
























Microsoft’s Face Analysis in the Wild Using Synthetic Data Alone – Summarized

From unlocking your iPhone with your face to making payments with a glance at a camera, facial recognition technology has afforded us convenience unimaginable just years ago. Yet, collecting the necessary data for facial recognition tasks is not always a walk in the park. Not only does collecting and labeling face data require significant effort and cost, the very practice of using face data for machine learning is also rife with problems of fairness and privacy.
It is no wonder that the machine learning community has turned to synthetic data for training machine learning problems. With synthetic data, one can guarantee close-to-perfect labels without possible bias of human annotators at scale

Figure 1. Synthetic faces generated by Microsoft
Despite this turn towards synthetic solutions, face-related machine learning researchers rarely train models with only synthetic data. Real-world data is often added to the training set as well. Moreover, models trained on synthetic datasets often need to be adapted to fit the real-world data or use real-world data for regularization.
The Domain Gap
What is stopping researchers from using exclusively synthetic data (and no real data) to train machine learning algorithms? The roadblock is the significant amount of time needed to generate realistic synthetic faces. As such, many researchers resort to creating more simplistic and less realistic faces. This leads to a significant difference in distributions between the real and synthetic face dataset, or what is known as the domain gap.
Fake it till you make it – Microsoft’s solution to the domain gap
The domain gap is the culprit for the common assumption that synthetic data cannot fully replace real data for face-related problems in the wild. Microsoft’s paper “Face Analysis in the Wild Using Synthetic Data Alone” (Wood et al., 2021) challenged such an assumption by generating synthetic data so realistic that the domain gap is minimized.

Figure 2. Microsoft’s synthetic faces (Image by Microsoft)
The procedure
In this paper, Microsoft procedurally constructs realistic and expressive synthetic faces using a large library of high-quality assets.

Figure 3. Microsoft’s procedural process starts with a template face, which is then randomized with identity, expression, texture, hair, and clothing before being rendered in a random environment (Image by Microsoft)
Let’s walk through each step in detail.
Step 1. Generate a template face
The generative 3D face model can account for variations in face shape across facial expressions and the human population. Microsoft leveraged the face rig built in their previous work (Gerig et al., 2017) as a template face.
Step 2. Randomize the face’s identity
To customize each face with an identity, Microsoft collected raw high-quality 3D scans of 511 individuals, which were cleaned by removing hair and noise (Figure 3). Such scans formed the learning dataset used to fit a normal distribution, from which face models with different identities are generated (Figure 4). Thanks to the diversity of the individuals whose 3D scans were taken, the model was able to capture the diversity of the human population (Figure 5).
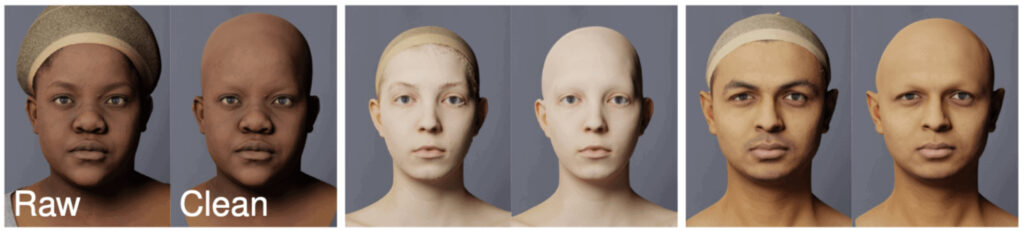
Figure 3. High-resolution 3D scans of individuals before and after cleaning

Figure 4. Faces of diverse identities sampled from the generative model
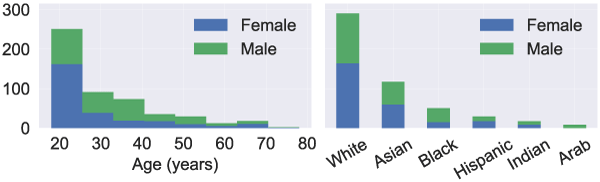
Figure 5. Self-reported age, gender, and ethnicity of participants in the scan collection.
Step 3. Give the face a random expression
Subsequently, each face gets a random facial expression from Microsoft’s database of expressions. To build this database, Microsoft fit a 3D face model using 2D images and sampled expressions from manually animated sequences.

Figure 6. Faces of various expressions in Microsoft’s expression library and animated sequence
Step 4. Randomize the face model’s texture
The face’s texture (which gives it skin color, bumps, pores, and wrinkles) gives it a realistic appearance, as is the case when comparing Figures 7A and 7B below.

Figure 7A. A face model without texture | Figure 7B. A face model with texture.
Step 5. Randomize the hairstyles
A face model will not be complete without hair. For that, Microsoft modeled hairstyles of scalp hair, but also those of eyebrows, beards, and eyelashes (Figure 8). The authors’ effort at capturing the complexity of the hair is evident in their representation of hair as individual 3D strands (thereby capturing the effect of lights coming from multiple angles) and use of a physically motivated hair shader (which allows the authors to accurately model the hair’s complex material properties.)

Figure 8. Each 3D face gets a random hairstyle and appearance.
Step 6. Dress it up
The faces are then dressed with 3D clothing from Microsoft’s digital wardrobe consisting of outfits, headwear, face wear, and eyewear (Figure 9). The garments are made to fit snugly with an appropriate deforming technique, and eyeglasses are made to rest on the temples and nose bridge.

