry AI applications like object detection models require huge datasets to achieve optimal performance. For such use cases, generating synthetic data is often a better and cheaper solution to increasing the size of the dataset than collecting real-world data.
A case in point is a facial landmark detection model. In the paper “Facial Landmark Detection Using Synthetic Data”, we experimented with various strategies for combining synthetic and real data. We demonstrated that we could use 50 real data points to achieve a performance equivalent to training with more than 250 real-labeled images.
Watch On-Demand “Implementing a Data-Centric Methodology with Synthetic Data”
Practitioners have more control over synthetic datasets than real-world dataset
The advent of synthetic data grants AI practitioners significant control over their datasets. With real-world data, AI practitioners are at the mercy of circumstances that might prevent them from collecting rarely-occurring data points. Unfortunately, this usually leads to models that underperform in edge cases.
Such is the problem reported by researchers building a crowd-counting computer vision model. They cited the lack of data variety across the type of weather, illumination, and crowd size as the reasons for performance degradation. Not only that, they lament the label inaccuracy of real-world labels.
As a solution, the authors constructed a large-scale synthetic crowd counting dataset entitled GTA5 Crowd Counting Dataset (GCC) using a computer game (Figure 6). By controlling the crowd size, weather conditions, and time of day (Figure 7), the researchers crafted a diverse dataset customized for their use case.

Figure 6. The author created the GTA5 Crowd Counting Dataset (GCC)
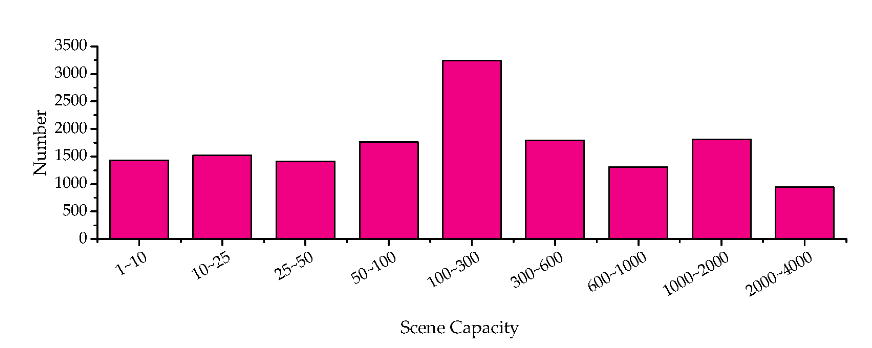
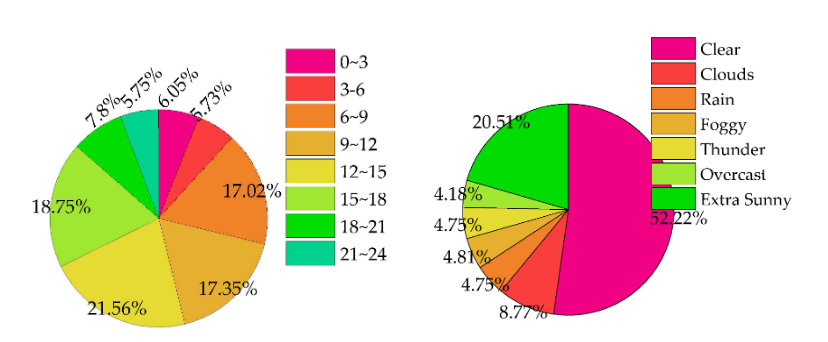
Figure 7. The distributions of the GCC dataset across different conditions
Recent advances in synthetic data meant even more precise control of photorealistic synthetic data today, as evident from the recent CVPR 2021. For instance, GIRAFFE allows practitioners to independently position, orientation, and perspective of an object (Figure 8). On the other hand, HistoGAN provided a histogram-based method to control the colors of synthetic images (Figure 9).

Figure 8: Images generated by GIRAFFE, a compositional 3D scene representation [Source]

Figure 9. Images generated by HistoGAN [Source]
Synthetic data as the enabler of data-centric AI
Indeed, recent years saw the proliferation of papers proposing novel model architectures and optimizing the process of hyperparameters tuning. While model-centric approaches have served the AI community well in the past, data-centric approaches are beginning to take the spotlight. As data-centric AI takes off, so will the use of synthetic data thanks to its speed, scale, and control.
Watch On-Demand “Implementing a Data-Centric Methodology with Synthetic Data”
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
