
























Eye Datasets

The eyes are the window to the soul. Or so the saying goes. But they’re also a window to a wide range of applications for Computer Vision development. From eye tracking to gaze estimation, eye-focused datasets are powering computer vision applications in a wide range of verticals. Here are a few examples:
- Virtual and Mixed Reality head-mounted devices rely on eye-gaze estimation to enable efficient rendering and to offer the user realistic interaction with the content. By being able to detect where your gaze is, the VR device can render only that part of the scene thus enabling higher quality for that segment and a more seamless experience. This technique is called foveated rendering and can significantly alleviate the computational and energy burden of VR.
- Gaze tracking is used in assistive devices for sight-impaired people. Additionally, eye-tracking can help people with motor-impairments interact with computers and can be used to control robotic arms and powered wheelchairs.
- In commercial contexts, eye tracking and gaze estimation are used to determine engagement with advertisements and content. Eye tracking can be used to provide valuable insight into which features on a web page or in a physical store are the most eye-catching and engaging.
- Many car manufacturers leverage eye-tracking technology to enhance safety and driver fatigue detection. The ability to classify eye states based on pupil dilation, blink-rate, or eye-closures provides a key metric for detecting drowsiness among drivers. Fatigue causes 20% of car crashes, so the ability to diagnose fatigued drivers and alert them to take a break can save thousands of lives.
The key to developing Computer Vision applications is Data. In this case, large datasets of eyes are the key to continue developing and improving the technologies outlined above. There are a number of eye datasets, each with different features and focuses. To help teams locate the dataset best suited to their needs, we’ll examine some popular and high-quality datasets focused on eyes.
Labeled Pupils in the Wild (LPW):
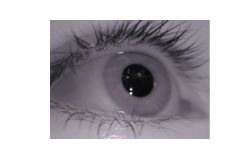
- Affiliation – Max Planck Institute for Informatics.
- Publication – ETRA
- Released – 2016
- Description – LPW is a dataset of 66 high-quality and high-speed eye region videos. The videos were recorded from 22 distinct participants in different locations at 95 FPS using an advanced head-mounted eye tracker. The dataset includes participants of different ethnicities, in both outdoor and indoor settings. The dataset includes different variants such as subjects wearing makeup, contact lenses, and glasses.
- Camera Angles – This dataset contains continuous camera angles of the pupil. Researchers achieved this by having the subjects manually move or remove the eye-tracker resulting in a wide range of camera angles.
- Main Use – This Dataset is designed for pupil detection, which is used to map 3D gaze Estimation.
- Number of Images – This dataset consists of 66 videos, which make up 130,856 separate frames.
- Subjects – 22
- Annotations – The researchers used a variety of annotation methods. Including several rounds of manual annotation, and different segmentation methods.
- Bottom Line – The dataset is available for research and non-commercial use. The LPW dataset is a robust dataset that offers both indoor and outdoor images and has ground-truth annotations that make it a very useful dataset for teams looking for high-variance datasets.
Watch On-Demand “Implementing Data-Centric AI Methodology” with Microsoft and Meta

