
























Synthetic Data and Facial Landmark Detection

Can synthetic data lead to better performance on the computer vision task of facial landmark detection?
In our first two blogs here and here, we learned about our experiment with combining synthetic data (created with the Datagen platform) with real-world data in training a facial landmark detection model.
In our first blog, we discussed domain gaps and laid the groundwork to proceed with our experiment. Next, we discussed the hypothesis that “a landmark detection model trained on a combined real and synthetic data set will outperform one trained solely on real data”. To test that, we adopted a truly data-centric approach. Using fixed landmark detection model architecture, we experimented with five strategies of training the model; two of which (mixing and fine-tuning) involve combining real and synthetic datasets as seen in Table 1, below.
| Type | Name | Number of images | Purpose |
| Synthetic Dataset | DGFaces (Figure 1) | 10k labeled images | Training set |
| Microsoft Dataset | 100k labeled images (Only 10k is used in this experiment) | Training set | |
| Real dataset | 300-W Train (Figure 2) | 6296 labeled images | Training and validation set |
| 300-W Common (Figure 3) | 1108 labeled images | Test set only |
Table 1: Datasets used

Figure 1
|
|
|
|
Figure 2: Sampled images from 300-W Train that are used in the validation set |
Figure 3: Sampled images from 300-W Common that are used in the test set. |


Read the full white paper: Facial Landmark Detection Using Synthetic Data
To compare the strategies we used fairly, we had to ensure that the label adaptation model performs reasonably well. First, we trained a model with synthetic data only. Then, we used model label adaptation to overcome the label gap. The performance of models using model label adaptation is shown in Table 2.
| Train Dataset | Amount of data points used | Pipeline implemented by | Error [NME] ↓ |
| DGFaces | 10k | Datagen | 3.93 |
| Microsoft | 10k | Datagen | 3.63 |
| Microsoft | 100k | MS[1] | 3.09 |
| 300-W Train | 6296 | Datagen | 3.32 |
| 300-W Train | 6296 | MS[1] | 3.37 |
Table 2: The performance of models using model label adaptation
Comparing the 5 Strategies
Here, we compare the performance of these five strategies with different amounts of real data Nreal. (Figure 4)
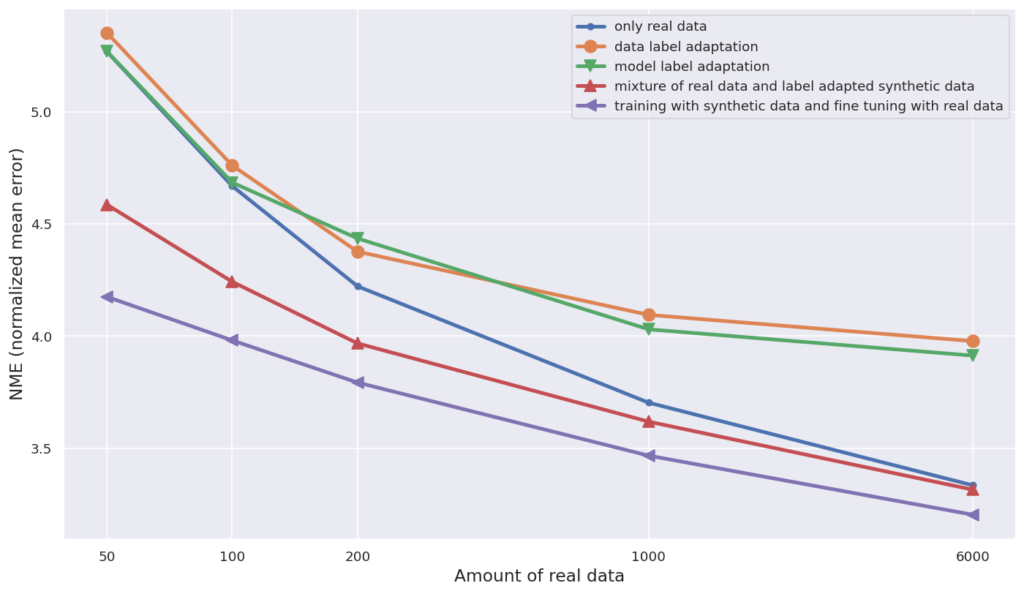
Figure 4
We can extract three insights from Figure 4.
