
























DigiFace-1M: 1 Million Digital Face Images

This is the first part in our series on facial recognition
Microsoft generated quite a bit of buzz this month when it released the DigiFace1M, a large-scale synthetic dataset for face recognition. It is akin to a refreshing breath of air when compared to existing large-scale image datasets – it is generated without privacy violations and consent issues that plague today’s face datasets. With 1.22 million images of 110k identities, it prides itself as the largest public synthetic dataset for face recognition.
Figure 1. DigiFace-1M (Source)
{kind=link}
In today’s post, we will cover:
- The challenges DigiFace-1M solves
- The characteristics of the dataset
- The process of generating the dataset
- The results of the dataset
Real-world data has real troubles
Real-world face data is rife with problems. It suffers not only quality issues due to the noise in the label and the bias in the data, but also thorny ethical challenges.
Firstly, real-world data is noisy and teems with mislabels. One need not look further than the Labeled Faces in the Wild dataset to find such examples.
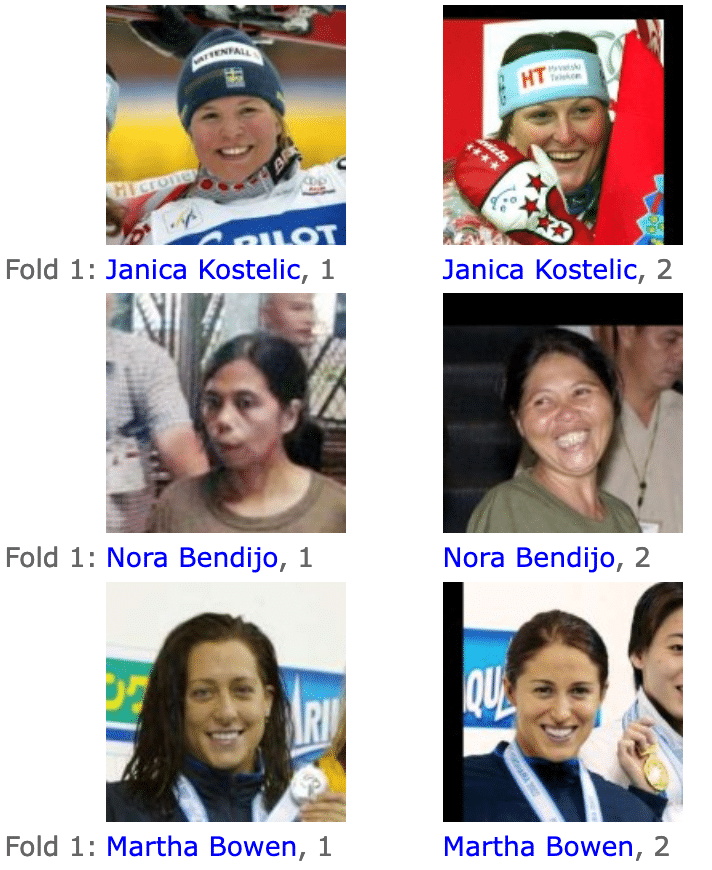
Figure 2. In Labeled Faces in the Wild, we see examples of different people of the same name being given the same label. (Source)
Generate Synthetic Data with Our Free Trial. Start Now!
Secondly, real-world data is unbalanced and biased. Real-world face datasets often consist of the faces of celebrities. Alas, the severe race imbalance of Hollywood celebrities translates to a class imbalance of datasets like CASIA-WebFace (Figure 3). Not only that, celebrity faces are often touched up with make-up and strong lighting, which are uncommon in the real world.

Figure 3. The lack of representation in CASIA-WebFace is apparent just from a sample of its images (Source)
Lastly, real-world data raises thorny ethical problems. It’s rare for a large-scale face dataset to be collected with the informed consent of the participant. Conceivably, such malpractice amounts to a violation of privacy.
It seems far-fetched that real-world data could effectively cut these Gordian knots. It’s no surprise that Microsoft used synthetic data to circumvent these issues. More concretely, it recently introduced a large-scale face dataset consisting of only synthetic digital faces.
DigiFace-1M is the state-of-the-art synthetic face dataset
Armed with 1.22 million photorealistic face images with an impressive 110,000 unique identities, DigiFace-1M is the largest public synthetic face dataset to date.
Rendered with a computer graphics pipeline, the dataset is photorealistic and diverse. It consists of fictional persons (hereafter called “identities”) which are generated with random facial geometries and textures. The same identity can have different hairstyles (Figure 4).

Figure 4. The same identity can have different hair color, density, and thickness in DigiFace-1M (Source)
{kind=link}
Each identity also has its random accessories like clothes, glasses, make-up, face-wear, and head-wear. As the color, density, and thickness of facial, and head hair are randomized, the variety of the dataset is further enhanced (Figure 5).

Figure 5 (Source)
{kind=link}
To simulate the conditions of real-world data, every identity is then given a variety of poses, facial expressions, lighting conditions, camera angles, and background (Figure 6).