- Affiliation – University of Georgia, Massachusetts Institute of Technology, MPI Informatik.
- Publication – CVPR
- Released – 2016
- Description – Gaze Capture is a large-scale eye-tracking dataset captured via crowdsourcing. It features 1474 subjects that captured themselves using their cellphones. researchers created an iOS app that users could download and use to capture their eyes. Thus, the researchers were able to collect data at scale.
- Main Use – The dataset is designed to help teams infer gaze location.
- Number of Images – 2.5 Million Frames
- Subjects – 1474
- Bottom Line – GazeCapture is a very large-scale dataset, it was the first eye-tracking dataset to leverage crowdsourcing. It features a high degree of variance. Subjects of different ages, ethnicities, and appearances captured themselves on their phones in a variety of locations and with different lighting.
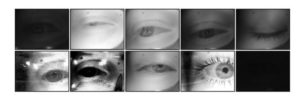
- Affiliation – Nvidia, University of North Carolina
- Publication – ACM
- Released – 2019
- Description – NVGAze is two datasets wrapped in one. The first is a synthetic dataset created based on anatomical models with a built-in variation. This dataset has roughly 2 Million RGB-D infrared images, rendered in 1280×960 resolution. The second is a manual dataset with roughly 2.5 MIllion images at 640×480 resolution.
- Main Use – This dataset is used for real-time gaze estimation and tracking. Gaze estimation is identifying the line of sight at any given moment, while tracking is the ability to continuously follow the line of sight.
- Number of Images – The Synthetic Dataset contains 2 Million Images. The Manual Dataset contains 2.5 Million.
- Subjects – The manual dataset has 35 subjects.
- Annotations – The Synthetic Dataset has perfect ground truth. Specifically, “Each image is labeled with the exact 2D gaze vector, 3D eye location, 2D pupil location, and a segmentation of pupil, iris, and sclera, skin and glints (corneal reflections)”.
- Bottom Line – This is a very robust and large-scale dataset that leverages the latest in synthetic data to enable users to benefit from data at scale that is high quality and has annotations with perfect ground truth.
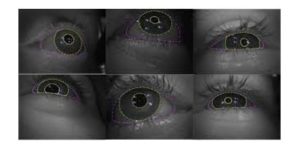
- Affiliation – Magic Leap Inc
- Released – 2020
- Description – MagicEyes is the first large-scale eye dataset collected using head-mounted MR (Mixed Reality) devices. The goal of the dataset was to provide data to power advances in the eye-tracking ability of head-mounted MR and XR devices.
- Main Use – This dataset was designed specifically for applications where gaze-estimation needs to be done in off-axis settings where there is a large angle between the camera and the user’s gaze. This angle can cause difficulty discerning the angle of the subject’s gaze, and partial occlusions.
- Number of Images – 880,000
- Subjects – 587
- Annotations – 80,000 of the images feature manually annotated ground truth in 3D and segmentations. The rest of the images feature gaze target labels.
- Bottom Line – For teams that are looking for datasets for application in the space of MR/VR headsets, this dataset can be a great fit. The similarity to real-world applications is a crucial factor that can make this an effective training dataset.

- Affiliation – Technical University of Ostrava, Media Research Lab
- Publication – ISVC
- Released – 2018
- Description – This dataset was captured using near-infrared cameras, in order to create a dataset with images that would best train a model tasked with recognizing the eyes of the user in a dark car at night.
- Main Use – The main use of this dataset is eye detection and pupil localizations, especially for the use cases of recognition of driver behavior. Namely, fatigue, drowsiness, gaze direction, and blinking frequency.
- Number of Images – 85,000.
- Subjects – 37
- Annotations – This dataset features relatively simple annotations. The images are classified into different categories but don’t have bounding boxes or segmentation.
- Bottom Line – The MRL dataset was designed with a specific use case in mind, and provides a good solution to it. A drawback to the dataset is the low level of sophistication of the annotations.
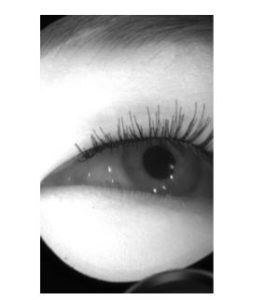
- Affiliation – Facebook Research Labs, University College London.
- Released – 2019
- Description – OpenEDS is a large-scale dataset of eye-images captured using a VR headset mounted with two eye-facing cameras. The dataset frames are compiled from video capture. The dataset is divided into four subsets.
- i. “12,759 images with pixel-level annotations for key eye-regions”
- ii. “252,690 unlabelled eye-images”
- iii. “91,200 frames from a randomly selected video sequence of 1.5 seconds in duration.”
- iv. “43 pairs of left and right point cloud data compiled from corneal topography of eye regions”
- Main Use – The main use of this dataset is VR and MR headsets, specifically to enable foveated rendering.
- Number of Images – 356,649
- Subjects – 152
- Annotations – The subset that is annotated features very detailed annotations, that were achieved using human annotators.
- Bottom Line – This dataset is a great option for teams looking for a dataset with highly detailed annotations of the different parts of the eye. One drawback of the dataset is that it doesn’t offer a very high level of variance, as all the images were collected in the same lighting condition.
Watch On-Demand “Implementing Data-Centric AI Methodology” with Microsoft and Meta
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
