
























Top 7 Image Datasets for Object Detection

What Is Object Detection?
Object recognition is a task in computer vision that involves identifying and detecting objects in images or videos. It involves the use of algorithms and machine learning techniques to analyze and interpret visual data and identify specific objects or patterns within that data. Object recognition systems are used in a wide range of applications, including image and video analysis, robotics, and autonomous vehicles.
Typically, training object detection models requires massive datasets, with images of objects similar to those the model is expected to detect. We’ll explain the importance of object detection datasets and cover some of the most common datasets used in modern object detection projects.
This is part of a series of articles about image datasets.
In This Article
Why Are Image Datasets Needed for Object Detection?
An image dataset is a collection of images that is used to train and test machine learning models. Machine learning models are designed to learn from data and make predictions or decisions based on that data. In order to improve the accuracy and performance of these models, it is important to provide them with a diverse and representative dataset.
Image datasets are particularly useful for training machine learning models for tasks such as image classification, object detection, and object recognition. These datasets typically consist of a large number of images, each labeled with the objects or categories they contain. The machine learning model is then trained on this data, using it to learn the features and patterns that are associated with each object or category.
Image datasets can be labeled or unlabeled. Labeled image datasets include images that have been annotated or labeled with the objects or categories they contain, while unlabeled image datasets do not include any annotations or labels. Labeled image datasets are typically used to train machine learning models, while unlabeled image datasets may require additional processing and annotation in order to be useful for machine learning.
Top 7 Image Datasets for Object Detection
1. ImageNet
Official page: https://www.image-net.org/
ImageNet is a large dataset of labeled images that is commonly used for training and evaluating machine learning models, particularly in the field of computer vision. The dataset was developed by researchers at Stanford University.
ImageNet consists of more than 14 million images that have been labeled with one of more than 20,000 different object categories. The images in the dataset are taken from a variety of sources, including the Internet, and cover a wide range of objects and categories.
ImageNet has become a popular dataset for training and evaluating machine learning models because it is large, diverse, and well-labeled. It has been used to train and evaluate many state-of-the-art machine learning models and has played a significant role in the advancement of the field of computer vision.
2. COCO (Microsoft Common Objects in Context)
Official page: https://cocodataset.org/#home
COCO, or Microsoft Common Objects in Context, is a large-scale dataset of images and annotations that is commonly used for training and evaluating machine learning models in the field of computer vision. The dataset was developed by Microsoft and consists of over 200,000 labeled images with over 1.5 million objects along with a variety of other types of annotations, such as captions, keypoints, and segmentation masks.
COCO is organized into 80 categories of objects and 91 stuff categories, including people, animals, vehicles, and everyday objects. The images in the dataset come from a variety of sources and depict a wide range of scenes and contexts. COCO is commonly used to train and test machine learning models for tasks such as object detection and image classification.

3. Visual Genome
Official page: https://visualgenome.org/
The Visual Genome is a large image dataset based on MS COCO containing over 100,000 annotated images. In addition to being a standard benchmark for object detection, it is particularly suitable for scene description and question answering tasks.
The Visual Genome aims to go beyond object annotations to answer questions and explain relationships between all objects. It provides ground truth annotations with over 1.7 million question-answer pairs (an average of 17 questions per image). The questions are evenly divided between “what”, “where”, “when”, “who”, “why” and “how”.
3. DOTA
Official page: https://captain-whu.github.io/DOTA/dataset.html
DOTA (Dataset for Object Detection in Aerial Images) is a large-scale dataset used for object detection in aerial images. It was introduced in a 2018 CVPR paper (Xia et al., 2018).
The DOTA dataset was created to address the challenges of object detection in aerial images, which are often taken from high altitudes and can have large variations in scale, orientation, and viewpoint. The dataset contains over 2800 annotated images, with a total of 188,282 instances of 15 object categories, including ships, planes, harbors, and vehicles. The images were collected from Google Earth and cover a diverse range of geographical locations, including urban, suburban, and rural areas.
The DOTA dataset has been widely used in research on object detection in aerial images and has contributed to the development of new object detection algorithms and systems. It has also been used as a benchmark for evaluating the performance of different object detection approaches.

4. KITTI Vision Benchmark Suite
Official page: https://www.cvlibs.net/datasets/kitti/
The KITTI Vision Benchmark Suite is a set of benchmarks for evaluating the performance of computer vision algorithms on tasks such as object detection, image classification, and visual odometry. The benchmarks are based on real-world data collected from a suite of sensors mounted on a car, including a camera, a lidar, and an inertial measurement unit (IMU).
The KITTI Vision Benchmark Suite was developed at the Karlsruhe Institute of Technology (KIT) and was first introduced in a 2012 paper published in the journal IEEE Intelligent Transportation Systems Magazine. It has since become a widely used benchmark for evaluating the performance of computer vision algorithms in the field of autonomous driving and has been used in many research studies.
The KITTI Vision Benchmark Suite includes a number of different datasets, each focused on a specific task or set of tasks. For example, the KITTI Object Detection Benchmark contains 15,000 images with annotated objects, including cars, pedestrians, and traffic signs.
5. nuScenes
Official page: https://www.nuscenes.org/
nuScenes is a large-scale dataset for autonomous driving research, developed by the nuTonomy team at MIT (now called Motional). It was introduced in a CVPR paper (Caesar et al., 2020).
The nuScenes dataset consists of 1,000 scenes of data collected from a fleet of autonomous vehicles in Boston and Singapore. Each scene includes data from a variety of sensors, including lidar, radar, and high-resolution cameras, as well as synchronized GPS and IMU measurements. The dataset also includes detailed annotations for objects in the scenes, including their 3D bounding boxes, attributes, and behaviors.
The nuScenes dataset is designed to support a wide range of research tasks in autonomous driving, including object detection, tracking, and prediction. It has been widely used in research on autonomous vehicle perception and control, and has been used as a benchmark for evaluating the performance of different algorithms and systems.

