
























Face Recognition: 7 Techniques and a Quick OpenCV Tutorial

In This Article
What Is Face Recognition?
Face recognition is a technology that uses machine learning algorithms to identify a person from a digital image or video frame. This is done by analyzing and comparing patterns in the image or video of the person’s face to a database of known faces. Face recognition can be used for a variety of applications, such as unlocking a smartphone or verifying a person’s identity for security purposes.
Face detection is the process of identifying and locating human faces in digital images or video. This is typically the first step in a face recognition system, as it allows the system to identify the region of the image or video that contains a face.
Once a face has been detected, the next step is to extract the relevant features from the face. This involves using algorithms to identify elements of the face such as the shape of the eyes, nose, and mouth. Modern face recognition systems use deep neural networks to extract features from face images and analyze them to compare an image to known faces.
How Does a Facial Recognition System Work?
Facial recognition systems work by identifying and analyzing the unique facial features of an individual in a digital image or video. This typically involves several steps:
- Face detection—a face detection algorithm is used to identify and locate human faces in an image or video. This allows the system to determine the region of the image that contains a face, and discard any other irrelevant information.
- Facial features—The system extracts relevant facial features from the detected face. This is known as feature extraction, and it typically involves identifying key facial landmarks, such as the eyes, nose, and mouth.
- Feature vector—the extracted features are then converted into a numerical representation, known as a feature vector, which can be compared with other face feature vectors in a database.
- Comparison—the feature vector is compared with a database of known faces to determine the identity of the individual in the image or video. This is typically done using a machine learning algorithm, such as a deep neural network, which has been trained on a large dataset of known faces. The algorithm outputs a confidence score, indicating how closely the input face matches the known faces in the database.
If, at the end of this process, the confidence score exceeds a certain threshold, the system will recognize the individual and confirm their identity.
Face Recognition Use Cases and Applications
This technology uses AI-powered apps to look for facial images that match an input image. Face recognition websites search through multiple databases to find similar faces, taking a faceprint and comparing it to other images. Use cases are wide-ranging, from unlocking smartphones to identifying identity theft and copyright violations.
Facial Analysis
This technology detects faces in images or videos and determines characteristics like age, gender, and emotion. Common facial analysis techniques include:
- Identifying facial features associated with different genders.
- Identifying markers that change with age.
- Identifying expressions that indicate different emotions.
Learn more in our detailed guide to face analysis
Emotion Detection
Emotion detection is the process of identifying and interpreting the emotions of an individual based on their facial expressions, body language, or other behaviors.
One approach to emotion detection involves analyzing the facial expressions of an individual to identify emotions such as happiness, sadness, anger, or fear. This can be done using techniques such as computer vision and machine learning, which can analyze the facial features and movements of an individual in real-time to detect emotions.
Facial Landmark Detection
One related computer vision task is to predict the key points representing landmarks on human faces, such as eyes, lips, and nose. It is often the basis for computer vision tasks like gaze estimation, head pose estimation, and face swapping.
Gaze Estimation
This task predicts the direction of an individual’s gaze based on 2D and 3D gaze vector estimates. The most common use case for 3D gaze estimation is improving safety in automotive settings. 2D gaze estimation predicts vertical and horizontal coordinates on 2D screens, usually to enable interaction between humans and machines.
Learn more in our detailed guide to gaze estimation
Face Recognition Techniques and Algorithms
1. Classical Face Detection
Traditional face detection methods are typically based on the analysis of low-level features in the images, such as edges, lines, and patterns.
Local and global feature-based methods are two approaches that are used to extract features from images. Local feature-based methods first evaluate the input image to segregate distinctive facial regions like the mouth, nose, eyes, etc., and identify the geometric relationships among these facial points. Global feature-based methods consider the entire face representation rather than individual components like mouth, eyes, and nose, etc.
Some examples of traditional face detection methods include:
- Elastic graph matching—this local approach uses graph theory to locate and identify faces in images. It involves constructing a graph representation of the image, and then using an algorithm to search for patterns in the graph that are characteristic of faces.
- Singular value decomposition (SVD)—this global approach is a mathematical technique used to decompose a matrix into a set of simpler matrices.
2. Artificial Neural Network
An artificial neural network (ANN) is a type of machine learning model composed of a network of interconnected nodes, or “neurons”, with weights that determine how information passes between these neurons. The network is trained by tuning these weights to the values that provide an optimal prediction or output.
