
























7 Image Datasets for Classification and How to Build Your Own

What Are Image Datasets?
Image classification is a computer vision task aimed at understanding the main subject of an image and classifying it into one of several classes or categories. Image classification is applied to images with only one object, as opposed to object detection which is tasked with identifying multiple objects within a single image.
Image classification algorithms are trained and tested using image datasets. These are collections of example images similar to those the algorithm will encounter in real life. Supervised models are trained and tested using labeled image datasets—these labels provide the “ground truth” the algorithm can learn from. Unsupervised models can be trained with unlabeled datasets.
One use of image dataset is for training image classification models. A dataset is typically split into training and testing sets. For example, 70% of the images can be used to initially train the algorithm (the training set), and the remaining 30% can be used as unseen examples to test the algorithm’s performance (the testing set).
Another common use of image datasets is as a benchmark for computer vision algorithms. Applying multiple algorithms to the same dataset can be an effective way to compare their performance for a given task.
In This Article
Image Datasets for Image Classification
Below are a few examples of popular image datasets. However, they are not “one size fits all”. You’ll need to carefully evaluate if each dataset provides the specific images you need for training. If not, you’ll have to look for other datasets or in some cases, build your own.
1. ImageNet
ImageNet is an annotated image dataset based on the WordNet hierarchy. The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) has used this dataset since 2010 as a benchmark for image classification. The publicly available dataset includes an annotated training set and an unannotated test set.
There are two types of annotations in ILSVRC:
- Image-level annotations provide binary labels to indicate the absence or presence of a given object class within an image. For example, “there are boats in this image” or “there are no cars.”
- Object-level annotations provide tight bounding boxes and class labels around object instances in an image. For example, “there is a car at the coordinate (20,25) with a width of 100 pixels and height of 40 pixels.”
ImageNet doesn’t own the image copyright, so it only provides URLs and thumbnails of the images.
Dataset details:
- 14,197,122 images
- 21,841 WordNet synonym sets (also known as synsets). A synset is a phrase that describes a meaningful concept in ImageNet.
- 1,034,908 annotated images with bounding boxes
- 1000 synsets with scale-invariant feature transform (SIFT) features
- 1.2 million images with SIFT features

Source: https://cs.stanford.edu/people/karpathy/cnnembed/
2. CIFAR-10
The Canadian Institute for Advanced Research (CIFAR-10) dataset is a collection of training images for computer vision projects.
The most popular application is to train computer models to recognize object classes. The low resolution of CIFAR-10 images makes them useful for quickly testing algorithms. This dataset includes 60,000 color images distributed evenly across 10 classes, including:
- Airplanes
- Cars
- Trucks
- Ships
- Birds
- Cats
- Dogs
- Deer
- Frogs
- Horses
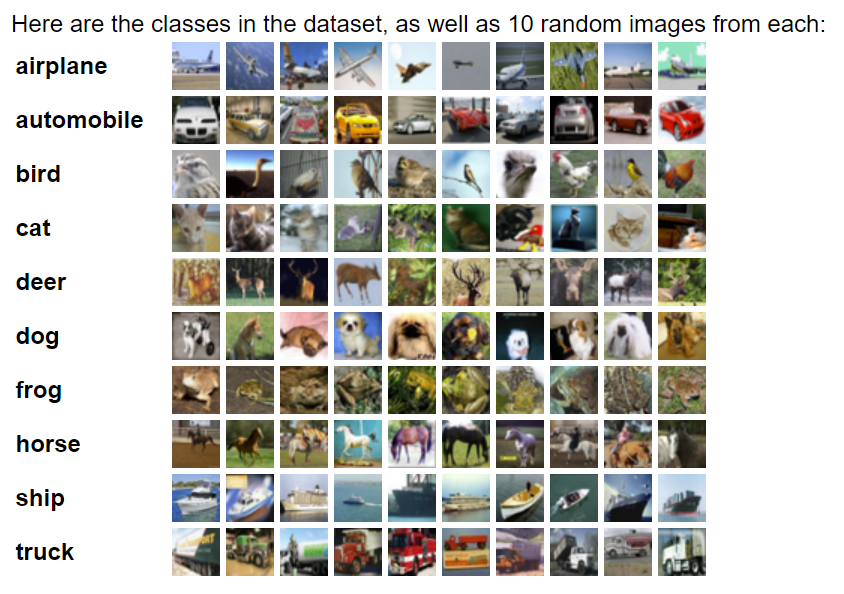
Source: https://www.cs.toronto.edu/~kriz/cifar.html
3. ObjectNet
The ObjectNet dataset contains test set images collected via crowd-sourcing. This image set is unique because it includes objects captured in unusual positions in realistic, complex scenes. These cluttered conditions severely impact the performance of object recognition algorithms. That makes it ideal for testing the robustness of an algorithm trained with transfer learning.
ObjectNet differs from ImageNet and CIFAR-100 because it is not a training dataset – it is solely for testing computer vision systems.
Dataset details:
- 50,000 test images with rotation, viewpoint, and background controls
- 313 different object classes (113 of which classes overlap with ImageNet)

