
























Real and Synthetic Data for Facial Landmark Detection

In part 1 of this series, we discussed domain gaps and laid the groundwork to proceed with our experiment.
This experiment hypothesizes that “a landmark detection model trained on a combined real and synthetic data set will outperform one trained solely on real data”.
To test that, we adopted a truly data-centric approach. Using fixed landmark detection model architecture, we experimented with five strategies of training the model; two of which (mixing and fine-tuning) involve combining real and synthetic datasets, as described below.
Strategy 1: Training the model on real data only
A face-to-landmark model is trained only on real data.
Strategy 2: Model with label adaptation
In this strategy, the face-to-landmark model is trained on synthetic data. The labels are then adapted after training.
Strategy 3: Model with data adaptation
For the synthetic data, a label adaption model (trained on real data) converts synthetic data labels to adapted labels. A face-to-landmark model is trained using only synthetic data and the trained face-to-landmark model predicts the label of real data. This strategy trains a face-to-landmark model on label-adapted synthetic data.
Read the Facial Landmark Detection Using Synthetic Data Whitepaper
Strategy 4: Mixing (Training on combined real-world and label-adapted synthetic data)
In the first setup, a combined dataset is used to train the model.
We first select Nsynthetic images from the Datagen synthetic dataset, which passes through the trained label adaptation model.
The resulting label-adapted synthetic images are combined with Nreal images from the real dataset in the set ratio of α, where α is the batch synthetic sampling ratio.
This combined dataset is then used to train a face-to-landmark model. The predicted labels are then compared against the ground truth labels.
Strategy 5: Fine-tuning (Training on synthetic, fine-tuning on real data)
In this strategy, the model is first trained purely on the DGFaces synthetic dataset and then fine-tuned on real data.
Experimental Design
Metric
The performance of each model is judged based on the normalized mean error (NME). To calculate NME, one would find the (normalized) distance between the ground-truth and predicted labels for each facial feature. These distances are summed up to give the NME.
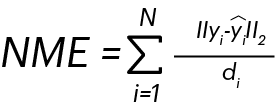
Validation and test sets
The same real validation and test sets are used to compare each model. A 300-image subset of the 300-W Train dataset is used as the validation set, while the 300-W Common dataset is the test set.
In our next blog, we will talk about the results of the experiment.

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