Figure 9: Microsoft’s diverse wardrobe
______

Watch Now: On-Demand Webinar with Microsoft and Meta
Model Performance in the Wild
The author touts their synthetic data (Fig 10) as so realistic that models trained on this data generalize to real, in-the-wild datasets. The authors support this claim by benchmarking the performances of models trained on synthetic datasets against those on real-world datasets. Indeed, the former’s performance was comparable to that of the latter in the tasks of face parsing and landmark localization.

Fig 10. Synthetic face data generated by Microsoft
Such finding is impressive considering that the former was trained on synthetic data and tested on real-world data, leaving no room for the model to learn any potential biases present in the test dataset. On the other hand, the latter was trained and tested on the same real-world dataset.
The Need for Label Adaptation
For both the tasks of face parsing and landmark localization, Microsoft used a technique called label adaptation. Since Microsoft’s model was trained on synthetic data, it had only seen synthetic labels and not a single human-annotated label. Conceivably, it will learn the way synthetic labels are generated. Given real-world data, it generates labels that resemble synthetic labels, not real-world labels.
Yet, differences between synthetic and real-world labels are inevitable. For example, the exact boundary between the nose bridge and the rest of the face might be labeled differently. Microsoft bridged the gap between synthetic and real-world data with the process of label adaptation, which transforms labels predicted by synthetic data model into labels that are closer to the distribution in the real-world dataset. This technique allows fair comparison with previous work (Figure 11).
Figure 11. Label output by synthetic data model after model adaptation (C) is closer to ground truth (D) than that before (B). Here, the main difference between synthetic (B) and human labels (D) is in the way the hair is labeled.
Task 1. Face parsing
The task of face parsing is to assign a class (like eyes, mouth, nose) to a pixel in an image. To prepare its face models for prediction, Microsoft used landmarks to align faces before scaling and cropping each image. The preprocessed images were then used to train a face-parsing model. Post-prediction, the preprocessing changes were reversed to compare the results against the original label annotation.
The trained model was then ready to parse real-world faces from the LaPa dataset consisting of challenging expressions, poses, and occlusions. The model trained on synthetic data was neck-to-neck with the state-of-the-art models trained on real-world data in terms of model performance after model adaptation (Figure 12).
Figure 12. Label outputs by both real-world data model and synthetic data model are practically indistinguishable from the ground truth label
Task 2: Landmark Localization
Another common face analysis task is landmark localization (finding the positions of various facial points in 2D).
To do so, Microsoft trained ResNet34 architectures on two datasets – one synthetic and one real-world. The models were then compared on the landmark localization task apple to the 300W dataset. For the model trained on synthetic data, the output labels were processed with label adaptation before comparison with the model trained on a real-world dataset.
In this task, Microsoft’s model trained on synthetic data demonstrated superior performance as compared to that trained on real data across a variety of expressions, light conditions, pose, and occlusions (Fig 13). The authors also noted that the network trained with synthetic data can detect landmarks with accuracy comparable to recent methods like LaplaceKL (Robinson et al., 2019) and 3FabRec (Browatzki et al, 2020) which were trained with real data.
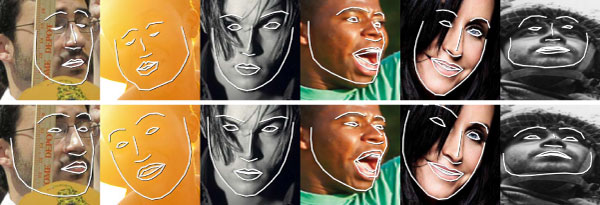
Figure 13. Predictions by models trained on real (top) and synthetic data (bottom).
Other Potential Applications
Having verified the effectiveness of synthetic data in training accurate models for face parsing and landmark localization, the authors are optimistic about the potential of synthetic data as a replacement for real-world data where real-world data falls short. In particular, real-world data on eye-tracking (Figure 14) and dense landmarks (Figure 15) are hard to come by due to the high cost of human labelling. This is where synthetic data can be used to train models exclusively without the help of real-world data.

Figure 14. Datagen’s Synthetic Eyes Dataset

Figure 15. Synthetic data allows for dense landmarks to be labeled and predicted.
The Future of Synthetic Faces is Here.
Such a finding by Microsoft is only part of the incremental progress that the synthetic data community is making towards creating better and more scalable synthetic data. Now that models trained on synthetic data conquered the tasks of face parsing and landmark localization, it is only time before we realize the potential of synthetic data in other face-related tasks.
Generate customized plug & play face datasets instantly
Datagen provides high variance, photo-realistic simulated data at scale to bring AI models to production faster. We focus on human-centered applications that require data featuring humans, environments, and human-object interactions. Our data-centric technology delivers visual data with broad domain coverage and fully-controllable variance.

Figure 16. Synthetic face data generated through the Datagen Platform
Using our Platform, you can generate high-fidelity face datasets with associated ground truth, in a seamless and scalable way.
- 100K+ unique faces generated from high-res scans
- Diverse pool of identities with different ethnicities, ages, genders, and BMIs
- Full control of facial expressions and head poses
- 5,000+ hair styles and facial hair
- Control over extrinsic and intrinsic camera parameters
- Wide range of lighting and background options
Contact us today to get a free face dataset.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