The model “fine-tuned” with 50 real images has approximately the same performance as the “real-data-only” model with 250 real images. This shows that the use of synthetic data reduces the amount of real data needed. (Figure 4A)
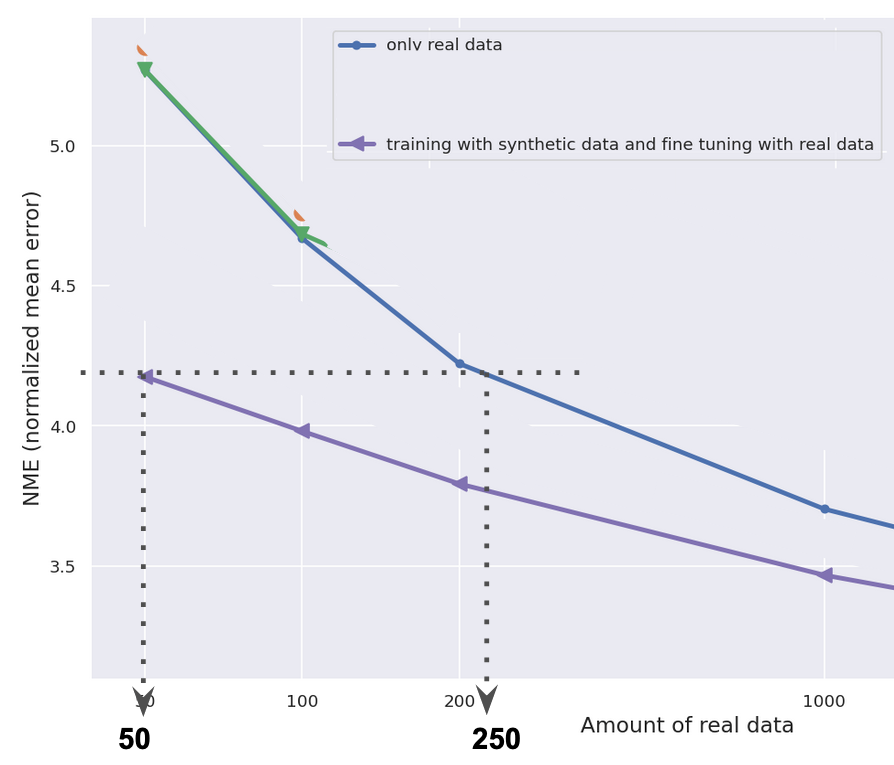
Figure 4A
The models trained on the combination dataset outperform those trained solely on real data alone. This demonstrates the value of combining real-world and synthetic data in landmark detection model training. (Figure 4B)
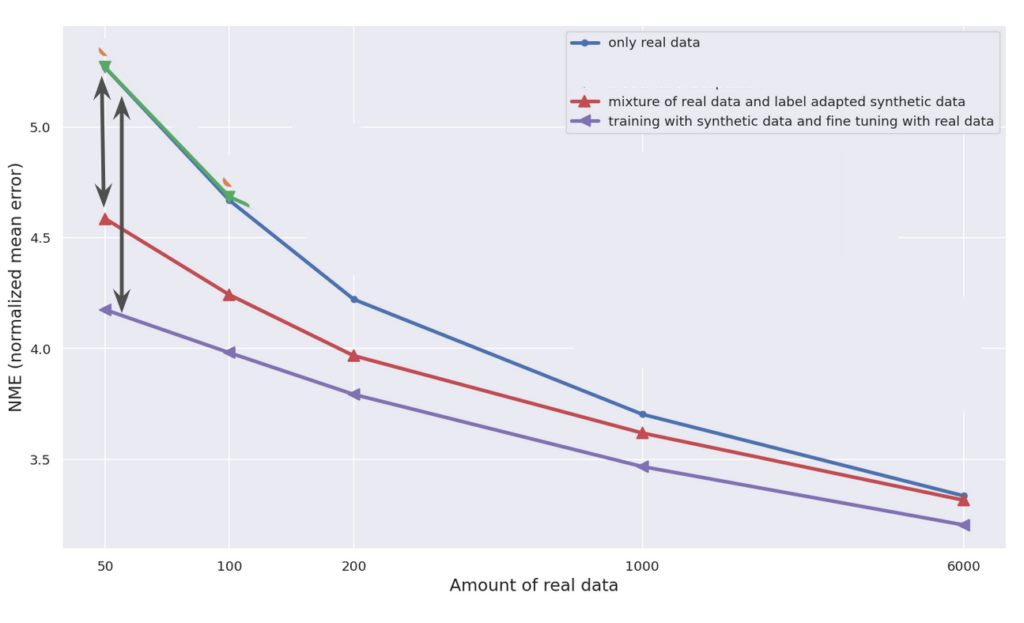
Figure 4B
The performance gap between the “real-world-only” model and the “fine-tuning” model is the largest when the amount of real data is small. This indicates that the value of synthetic data is potentially the largest when real data is limited. (Figure 4C)
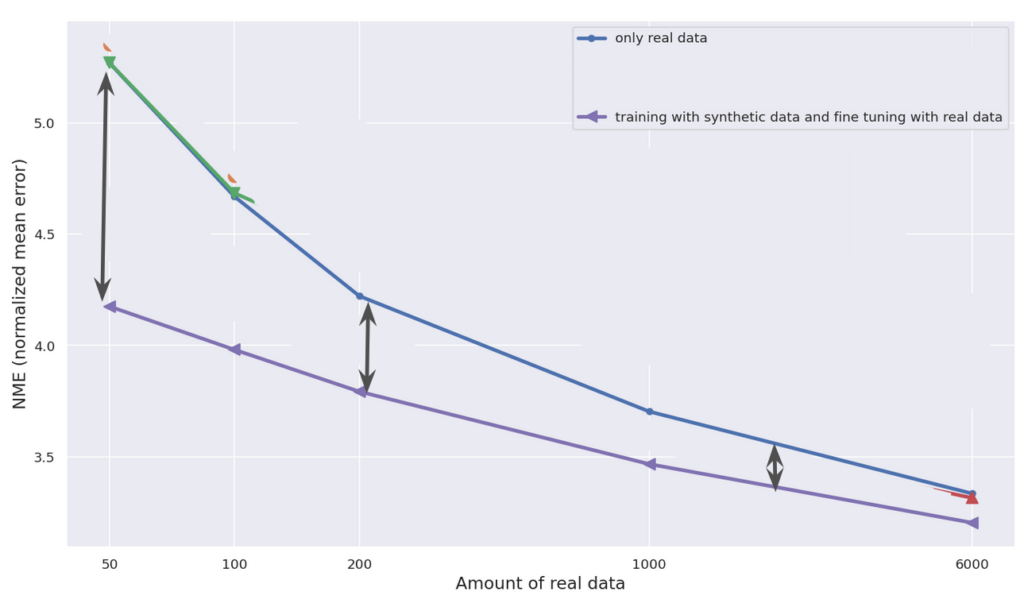
Figure 4C
Conclusion
Synthetic data has the potential to drastically improve computer vision tasks. Yet, the hurdle of visual and label domain gaps fly in the face of such potential. Fortunately, these can be easily overcome with label adaptation and data augmentation.
Having overcome such domain gaps, we find that combining synthetic and real-world data outperforms the strategy of using real data alone. We also learned that fine-tuning is the optimal strategy for creating the best landmark detection with real and synthetic data.
In the future, we are excited to replicate this experiment on other computer vision tasks. We also have plans to explore more methods of improving the landmark detection benchmark. Stay tuned!
Read the full white paper: Facial Landmark Detection Using Synthetic Data
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