A deep neural network is an ANN that contains multiple layers of neurons–as many as hundreds or thousands in some architectures. This can improve the network’s ability to handle complex cognitive tasks, and in particular can assist with feature extraction. Deep neural network approaches to face recognition include:
- DeepFace: A deep neural network that was developed by researchers at Facebook in 2014. It was one of the first deep learning models to achieve near-human level performance on the Labeled Faces in the Wild (LFW) dataset, which is a widely used benchmark for face recognition.
- DeepID: A series of deep neural networks developed by researchers at the Chinese University of Hong Kong. The DeepID models are known for their ability to learn highly discriminative features for face recognition.
- FaceNet: Developed by researchers at Google in 2015. It uses a combination of convolutional neural networks and siamese networks to map faces to a Euclidean space, where the distance between two points corresponds to the similarity between the faces they represent.
- SphereFace: SphereFace is a deep neural network that was developed by researchers in the US and China in 2017. It is designed to learn angularly discriminative features.
Deep neural networks are trained by finding parameters of the model that will minimize a loss function. A loss function is a mathematical function that is used to measure the difference between the predicted output of a model and the true output. In the context of face recognition, loss functions are used to measure the difference between the predicted identity of a face and the true identity. Researchers have developed new loss functions that are specifically tailored for face recognition tasks.
Examples include:
- Cosine loss: A loss function based on the cosine similarity between two vectors.
- Softmax loss: A loss function based on the softmax function, which is used to convert a set of values into a probability distribution.
- Euclidean loss: Based on the Euclidean distance between two vectors.
3. 3D Face Recognition
3D face recognition can be more accurate than 2D face recognition, because 3D facial images contain more information about the shape and characteristics of a person’s face, which allows the system to learn and recognize more complex features. 3D face recognition is also more robust to variations in pose and lighting.
However, the main challenge of 3D face recognition is the limited availability of 3D facial images. While there are many datasets of 2D facial images available for research and development, there are fewer datasets of 3D facial images, which can limit the scope of research in this area.
Face Datasets
There are multiple large-scale face datasets that can be used for face recognition research, including:
- VGGFace2: A large-scale face dataset that was developed by researchers at the University of Oxford. It contains over 3 million images of 9,000 individuals, and is widely used for face recognition research and development.
- Digi-Face 1M: the largest scale synthetic dataset for face recognition, free from privacy violations and lack of consent. Includes 1.2 million face images with 110,000 identities.
- WebFace260M: Developed by researchers at Tsinghua University in China. It contains over 260 million images of more than 8 million individuals.
These datasets are an important resource for the development of new and improved face recognition algorithms, and they play a crucial role in advancing the field of face recognition.
Quick Tutorial: Face Recognition in Python with OpenCV
Once you have detected the faces in the image, you can then perform face recognition to identify the individuals in the image.
There are several approaches to face recognition, including using machine learning algorithms such as support vector machines (SVMs) or deep neural networks (DNNs). To use these algorithms, you will need to train a model on a dataset of labeled images and then use the model to make predictions on new images.
Here is an example of how you might use an SVM model to perform face recognition in Python using OpenCV:
Note: If you experience an import error for the sklearn module, please install using the following command:
python -m pip install scikit-learnfrom sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.decomposition import PCA as RandomizedPCA
from sklearn.pipeline import make_pipeline
from sklearn.metrics import accuracy_score
faces = fetch_lfw_people(min_faces_per_person=100)
X = faces.data
y = faces.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# We will use RandomizedPCA to consider only most important features of the dataset.
pca = RandomizedPCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='rbf', class_weight='balanced')
# Let’s take advantage of pipelines that combines multiple steps together and helps to write a clear code
model = make_pipeline(pca, svc)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
# Let’s print out the Accuracy Score of our model
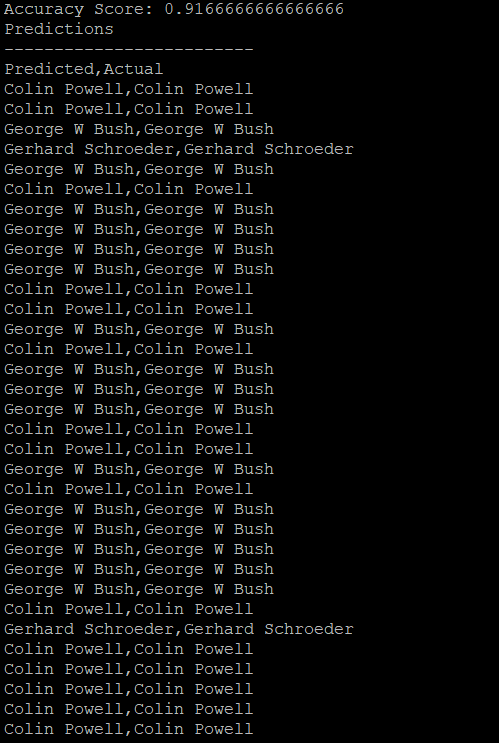
print( "Accuracy Score: " + str(accuracy_score(predictions, y_test)) )
# Let’s print out the values of Predicted vs Actual
print( "Predictions\n-------------------------")
print("Predicted,Actual")
for cnt in range(len(predictions)):
if predictions[cnt] == y_test[cnt]:
predicted = faces.target_names[predictions[predictions[cnt]]]
actual = faces.target_names[y_test[y_test[cnt]]]
print("%s,%s" % (str(predicted).strip(),str(actual).strip() ) )Here is what the output looks like:
See Our Additional Guides on Key Machine Learning Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of Machine learning.
Image Annotation
- Image Labeling in Computer Vision: A Practical Guide
- 5 Image Annotation Tools to Get Your Labeling Project Started
- Labelme: the Basics and a Quick Image Segmentation Tutorial
Image Datasets
- CelebA: Overview of Datasets and a VAE Tutorial
- Top 10 Face Datasets for Facial Recognition and Analysis
- LFW Dataset: Basic Usage and a Quick Tutorial
Synthetic Data
Read More

The State of Facial Recognition Today

Procedural Humans for Computer Vision