Source: https://objectnet.dev/
4. MIT Indoor Scenes
This is a raw dataset provided by MIT, built to address the challenge of machine perception of indoor scenes. Most scene recognition models that perform well in outdoor scenes do not perform well indoors. That is because scene recognition models have a difficult time recognizing indoor scenes that are characterized by specific objects (like a bookstore with its characteristic bookshelves and books).
Dataset details:
- 15,620 images
- 67 indoor scene categories
- At least 100 JPEG images per category

Source: https://web.mit.edu/torralba/www/indoor.html
5. Scene Understanding (SUN) Database
Provided by Princeton University, this dataset was used to develop the Scene Categorization benchmark.
Dataset details:
- 108,753 images, divided into
- 76,128 training images
- 10,875 validation images
- 21,750 test images
- 397 categories
- At least 100 JPEG images per category
- At most 120,000 pixels per image

Source: https://vision.princeton.edu/projects/2010/SUN/
6. Architectural Heritage Elements (AHE)
The AHE dataset can be used to develop computer vision algorithms for classification of architectural images. Like CIFAR-10, AHE features 10 categories, including
- 829 altar images
- 514 apse images
- 1059 bell tower images
- 1919 column images
- 1793 dome images
- 407 flying buttress images
- 1571 Gargoyle images
- 1033 stained glass images
- 1100 vault images

Source: https://www.researchgate.net/figure/Dataset-samples-of-Cultural-Heritage-images-used_tbl1_320052364
7. Intel Image Classification
This image data set focuses on natural scenes. It was created by Intel for an image classification competition.
Dataset details:
- Approximately 25,000 images
- Images are grouped into categories such as buildings, forests, glaciers, mountains, seas, and streets.
- Dataset is divided into folders for training, testing, and prediction:
- 14,000 training images
- 3,000 validation images
- 7,000 test images

Source: https://www.kaggle.com/datasets/puneet6060/intel-image-classification/code
How to Build a Dataset for Image Classification
How to Design Classes and Labels
In order to build an image classification dataset, you must first have a set of labels that reflects the goals of your computer vision project. There are at least four key aspects to consider:
- Number of labels—this should always be greater than 1. The simplest case is to detect which out of a set of objects exists in the image. More complex cases can include hundreds of labels—for example, the ImageNet dataset has 1,000 classes of day to day objects.
- Granularity within labels—some classifiers perform rough distinctions, for example identifying vehicles and pedestrians. Others can make very fine decisions, for example identifying a specific model of a car. The level of granularity must be reflected in the label structure.
- Detection criteria—determine under what conditions the algorithm will be required to classify the object. For example, if the algorithm classifies cars, will it be required to classify a car even if it is occluded (hidden by other objects), in different poses, or under different lighting conditions?
- Definition of labels–in order to ensure the consistency of the labels across all images, it is useful to clearly define labels with specific criteria, especially for ambiguous cases.
Designing labels according to these considerations will ensure you have the appropriate labels, and the right examples, to properly train and test the algorithm.
Related content: Read our guide to image labeling
How Much Data Do You Need?
In general, the more images in your dataset, the better your model will perform. However, there are several important considerations that will affect data size and quality:
- A common rule of thumb is to have at least training 100 images per class, but many algorithms will require much more than this to be effective.
- A dataset should ideally have a balanced number of images across classes.
- Most datasets are split into training, validation, and testing images. A common ratio is 80/10/10 or 60/20/20.
Is Your Image Dataset Diverse Enough?
As you increase the number of labels and their granularity, your dataset will need to be more diverse. The dataset should contain all object classes that the algorithm needs to recognize.
Beyond this, you must take into account the diversity of the same object in real-life settings. For example, the same car in different settings, with different colors, under different lighting conditions, etc. might appear different to an algorithm. The dataset must take these different settings into account.
A dataset that is not sufficiently diverse will be biased in favor of the settings or conditions represented by the examples it contains.
Get our free eBook
How to use synthetic data in 6 easy steps

Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