Figure 6 (Source)
Real-world datasets are often skewed in distribution. Put simply, some faces are featured more than others. To replicate that, DigiFace1M is broken into two parts. The first part consists of 10k identities, each of which has 72 images. The next part has 500k identities which have 5 images each.
The generation pipeline of DigiFace-1M
The paper stood on the shoulders of giants; it reused the existing state-of-the-art face generation pipeline (“Fake it Till you Make It” by Wood et al). This pipeline boasts its ability to synthesize face images with minimum domain gap (a catch-all term used to describe the difference between synthetic and real-world faces). Read more about the pipeline in our blog.
To further close the domain gap, DigiFace-1M varied its face images with extensive data augmentation. Real-world images are imperfect – shaky hands lead to blurry photos and poor photography skills cause occluded faces. Instead of only including picture-perfect images, DigiFace-1M adds flaws to its images through a series of flipping, cropping, wrapping blurring, downsampling, and compression. (Figure 7).

DigiFace1M achieves amazing feats in benchmarks
Like other state-of-the-art methods, DigiFace1M is evaluated on a benchmark dataset, Labeled Faces in the Wild (LFW), which consists of 13k images of 5.7k people.
To benchmark DigiFace1M against real-world data, the researchers trained a few facial recognition networks using different datasets. As demonstrated in Figure 8, these variations include:
- Training only on DigiFace1M (black dashed line)
- Training only on real faces (red line)
- Training on a combination of both DigiFace1M and real faces (blue line)
- Training on DigiFace1M, then fine-tuning on real faces (black solid line).
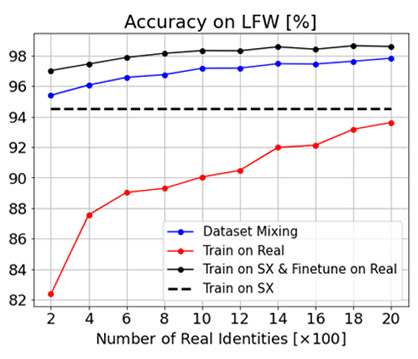
Figure 8. The result of multiple face recognition models trained on DigiFace-1M and/or real-world data on the LFW benchmark (Source)
{kind=link}
It was found that
- The model trained on synthetic data only outperforms that trained on real-world data only, when only a small number of real face images are available.
- The best results are obtained when the facial recognition model is trained on synthetic data, then fine-tuned with real-world data.
Impressively, the best model achieved a whopping 99.33% accuracy on the Labeled Faces in the Wild benchmark. This is when the model is trained on DigiFace and then fine-tuned with real faces.
The researchers reported a consistent finding when the other benchmark datasets are used. For example, DigiFace-1M reported impressive results when benchmarked against the challenging Celebrities in Frontal-Profile (CPLFW) which has large pose variations, as Figure 9 demonstrates.
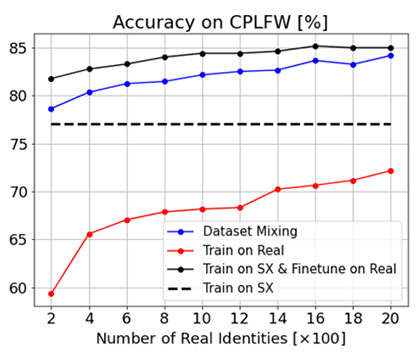
Figure 9. The result of multiple face recognition models trained on DigiFace-1M and/or real-world data on the CPLFW benchmark (Source)
{kind=link}
The results are exciting but not entirely surprising to us. We found similar benefits to using synthetic data from our paper “Real and Synthetic Data for Facial Landmark Detection”.
DigiFace-1M is not generated with GANs
Sharp-eyed readers might notice that mentions of GAN (generative adversarial network) are conspicuously missing in this piece. That is because DigiFace-1M is not generated with GAN.
Instead, DigiFace-1M is rendered using a computer graphics pipeline and performs competitively when compared against cutting-edge GAN datasets.
Datasets generated with GAN suffer from several problems that DigiFace does not. For example, the defining characteristics of a GAN-generated person might change when the person’s pose or background is altered. Also, there is no flexibility to change the accessories. Most pressingly, GANs are trained on real-world datasets and thus suffer from unresolved ethical and demographic bias concerns.
The challenges of DigiFace-1M
Admittedly, DigiFace-1M is not foolproof. The pipeline does not comprehensively close the domain gap. In particular, it cannot generate the same person at different ages. Since an identity always has the same hairstyle, DigiFace-1M also lacks variation in hairdos or haircuts. Further, it does not generate accessories that cover parts of the body like jewelry and tattoos.
Identities of DigiFace-1M also lack demographic labels. As a result, there could be a potential bias towards certain demographic profiles. Thus, it cannot be used to alleviate the biases of existing models, which is done by adding identities of the underrepresented demographic groups to the training dataset. To address this weakness of DigiFace-1M, the authors could consider generating identities with demographic labels. In fact, we managed to uncover population biases using the demographically-labeled synthetic faces generated with our inhouse tools.
We are confident that these limitations will be addressed in one way or another in future research. At the rate synthetic data technology is developing today, there is no doubt that future digitally generated face datasets will continue to challenge the state-of-the-art.
Generate Synthetic Data with Our Free Trial. Start Now!
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