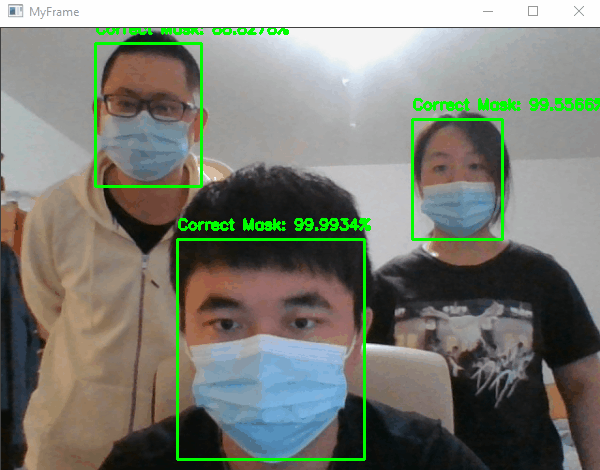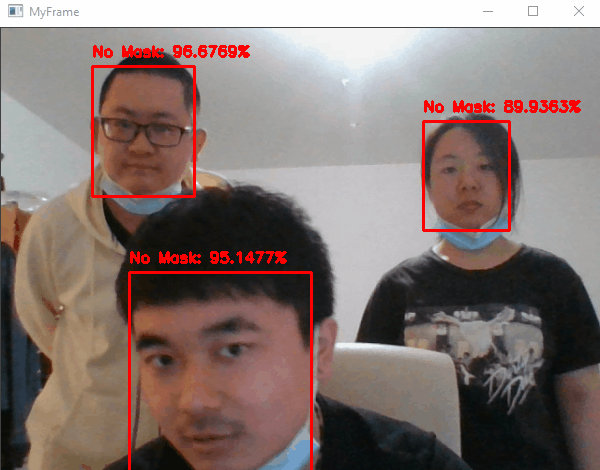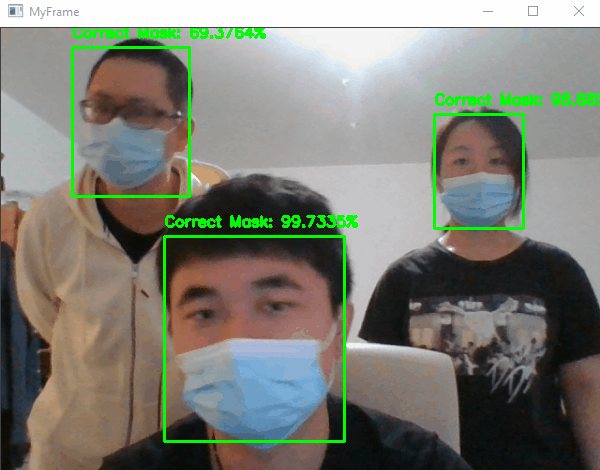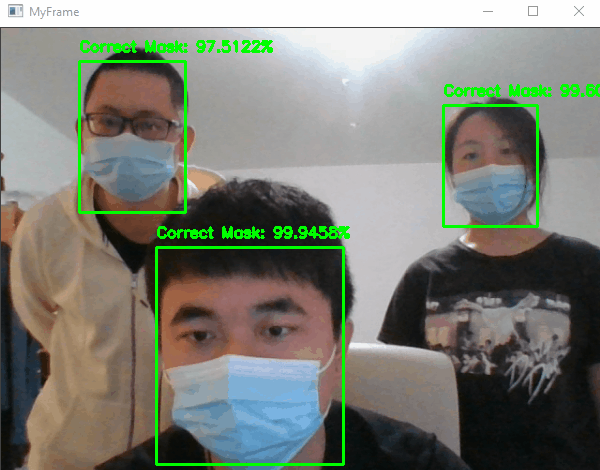
6. MaskedFaceNet
Official page: https://github.com/cabani/MaskedFace-Net
MaskedFaceNet is a convolutional neural network (CNN) designed for facial recognition with masks. It was introduced in a paper published by the Computer Vision Foundation (Prasad, et al., 2021).
Facial recognition with masks is a challenging task because masks can significantly alter the appearance of the face and make it difficult for traditional facial recognition algorithms to accurately identify individuals. MaskedFaceNet was developed to address this problem by learning to recognize faces with masks using a dataset of annotated images of people wearing masks.
The MaskedFaceNet model is based on the MobileNetV2 architecture, a lightweight CNN that is well-suited for use in resource-constrained environments. It was trained on a dataset of over 100,000 images of people wearing masks, and was able to achieve high accuracy on a variety of facial recognition tasks, including identification and verification.
7. Waymo
Link: https://paperswithcode.com/dataset/waymo-open-dataset
The Waymo Open Dataset is a large-scale dataset for autonomous driving research, developed by Waymo, the self-driving technology company. It was introduced in the 2022 paper “Waymo Open Dataset: Panoramic Video Panoptic Segmentation.”
The Waymo Open Dataset is designed to support a wide range of research tasks in autonomous driving, including object detection, tracking, and prediction, as well as tasks related to perception, localization, and planning.
It consists of a diverse set of data collected from Waymo’s autonomous vehicle fleet, including lidar scans, camera images, and high-precision GPS and IMU measurements. The dataset also includes detailed annotations for objects in the scenes, including their 3D bounding boxes, attributes, and behaviors.

Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
