
























Synthetic and Real-World Data in Facial Landmark Detection Models

Can synthetic data lead to better performance on the computer vision task of facial landmark detection?
This is the main question we set out to answer in our new research paper, Facial Landmark Detection Using Synthetic Data.
Not only is synthetic data privacy-preserving, it is also much more scalable than real-world data. Synthetic data technology has made quantum leaps in recent years, allowing ever more realistic images to be created.
That’s why we decided to experiment with combining synthetic data (created with the Datagen Platform) with real-world data in training a facial landmark detection model. We began with the hypothesis that a facial landmark detection model trained on a combined real and synthetic dataset will outperform one trained solely on real data.
This experiment revealed that synthetic data is valuable in model training. In particular, we discovered:
- A model trained on synthetic data has comparable results to that trained on real data when tested on real images.
- A model trained on synthetic data and fine-tuned with 50 real images is as good as a model trained with more than 250 real images.
In this post, we document the datasets used and domain gaps. Part two will talk about combining real and synthetic data and the last part will share our conclusions and results.
Datasets Used
To run this experiment, we curated both synthetic and real datasets, described in Table 1 below.
Table 1: Datasets used
| Type | Name | Number of images | Purpose |
| Synthetic Dataset | DGFaces (Figure 1) | 10k labeled images | Training set |
| Microsoft Dataset | 100k labeled images (Only 10k is used in this experiment) | Training set | |
| Real dataset | 300-W Train (Figure 2) | 6296 labeled images | Training and validation set |
| 300-W Common (Figure 3) | 1108 labeled images | Test set only |

Figure 1: Datagen Faces
|
|
|
| Figure 2: Sampled images from 300-W Train that are used in the validation set | Figure 3: Sampled images from 300-W Common that are used in the test set |


Though synthetic data mimics real-world data closely, there are subtle differences between them. Such inevitable differences are known as domain gaps.

Read the full Facial Landmarks Localization Using Synthetic Data Paper
Domain Gaps
Domain gaps arise because of the difference in the ways the data is generated, processed, and labeled. Here, we describe our method to address the visual and label domain gaps in this experiment.
The visual domain gap
Real-world and synthetic data might look different to a human and a computer. One source of the visual gap is the way the photo is processed. The way photos are cropped might differ between real-world and synthetic datasets. The general image size might also differ.
To minimize this, we imitate the way the real data is cropping the images. In particular, before the cropping was done, there were areas of low coverage in the train distribution (DGFaces) with respect to the target distribution (300-W Train) (Figure 4a). After adequate pre-processing, proper coverage is achieved.
|
|
|
| Figure 4a. Distribution of image width and height before cropping | Figure 4b. Distribution of image width and height after cropping |
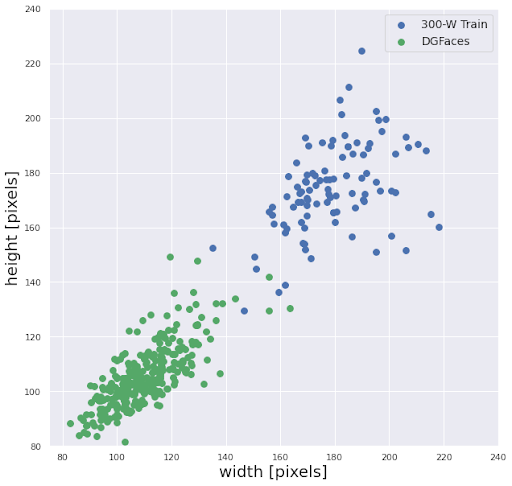
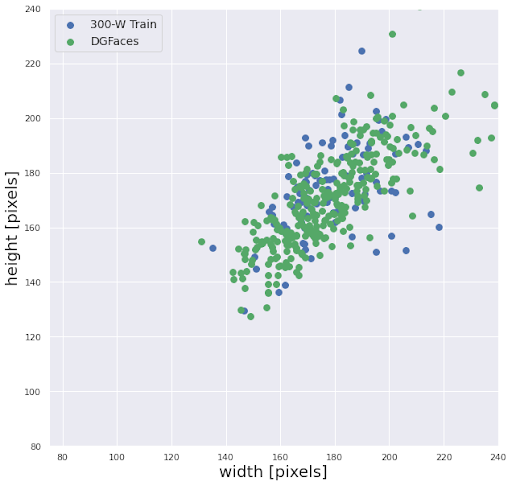
Another source of the visual domain gap is the way the photo is produced. For instance, the camera positions of a real-world dataset might be more limited than that of a synthetic dataset. Also, real-world images tainted by blurriness and occlusions, differ in quality with picture-perfect synthetic faces.
Thus, these synthetic faces must undergo the process of data adaptation. In other words, they are augmented to include noise (like shadows, fog, snow, blurriness) and to imitate the perspectives of the real-world images.
The label domain gap
Not only does synthetic data have to look the same as real-world data, but it also has to be labeled in the same way. Here, labels refer to the way the facial landmarks are marked.
The synthetic datasets used in this experiment are in 3D, while the real-world datasets used for comparison (300-W) are 2D.
The label domain gap arises due to the difference between labels in 2D and 3D views (Figure 5). Generally, the facial landmarks of real-world 2D images are labeled by human annotators, while those of 3D images are generated automatically.
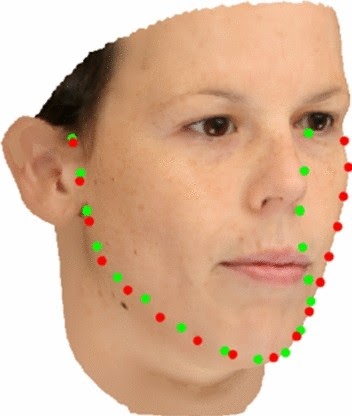
Figure 5: Landmark annotation on face contour differs between 2D (red annotation) and 3D views (green annotation)
Read the full Facial Landmarks Localization Using Synthetic Data Paper
The ambiguous boundaries of our facial features are a source of inconsistency in the manual labeling process. Imagine asking a group of labelers to point out the exact boundary between your nose and your forehead. Chances are that the labels will not be completely consistent. Conversely, the labels in the 3D images are generated automatically, making them much more consistent.
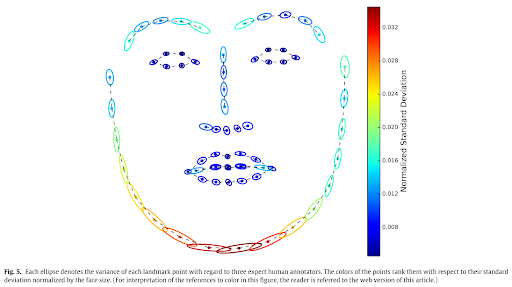
Figure 6: Ambiguity in the way a face is labeled is apparent in the high standard deviation of labels
Bridging such a gap is not trivial. The naive approach to overcome the label domain gap is to manually label the synthetic data.
A more effective approach is to automatically translate synthetic to real-world landmark labels which we will discuss in the next blog. We will also discuss the different strategies we used to test our hypothesis that “a landmark detection model trained on a combined real and synthetic data set will outperform one trained solely on real data”.
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
